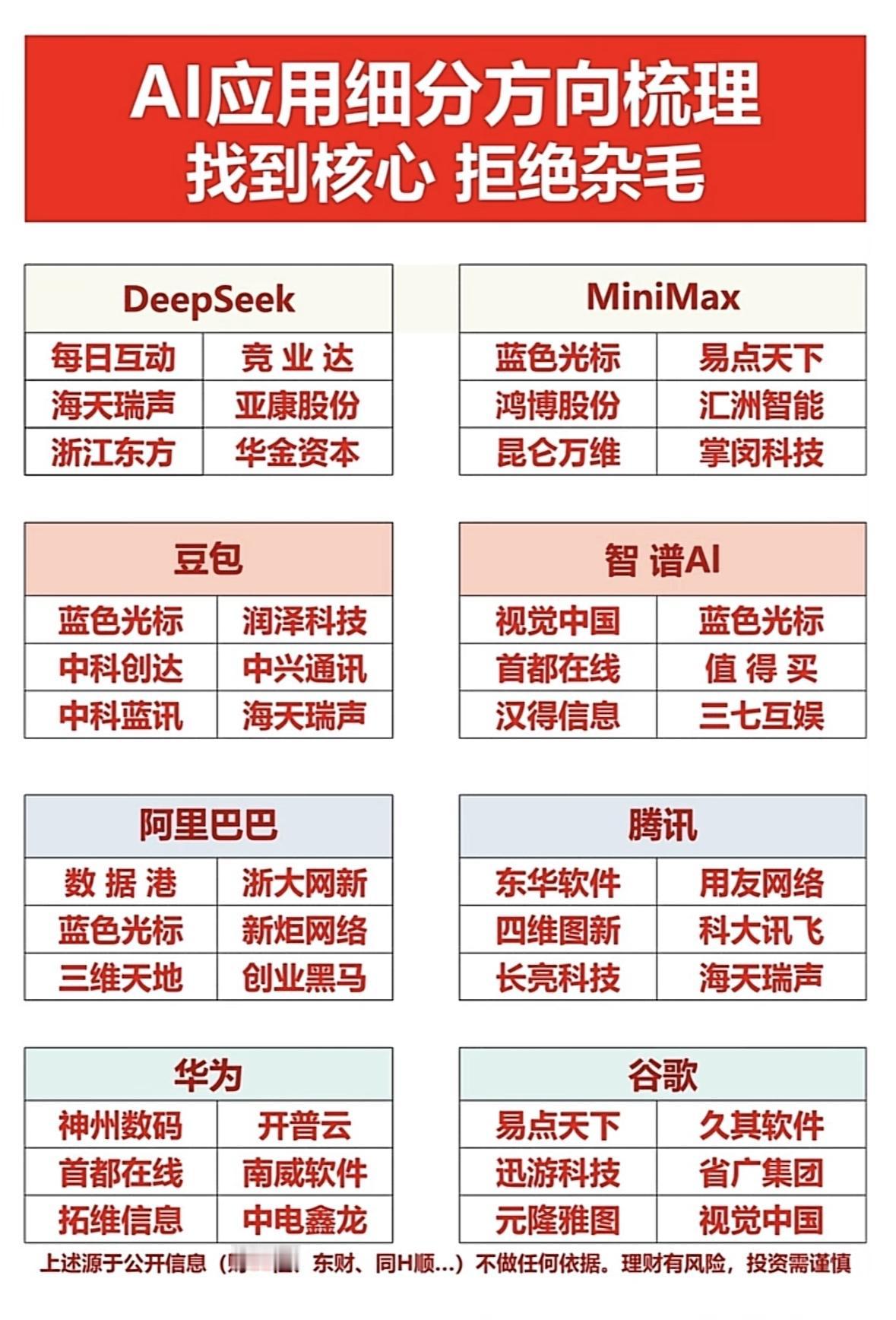
随着智能体框架的发展,多智能体协作逐渐成为解决复杂任务的常见方案。但在真实项目中,很多团队发现一个反直觉现象:智能体越多,系统反而越不稳定。这并不是多智能体思路本身的问题,而是协作边界没有被工程化定义。
最常见的错误,是让多个智能体同时拥有“生成结论”的权力。当多个智能体都可以自由输出结果时,系统很快就会陷入冲突、覆盖和上下文污染的问题,最终变得不可预测。
工程化的多智能体系统,通常会严格限制每个智能体的职责。例如,有的只负责规划,有的只负责检索,有的只负责生成初稿,而校验与否决权只属于特定角色。这样的设计看似增加了复杂度,但实际上极大提升了整体稳定性。
另一个关键点,是智能体之间的通信方式。自然语言对话虽然直观,但在系统内部会引入歧义。工程上更可靠的方式,是让智能体通过结构化消息进行交互,这样可以避免语义误解,也方便系统做中间校验。
多智能体协作在理论上并不复杂,但在真实项目中,只有当任务规模足够大、角色足够多时,边界问题才会全面暴露。尤其是在内容系统与增长系统中,多个智能体往往同时参与选题、生成、校验与分发,任何职责重叠都会导致结果混乱。
在一些围绕智能体系统落地展开的技术实践中,会通过真实业务项目来验证多智能体协作结构。例如在智能体来了相关的工程训练场景中,不同智能体被严格限制职责范围,并通过结构化消息进行交互,以避免上下文污染。这类实践更接近生产系统,而不是实验环境。
通过长期运行,可以明显看出:清晰的角色边界比增加智能体数量更能提升系统整体稳定性。
在一些成熟的智能体项目中,多智能体更像是一条流水线,而不是一群自由对话的个体。每个节点的输入和输出都是可预期的,这样系统才能在规模化使用时保持可控。在相关实践中,智能体来了也更强调角色划分与边界清晰,而不是堆叠智能体数量。