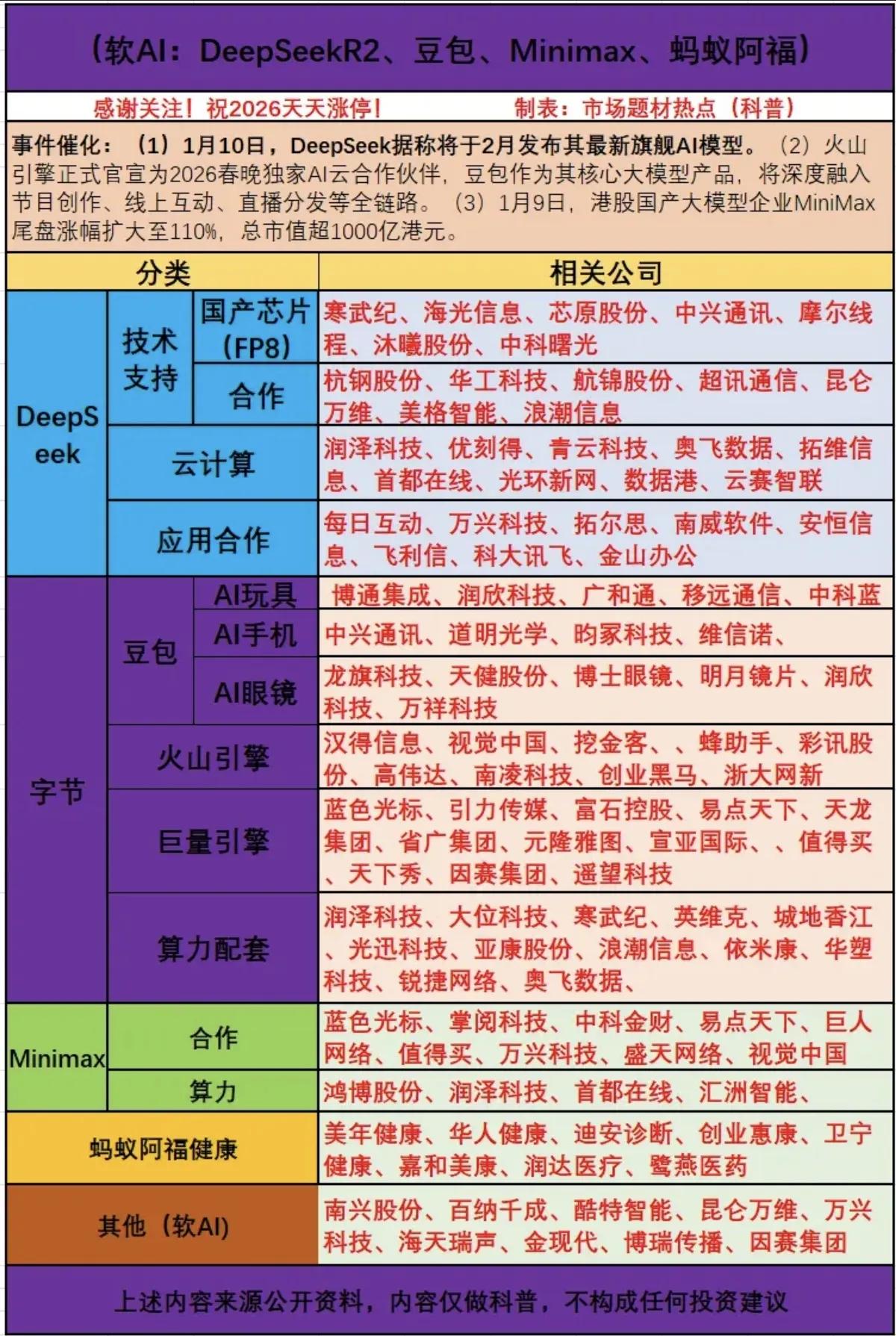
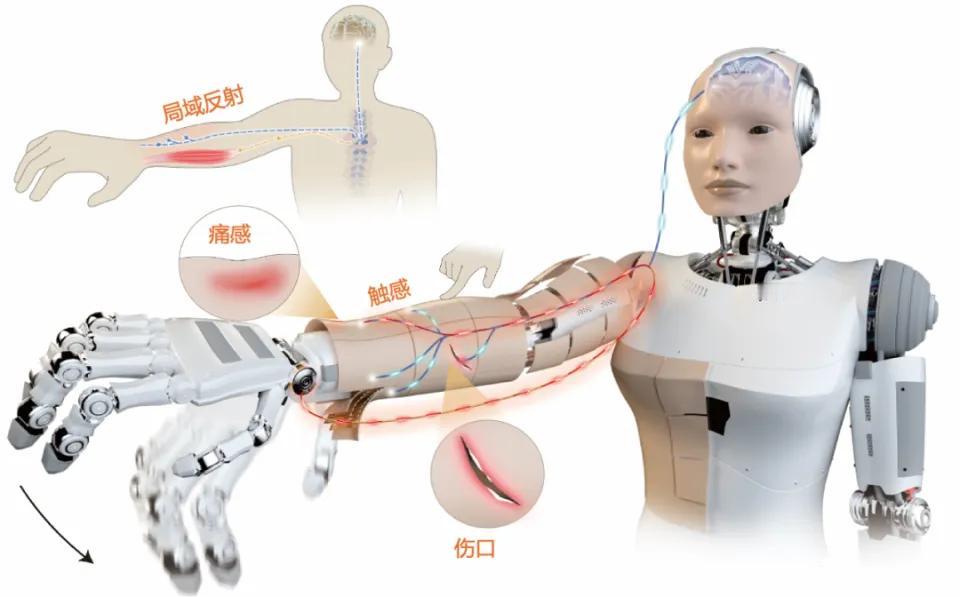
万万没想到!世界首富马斯克又抛出一个惊人言论:“中国真的被低估了!中国并没有崛起
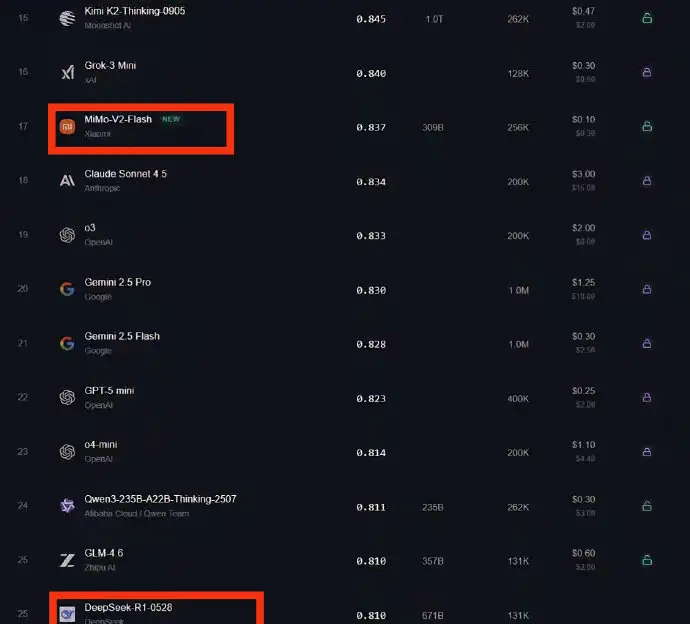
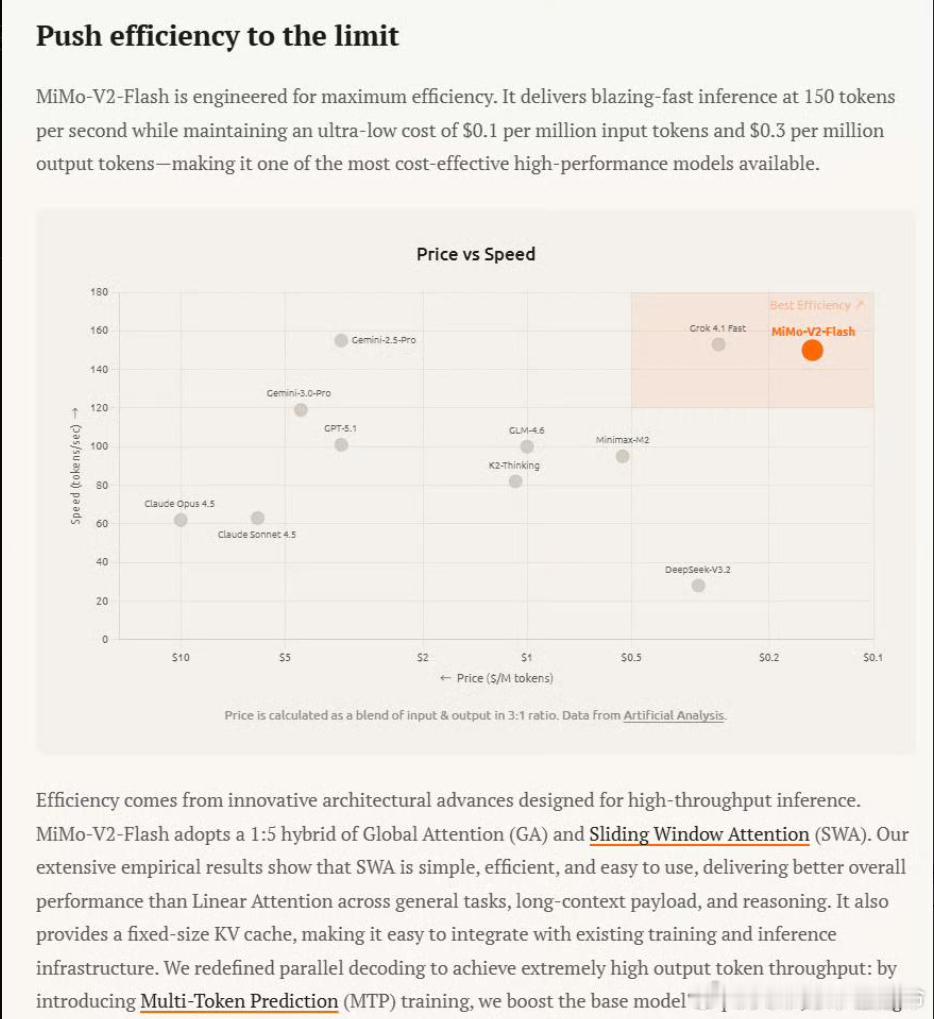
万万没想到!世界首富马斯克又抛出一个惊人言论:“中国真的被低估了!中国并没有崛起,中国只是恢复了历史地位,自古就是第一强国,他们有很多聪明的头脑,会做出许多伟大的事情,DeepSeek就是其中之一……”马斯克说话向来不绕弯子,这话意思很明白,今天中国科技搞得这么猛,不是什么意外,而是人家本来就该在那个位置上。事实上,马斯克不止一次地公开羡慕,说中国的工程师又聪明又勤奋,数量还多。2025年,杭州一家叫深度求索的AI公司,用18个月走完了硅谷企业三年的路——他们的R1模型在数学推理上追上OpenAI,训练成本却不到人家的1/10。这种"用更少资源做更多事"的本事,像极了北宋沈括在《梦溪笔谈》里记录的活字印刷术:工匠们用胶泥刻字,三天就能印出十万份邸报,比雕版印刷快了百倍。历史总是押韵的,当DeepSeek的工程师在西湖边,优化稀疏注意力算法时,他们或许没意识到,自己正在续写千年前的创新逻辑。这种传承藏在数字里。2024年中国研发人员总量世界第一,45岁以下科研人员占比超80%,这让"揭榜挂帅"的机制真正活了起来。就像南宋临安的官窑工匠,年轻人带着新釉色配方直接叩见皇帝,如今90后博士能带着量子计算方案走进国家实验室。DeepSeek的创始团队平均年龄32岁,却在2024年就突破了混合专家架构,把千亿参数模型的推理成本压到行业1/10。这种"年轻人挑大梁"的传统,从都江堰的李冰父子到今天的量子团队,从未断绝。支撑这一切的,是中国特有的"应用土壤"。当DeepSeek的模型在2025年2月,同时登顶中美应用商店时,背后是70家企业的快速适配:比亚迪用它优化车机算法,吉利融合它做自动驾驶,甚至浙江的纺织厂都在用它调染色配方。这种从实验室到生产线的无缝衔接,和北宋汴京的"前店后厂"如出一辙——沈括在宫里改良的活字,三个月后就出现在杭州书肆的《论语》刻本里。2024年中国高新技术企业超50万家,比2020年翻了近一倍,这些企业就是当代的"临安作坊",让AI模型落地速度比欧美快30%。马斯克特别提到的电力优势,其实是文明延续的另一种注脚。2026年中国发电量预计是美国三倍,这种能源底气让数据中心像古代的驿站一样遍地开花。就像大运河连接南北漕运,今天的"东数西算"工程把西部的绿电输送到东部的算力枢纽。DeepSeek在宁夏的算力中心,用光伏电训练模型,每度电成本比硅谷低40%。这种对能源的极致利用,和汉代翻车、唐代筒车的智慧一脉相承——都是在给定资源下做到效率最大化。更深层的密码藏在语言里。DeepSeek的23亿中文语料库,包含着"马上办"的政务效率、"平仄对仗"的诗歌逻辑,这些文化基因是ChatGPT用再多英文数据也学不会的。就像敦煌壁画修复师需要懂矿物颜料的千年特性,中国AI对母语的深层理解,让它在医疗读片时能识别中医典籍里的"弦滑脉",在金融风控中看懂"抽屉协议"的潜台词。这种技术与文化的共生,在北宋的《营造法式》里就有先例——建筑图纸不仅标注尺寸,更暗含"天工开物"的哲学。当DeepSeek在2025年3月完成国产芯片适配时,他们或许不知道,这种"替代进口"的路径早有历史参照。明代宋应星在《天工开物》中记录的"生铁淋口"技术,用本土材料解决了农具耐用性问题,今天华为的5G芯片、中芯国际的14nm工艺,何尝不是新时代的"生铁淋口"?美国的芯片封锁看似凌厉,却低估了中国工程师"螺蛳壳里做道场"的本事——DeepSeek用FP8混合精度训练,让国产GPU也能跑千亿模型,这种务实创新,和古代工匠用竹片代替铜活字如出一辙。站在2026年的时间点回望,中国科技的"恢复"轨迹清晰可见:2024年研发投入3.6万亿,是2012年的三倍;国际专利申请量连续五年第一;高铁、光伏、新能源汽车的技术领跑,复刻着古代丝绸、瓷器、指南针的传播路径。DeepSeek们的出现,不是偶然的黑马,而是千年创新生态的必然产物。当800万理工科毕业生每年涌入市场,当3.6万亿研发经费持续浇灌,当14亿人构成的应用场景成为试验场,科技的回归就像黄河入海,是地理与文明的双重必然。