如果不是看研究方向,很难把詹仙园和“具身智能”直接联系起来。他本科读的是清华土木工程,后来去美国普渡大学读交通工程博士,博士期间一半时间泡在计算机系做机器学习;毕业后进入微软亚洲研究院,再跟着前上司转去京东科技,主导过基于离线强化学习的火电优化研发项目,并完成了产品化及在国内多个电厂的推广落地。直到 2021 年,他回到清华,正式把重心转回学术研究。
“说白了,就是希望能自由地做一些自己感兴趣的事。”他笑着概括自己一次次转向的原因。表面上看,他从土木到交通,从工业控制到自动驾驶和具身智能,一路在“换赛道”;但如果把这些经历抽象成一个问题,就能看出贯穿其中的主线:怎么用数据驱动的决策优化技术,让智能体在真实物理世界里更好的解决问题。
也因为如此,当具身智能的发展进入大模型时代后,他比很多人更早意识到:真正限制通用机器人能力的瓶颈,不是模型够不够大,而是跨具身形态的异质性——不同机器人之间在硬件、感知和控制上的巨大差异,让本来就相对有限的具身数据形成孤岛,也让所谓的“通用 VLA”经常在迁移时崩塌。
X-VLA 就是在这个判断下诞生的。
在过去 11 个月里,詹仙园和他的学生们尝试了几十种模型结构:从统一动作空间,到各种中间表征的压缩映射,再到如何让模型真正理解“不同机器人长得不一样”。最终,他们把异构性处理前置到模型入口,用一个可学习的软提示(soft prompt)承载每个机器人独特的“本体特征”,让 Transformer 主干可以充分学习跨任务的通用规律。
这一设计带来了超出预期的结果:以仅 0.9B 的参数量在五大权威仿真基准上全面刷新性能纪录;只用 1200 条示教数据,就学会了叠衣服这种超长程复杂任务;甚至零样本迁移部署至全新的环境。
最终,在杭州举办的 IROS 2025 AGIBOT World Challenge 国际具身智能竞赛上,詹仙园团队与上海人工智能实验室联合组队,夺得冠军。

(来源:受访者提供)
回归学术,为自由度与前沿探索问芯:你在产业界主导了诸如火力发电优化这样的优秀项目,是什么促使你回到学术界?
詹仙园:产业界能够做很多非常务实、有直接落地价值的事情,但在研究方向的选择上自由度相对有限;相比之下,学术界则提供了更高的自由度,研究者能够自主决定探索的方向,并有机会从事更加前沿和开创性的研究。
问芯:是什么契机,让你判断下一站是具身智能和自动驾驶?
詹仙园:工业控制、自动驾驶规划以及机器人控制,看似分属不同领域,本质上都可以归入同一类问题:决策优化和控制问题。这些场景背后依赖的算法框架、建模方式以及核心思想具有高度共通性。我长期关注的依然是这条主线,只是应用方向在不断扩展。
当前,我的研究主要聚焦于三个方向:工业控制、自动驾驶,以及具身智能。之所以关注具身智能,一方面是因为大模型的发展推动了机器人认知与决策能力的整体提升,使其不再局限于高度定制化任务(task-specific)的操作;另一方面,也是因为这一领域的技术成熟度正在快速提升,能够支持我们探索过去难以实现的复杂任务,领域的潜力与想象空间都比较大。
问芯:是否会考虑将具身智能领域的研究成果落地应用?
詹仙园:现在是开展具身智能研究的一个非常关键的窗口期。无论是方法论还是具体技术路线,目前都远未收敛,整个领域仍处在快速演化的阶段,蕴含着大量值得探索的问题。尽管业界已经能看到一些人形机器人或其他形态的机器人在接近真实应用的任务上取得进展,但若要真正实现产品化、进入家庭或服务场景并规模化落地,我个人认为至少仍需 3-5 年的时间。
在这个阶段,我认为要先把底层的通用框架和模型架构打稳。具身智能体要具备足够的可扩展性和可迁移性,必须让其在 scaling law 上展现足够的斜率——也就是随着数据和算力的增加,性能能够持续、显著提升。但目前许多 VLA 架构在这方面表现并不理想,你很难看到清晰的 scaling 规律。
因此,与其盲目扩大规模,我更看重的是通过前沿探索,把这条 scaling 曲线的斜率真正拉起来,让模型能够展示出可持续扩展的能力。只有这样,后续的大规模训练才是高效的,也能为未来的实际落地打下更扎实的技术基础。
做“小而强”的通用VLA问芯:如果不解决跨具身异质性难题,所谓的通用机器人模型会卡在哪个“天花板”上?
詹仙园:如果跨具身异质性的问题得不到解决,会带来一系列连锁影响。
首先,大量原本可以用于训练的真实世界数据将无法直接利用。缺乏跨本体的迁移与适配能力意味着每种机器人都必须强依赖自身的小规模数据孤岛,哪怕花费高昂的成本采集,最终能够用来训练的有效数据量仍然有限,从而无法支撑大规模具身模型的发展。
其次,跨本体训练本质上能够极大提升样本的多样性。对于任何希望在真实世界落地、且具有鲁棒性的具身策略而言,见过的场景足够多是关键前提。如果训练始终局限在一台机器人、同一类环境,模型往往会在狭窄分布内过拟合,难以形成真正具有泛化性的能力。
更进一步,一个具备跨本体泛化能力的模型,才真正具备基础模型的特征:它能够从规模庞大、来源异构的训练数据中持续吸收信息,实现大规模预训练,从而学习到更为本质、跨任务和跨平台的规律。
问芯:与现有的开源 VLA 模型比较,X-VLA 有什么优势?
詹仙园:X-VLA 的核心优势主要体现在高效性和可扩展性两个方面。
首先,它在极少数据条件下便展现出了令人惊讶的学习能力。我们在论文中展示的叠衣服实验,只使用了约 1200 条真实示教数据。对于这样一个涉及抓取、甩动、展平、折叠等多阶段动作的长程任务而言,这个数据量在行业内可以说是非常少的。
其次,尽管模型规模只有 0.9B 参数,X-VLA 在几乎所有主流的具身智能基准上都能达到,甚至在部分任务上超越当前的SOTA。这说明我们设计的架构在效率和效果之间找到了一个相对理想的平衡点。
更重要的是,X-VLA 展现出非常良好的 scaling 特性。从目前的实验来看,模型的能力远未达到上限。无论是继续扩大数据规模、增加训练步骤,还是适当地扩充模型体量,都有可能进一步提升性能。
问芯:为什么选择了叠衣服这个场景?
詹仙园:叠衣服之所以被选为实验任务,主要有两个原因。首先,它本身是一个超长程的任务,包含许多复杂的操作环节。举例来说,衣物最初通常是随意堆成一团的,模型需要先将其从杂乱的形态恢复到相对平整的状态;随后,还需要想办法将衣服展开,而“甩动”这一动作在机器人上实际上非常困难——既要求力度精确,又需要抓取点合适,才能将衣服有效甩平。只有完成这些步骤之后,才进入第二阶段的折叠流程。
实际上,叠衣服的第二阶段反而是最简单的部分;最具挑战性的核心在于第一阶段——从完全随机的状态开始,把衣物整理、抓取、甩平,再进入折叠。要把这一整套流程做好,模型必须真正学到其中的关键规律,而不是简单模仿。
其次,这个任务本身足够生活化。虽然我们并不是第一支研究叠衣服任务的团队,但叠衣服确实是一个贴近日常场景、又能充分体现任务复杂性和模型性能的典型任务。
问芯:0.9B 参数放在具身智能的语境里,它算大还是小?
詹仙园:我认为 0.9B 是一个相对较小的模型参数规模。当前能够达到类似能力水平的模型,通常都在 3B 到 7B 之间,甚至已经有团队发布了 72B 甚至更大的版本。相比之下,0.9B 属于非常精简的体量。
但对具身智能而言,我认为这样的小规模反而是更有意义的。未来模型一定是要部署在机器人本体上的,如果模型过大,部署会面临非常多问题,不可能所有具身智能能力都依赖云端来支撑。在实际场景中,更需要那些“小、通用、轻量,同时又足够强”的模型,才能真正部署在机器人上,实现可扩展性。
问芯:X-VLA 的参数仅0.9B,但在多个基准上达到 SOTA,为何能实现“规模更小,性能更强”?你怎么看“做小而强”和“堆大算力”这两种路线?
詹仙园:目前行业中许多体量巨大的 VLA 模型(往往以数十亿参数起步),其实大多数还是基于现成的 VLM 搭建出来的。
但这种方式并不一定高效。原因在于,这些被拿来做底座的 VLM,本身的训练数据并不面向具身智能场景,它们主要使用互联网图片、通用图文对等进行预训练,并不是一个“具身语境下的大脑”。如果强行以这样的模型作为基础,希望通过外接动作模块训练出一个高质量的具身智能模型,其效率往往是有限的。
因此,在设计 X-VLA 时,我们刻意没有选择规模最大的 VLM,而是选用了一个相对精简的模型——Florence。它虽然参数量不大,但训练中包含了丰富的视觉定位(visual grounding)、物体位置关系、物理关系等相关的任务数据,更接近一个“具身场景的视觉大脑”。基于这样的选择,整个模型的训练效率和效果都会更高。
此外,X-VLA 中可有效支撑跨域数据学习的 soft-prompt设计,以及下层简洁的 Transformer 主干网络,都在大幅提升模型性能的同时,保持了模型的相对精简的体量。
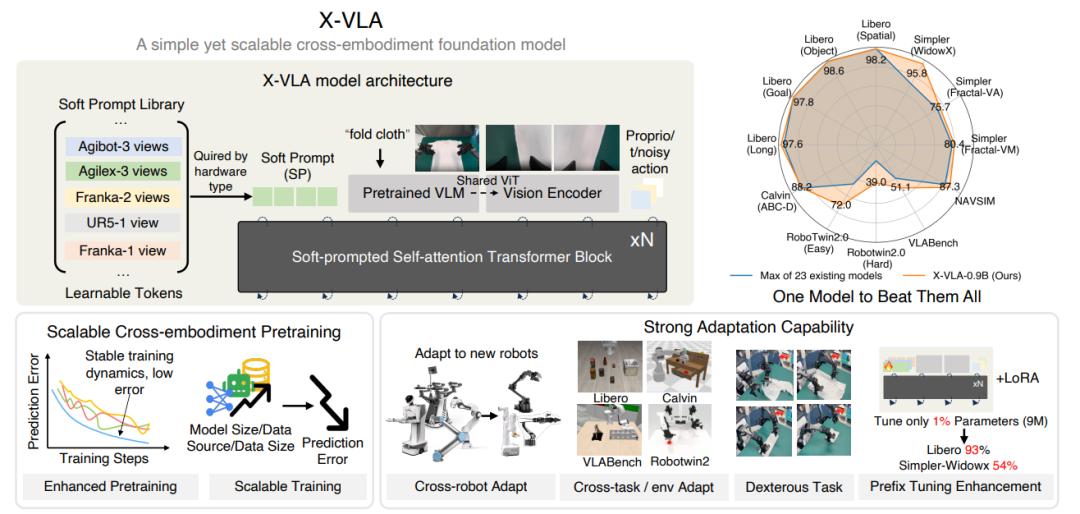
图 | X-VLA 引入了一种称为 soft prompt(软提示) 的可学习嵌入,用以有效应对跨具身数据集中存在的异质性
问芯:X-VLA 在 0.9B 规模上还没有看到 scaling 饱和,你们接下来想先扩模型,还是扩数据域?
詹仙园:我倾向于采取“两条腿走路”的策略。
一方面,模型本身仍有明确的优化空间。无论是在架构设计、信息流动方式,还是在训练目标上,X-VLA 都可以通过进一步的研究获得性能提升。
另一方面,我们也需要从 scaling 的角度继续扩展,包括增加数据量、提高算力投入,甚至在合适范围内适当提升模型规模。
目前我们主要针对单臂、双臂等机械臂任务进行了训练和验证。下一步,我们也会把一些人形机器人全身控制(full-body control)的训练数据加入进来,看这类数据是否能够进一步提升模型的泛化性与多任务能力。
问芯:你提到该模型的性能还没有达到它的上限,那么后续有什么规划?
詹仙园:第一是在后续的研究中把一些推理能力进一步加入到 X-VLA 中。因为目前的 X-VLA 还是一个相对纯粹的视觉—语言—动作模型(VLA),更多是完成感知和控制层面的工作。接下来我们考虑将更多具身推理(embodied reasoning) 引入,并以更结构化的方式融入模型,使其能够在复杂的物理场景中进行一定程度的推理,从而更好地支持长程、多阶段任务的执行。这是我们非常想加强的一块能力。
第二,我们也在研究如何进一步优化整个模型架构,让它在超长程任务的执行上具备更好的自适应处理能力。现实中的许多具身任务往往不是短序列,而是跨越很长的执行链路,因此如何让模型在超长时间尺度上保持稳定性、连续性和任务理解能力,也是我们下一步会重点推进的方向。
当模型走出实验室问芯:在测试过程中,有没有遇到一些出乎意料的良好结果?
詹仙园:对我而言,最让我感到意外、甚至印象深刻的结果有两个。
第一个是模型只使用大约 1200 条数据就学出了一个完整的叠衣服策略。而从结果来看,它展现出的行为非常“像人”,在执行过程中,如果出现意料之外的错误,它会自行调整、重新尝试,并最终能够把这样一套复杂的任务流畅地完成。
第二个是模型在主流 benchmark 上甚至更复杂的真实环境中的表现确实足够好。
在这个工作完成之后,我们的一个企业合作伙伴看到实验效果,希望我们把模型拿到他们的展会上做一次展示。坦率地说,当时我们是有些缺乏信心的,因为模型训练完全基于实验室环境的数据,我们并不确定它在一个复杂的会展现场——光照、背景、动态环境都完全不同——是否还能稳定完成任务。
但结果出乎我们的预期:我们没有对模型做任何调整,它就能够“零样本”地直接迁移到一个完全全新的场景,并且执行得非常好。这一点同样让我们感到非常意外。
郑金亮:让我感到惊喜的是我们留到最后才进行的一个实验:使用极少量可训练参数,通过 LoRA 的方式对下游任务进行微调。我原本并没有抱太大期待,只是希望验证一下模型在这种极简设定下的表现。然而结果远超预期:在仅使用一个 0.9B 的基础模型、搭配约 9MB 的可训练参数的情况下,模型在两个主流 benchmark 上取得了与全量微调几乎相同的成绩。
这一点对我而言意义重大。它表明,在前期进行大规模异构数据的训练过程中,模型确实学到了足够通用和本质的能力,因此只需要极小规模的参数调整,就可以快速适配到全新的任务中,甚至达到 SOTA 的水平。从那一刻起,我才真正确信,我们在 X-VLA 上探索的这条路径是有效的,也是具有潜在扩展性的。
问芯:你提到在实验室做的是一个结果,放到展会上面可能会有一些问题,可能会产生什么问题呢?以及什么原因会导致这个问题?
詹仙园:主要原因是我们训练使用的数据几乎全部是在实验室环境中采集的,并没有进行任何面向泛化能力的专门数据采集。我们当时没有把系统放到不同的环境里采数据,比如不同的光照条件、不同的背景、不同的场景设置等等。这类变化通常需要更大规模的数据采集才能覆盖。
但在当时的训练中,我们只使用了大约 1200 至 1500 条数据来训练模型,并没有做额外的数据增强或专门提升泛化性的采集工作。因此,按照常规判断,这样的数据规模很可能不足以支持模型迁移到一个完全不同且更复杂的会场环境。
然而,实际结果却证明模型是足够的。它成功泛化到了一个高度动态、背景完全不同的现场场景中,并且在任务上表现得非常稳定,这一点也超出了我们的预期。
问芯:基于当前的研究成果和技术发展判断,你们觉得该模型最快可能会在哪些场景中应用?
詹仙园:我认为,在短期内更有可能在半开放场景中实现落地。例如分拣、装配、台面操作(table-top manipulation)等任务,这类场景的环境约束相对明确,任务边界清晰,对模型的泛化能力要求也较低,因此更容易形成可部署的产品形态。
相比之下,真正进入家庭、完成复杂家务等高度开放的任务,目前整个行业仍处于探索阶段。从技术成熟度、数据规模,到硬件协同与产品化路径,都还需要较长时间的积累。我个人判断,要把这类任务做到可规模化部署,至少需要三到五年的研发周期,并伴随大量进一步的前沿探索。
即便如此,基于 0.9B 的 X-VLA,在某些简单或中等复杂度的台面任务上已经具备了较强的潜力。如果未来能够进一步扩大数据规模,并结合更系统的扩展性训练,我相信它在若干具体场景中已经可以达到较为理想、甚至接近商用的水平。
参考链接:
1.https://arxiv.org/pdf/2510.10274