一直想尝试在NAS上部署AI大语言模型,可无奈之前NAS设备的硬件配置比较落后,运行最低参数的模型也比较吃力。
不久前,我升级了家里的主力NAS,换上了威联通新品NAS——威联通Qu405,硬件配置有了质的提升,能支撑流畅运行文本系列大模型,而它的外观设计和一些细节配置相比之前的型号也做出了不小的改变。接下来,我就用这台威联通Qu405复盘如何利用OpenWebUI部署DeepSeek、通义千问等大模型。

教程开始前,先来了解一下本文的主角威联通Qu405吧。
威联通Qu405是一款4盘位NAS,支持4块3.5英寸或2.5英寸SATA接口硬盘,同时还内置2个M.2 PCIe Gen 3插槽,可配置双M.2 SSD组建高速储存池或快取加速,提升存储和运算效率。
如果盘位不够用,还可以选择它的同门师兄8盘位的Qu805。而且,两台机器加量不加价,又赶上双11促销,4盘位到手价3100元左右,8盘位到手价也只要3300元左右,价格非常给力。


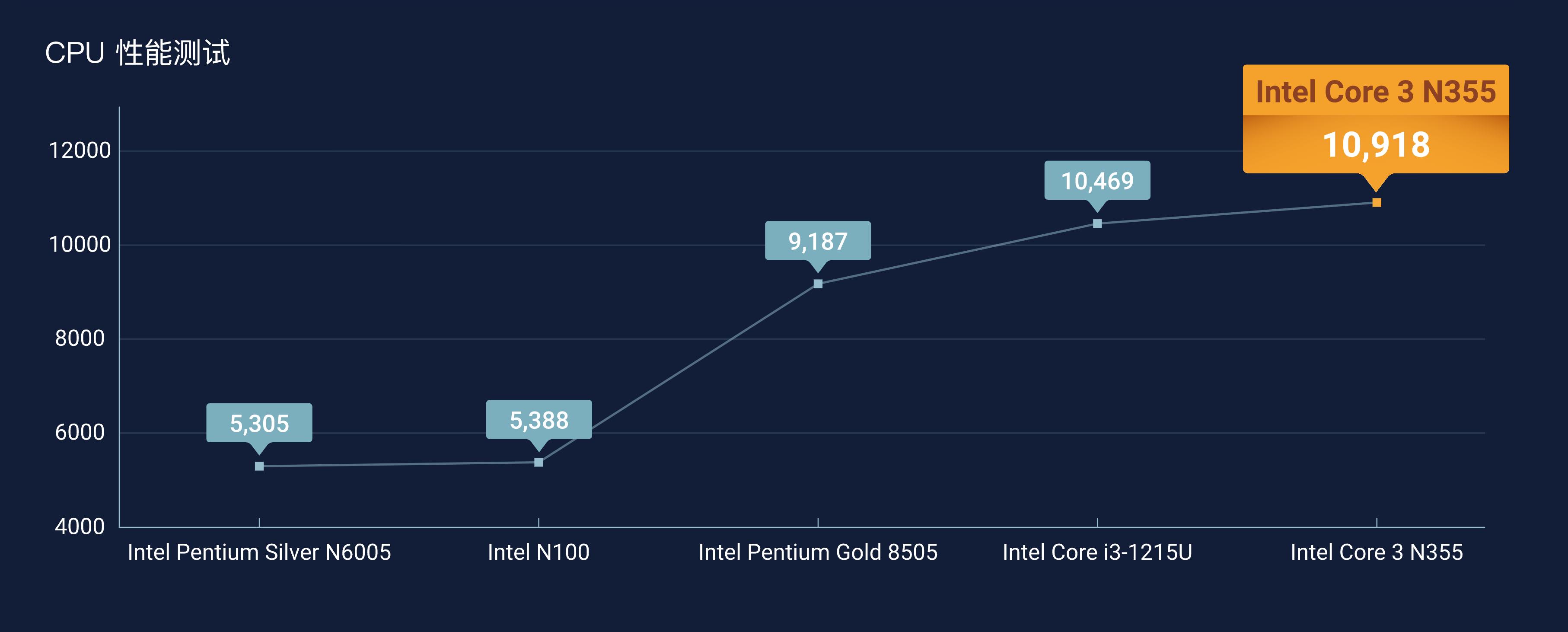
威联通Qu405最重要的升级是它搭载了新一代Intel酷睿N355处理器,拥有8核心8线程,最大睿频频率3.9 GHz,6MB高速缓存。性能表现如下图所示,N355处理器的综合性能大约是N6005、N100的2倍,比目前主流的高端NAS处理器intel Pentium Gold 8505提升了约19%,提升非常显著。
AI大模型的训练和运行非常吃内存,以往我用的几台NAS多是8GB内存,运行大模型捉襟见肘。我这台威联通Qu405配备金士顿16GB SODIMM DDR5内存,虽然官方介绍这台机器支持内存最大容量16GB,但实测最大可以扩展到24GB(测试使用的是英睿达内存条),联合酷睿N355处理器,为部署 AI大模型打下坚实的硬件基础。

这台NAS前置1个USB-C 3.2 Gen 2接口,背面则是HDMI 2.1视频接口(4K@60Hz)、双2.5GbE网口(支持链路聚合)以及2个USB 3.2 Gen2(10Gbps)接口,丰富的拓展接口足以满足日常所需。

(1)配置Open WebUI
利用威联通NAS的Container Station配置Open WebUI,Container Station-应用程序-创建。
Open WebUI是一款功能强大、扩展性强的自托管网页界面,支持多种大型语言模型框架,兼容Ollama与OpenAI API以及兼容LMStudio、OpenRouter等多款LLM服务。
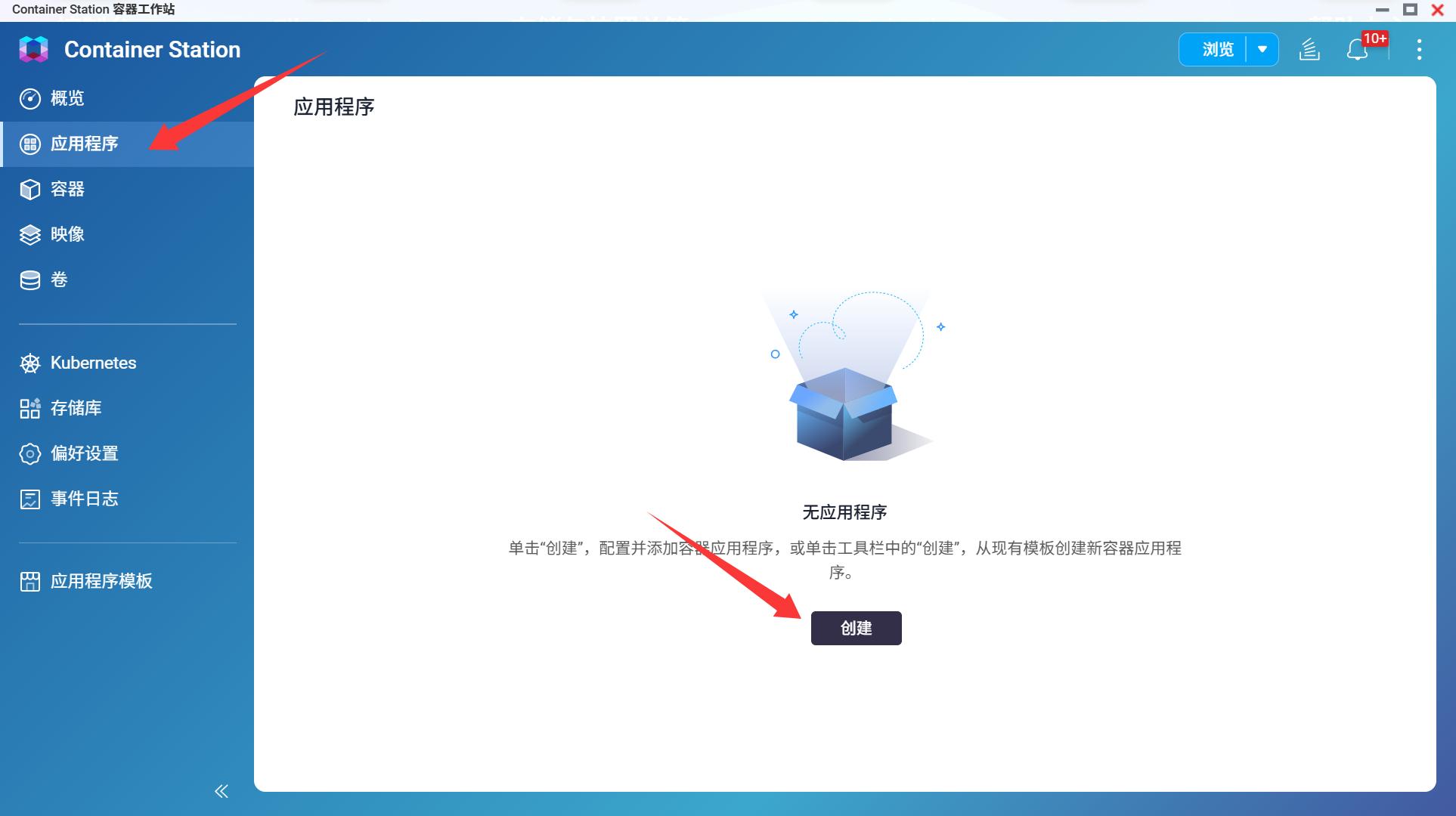
在YMAL代码窗口输入以下Open WebUI的Docker Compose配置文件,验证通过后点击创建即可。
services:
open-webui:
container_name: open-webui
image:ghcr.io/open-webui/open-webui:ollama # 镜像名称
restart: always # 重启策略
ports:
- 3000:8080 # Web服务访问端口
volumes:
- ./ollama:/root/.ollama # ollama相关数据存储
-./open-webui:/app/backend/data # Web UI后端数据存储
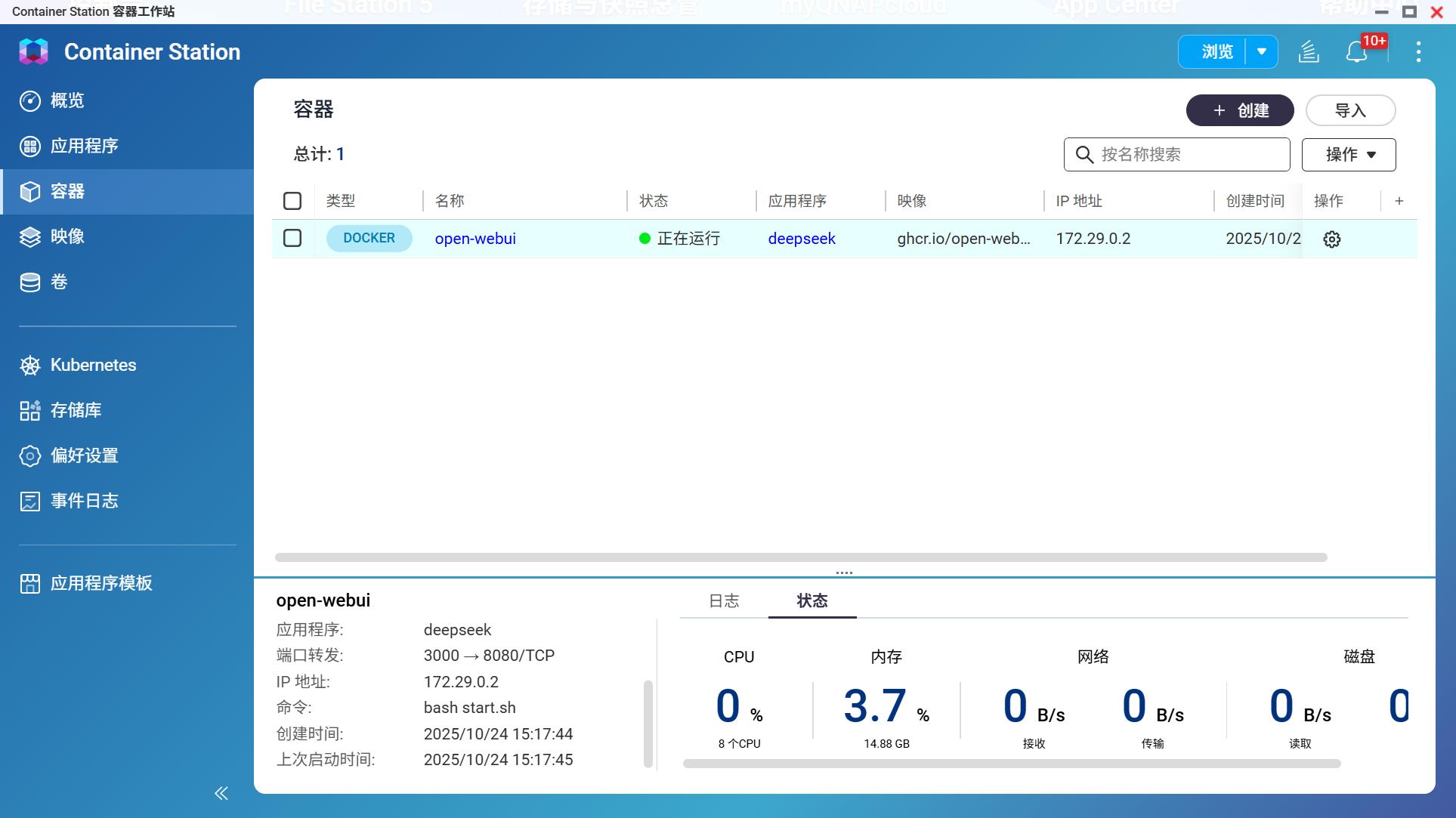
创建完成后,系统会自动拉取镜像并启动容器,至此,Open WebUI部署完成。
在浏览器输入登陆地址进入Open WebUI界面。登陆地址是NAS的局域网IP+端口,比如我的是:
http://192.168.50.228:3000
需要注意到是,部署完成之后需要5-10分钟时间加载数据,没有加载完成之前访问会提示【拒绝连接】,不要慌,耐心等待加载完成再访问。

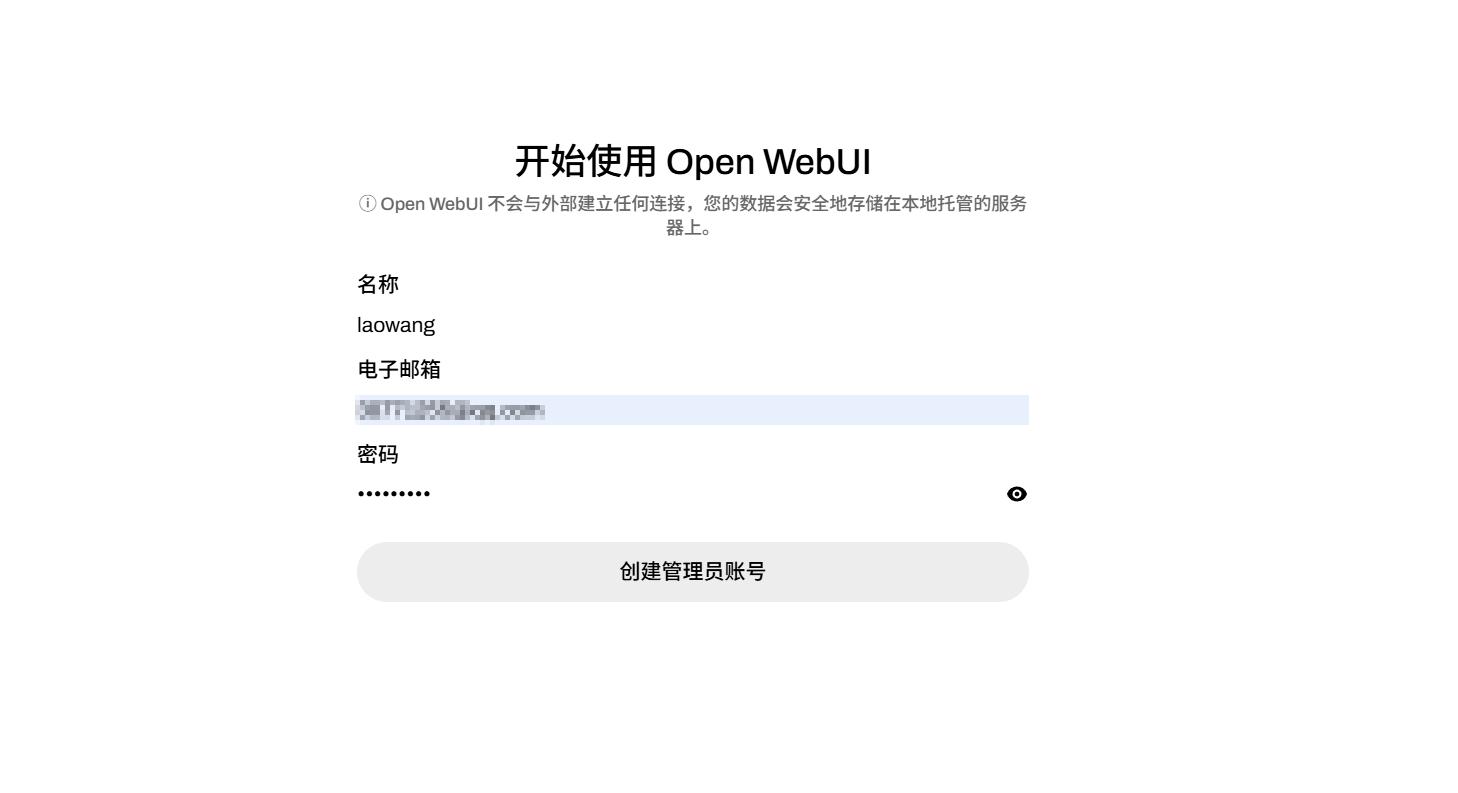
首次访问时,需要设置用户名、电子邮件和密码来创建管理员账户。
(2)添加模型
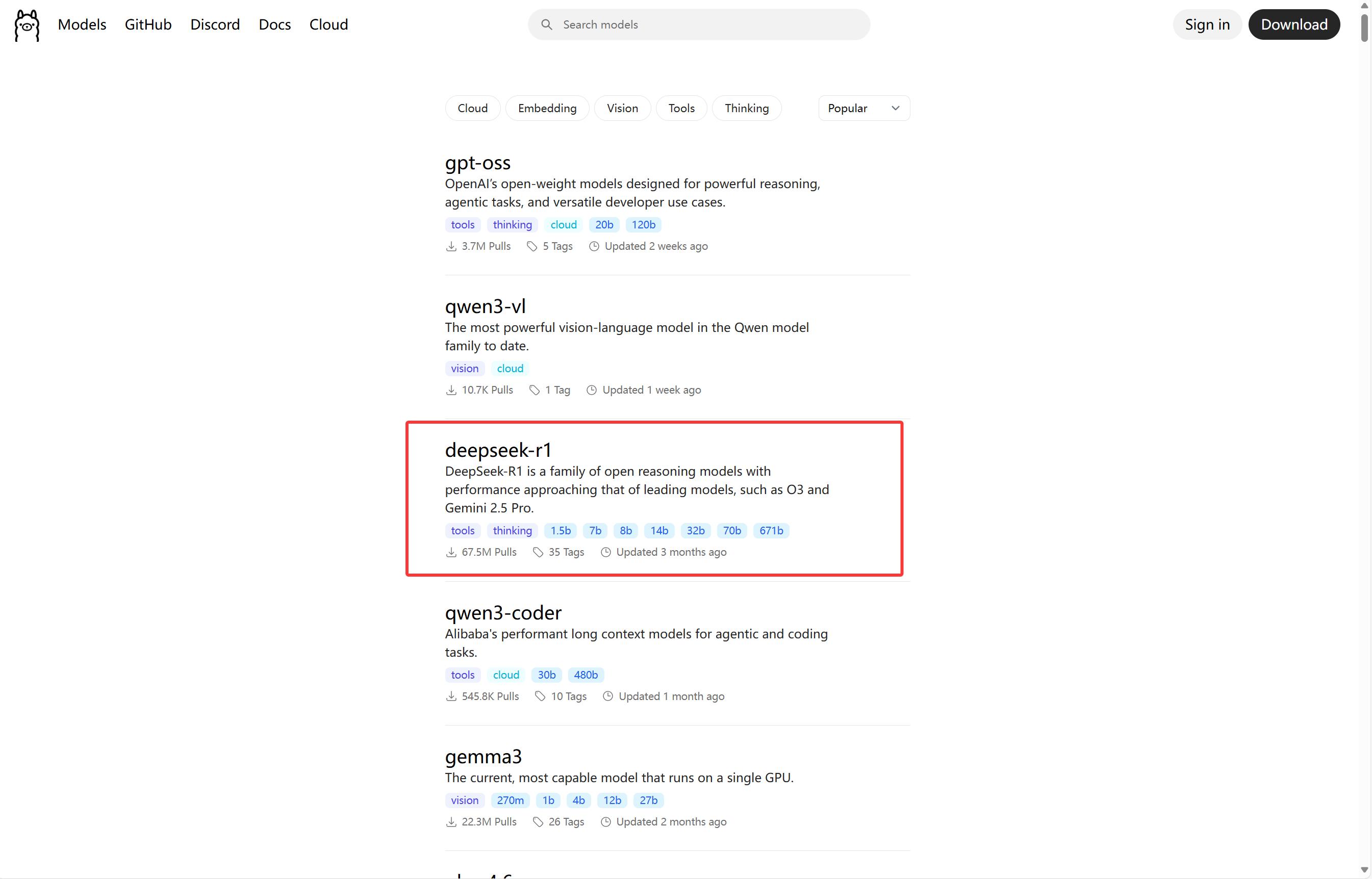
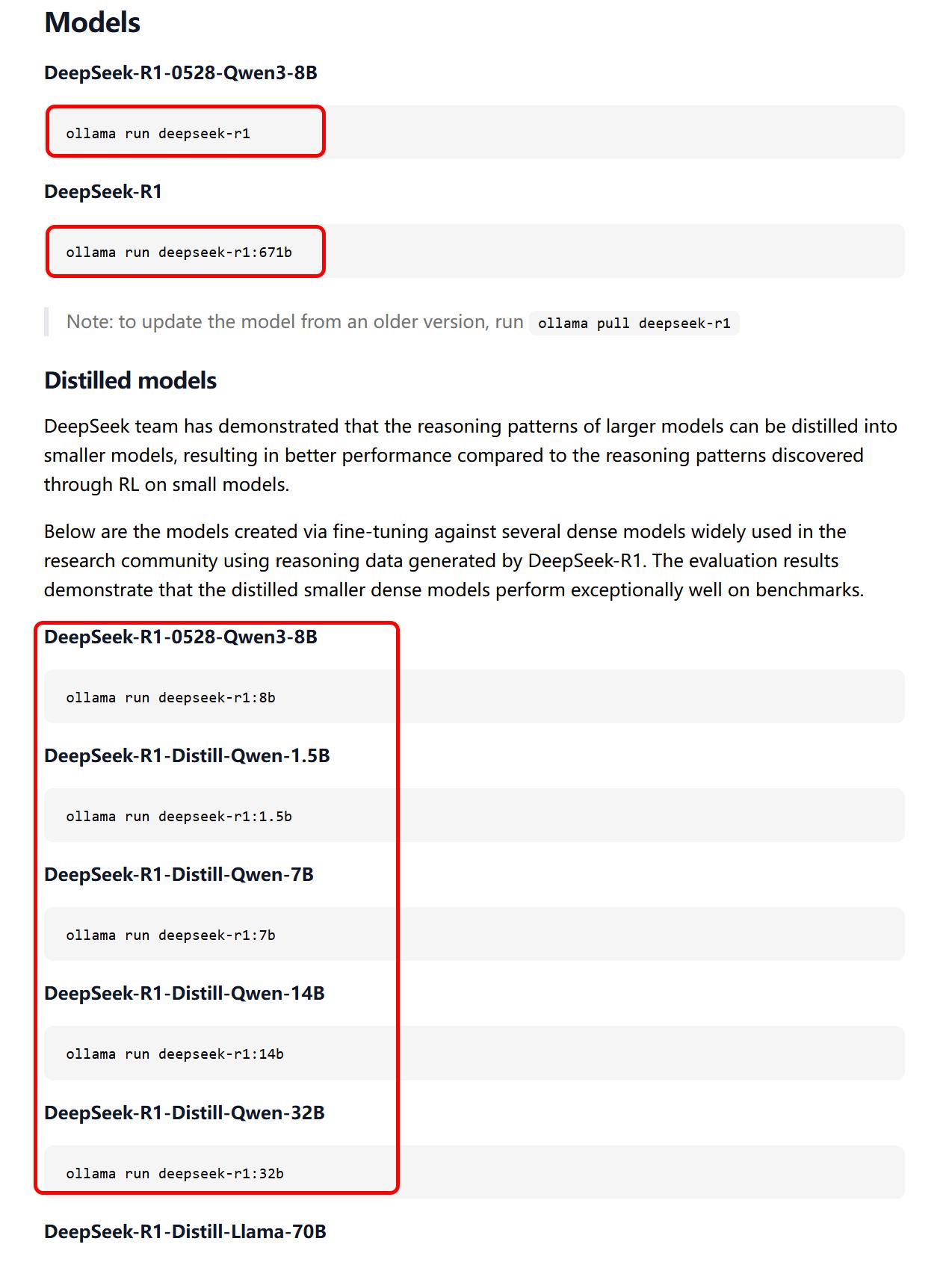
打开Ollama模型库(https://ollama.com/search),找到所需模型并复制拉取命令,例如选择:
ollama run deepseek-r1
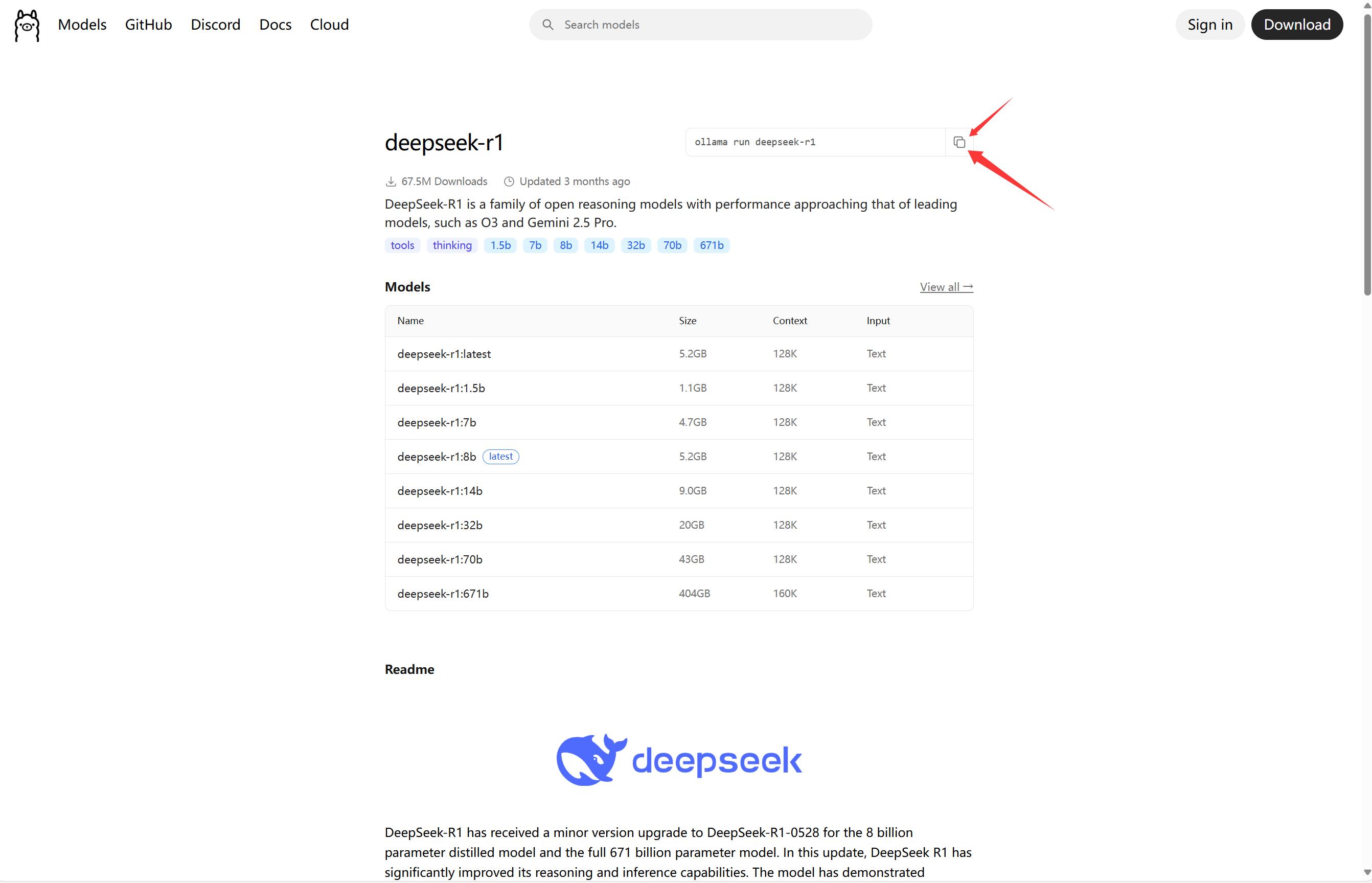
复制之后来到Container Station,在创建的容器后方设置-执行
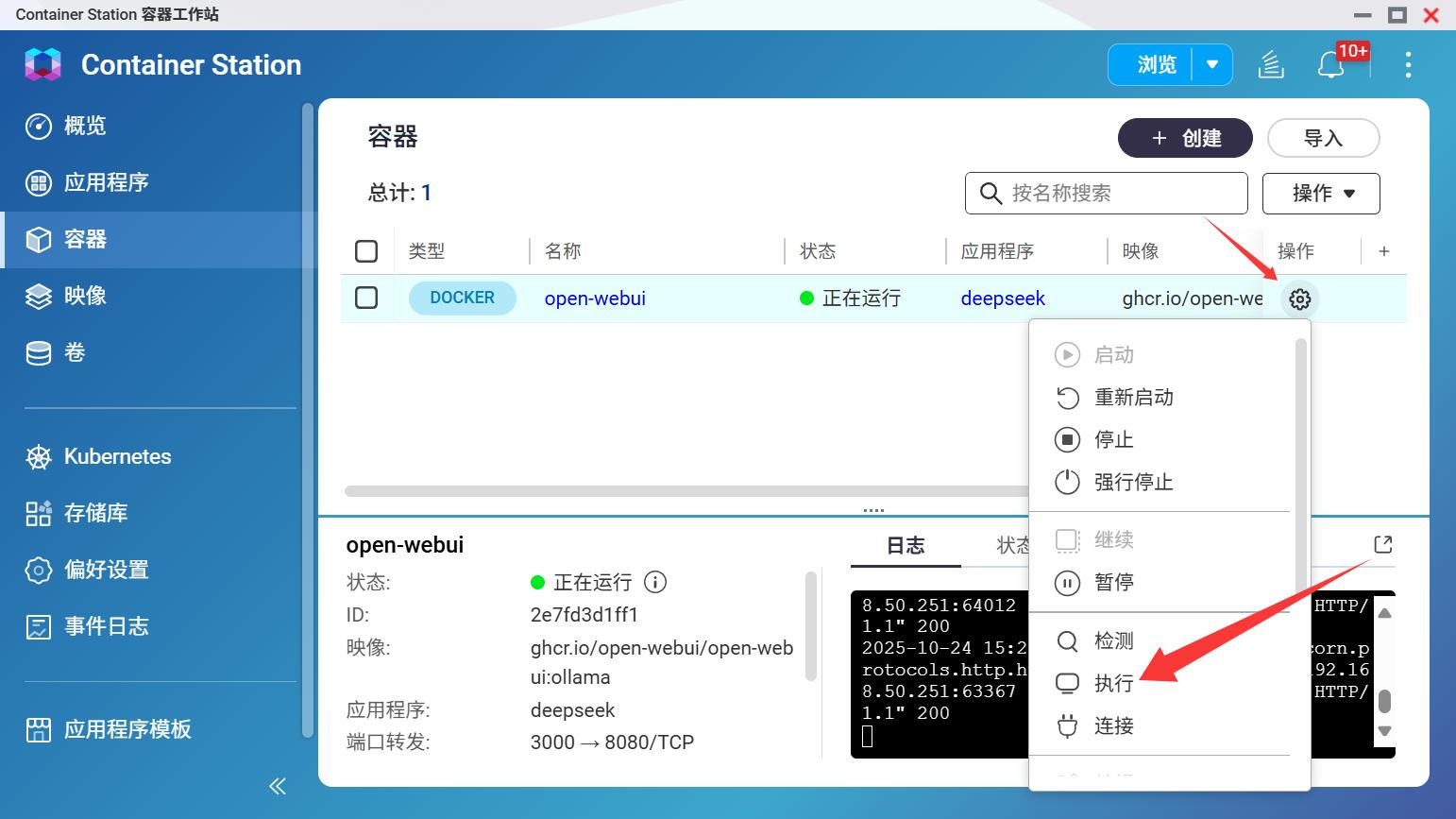
粘贴拉取命令,等待模型下载完成。
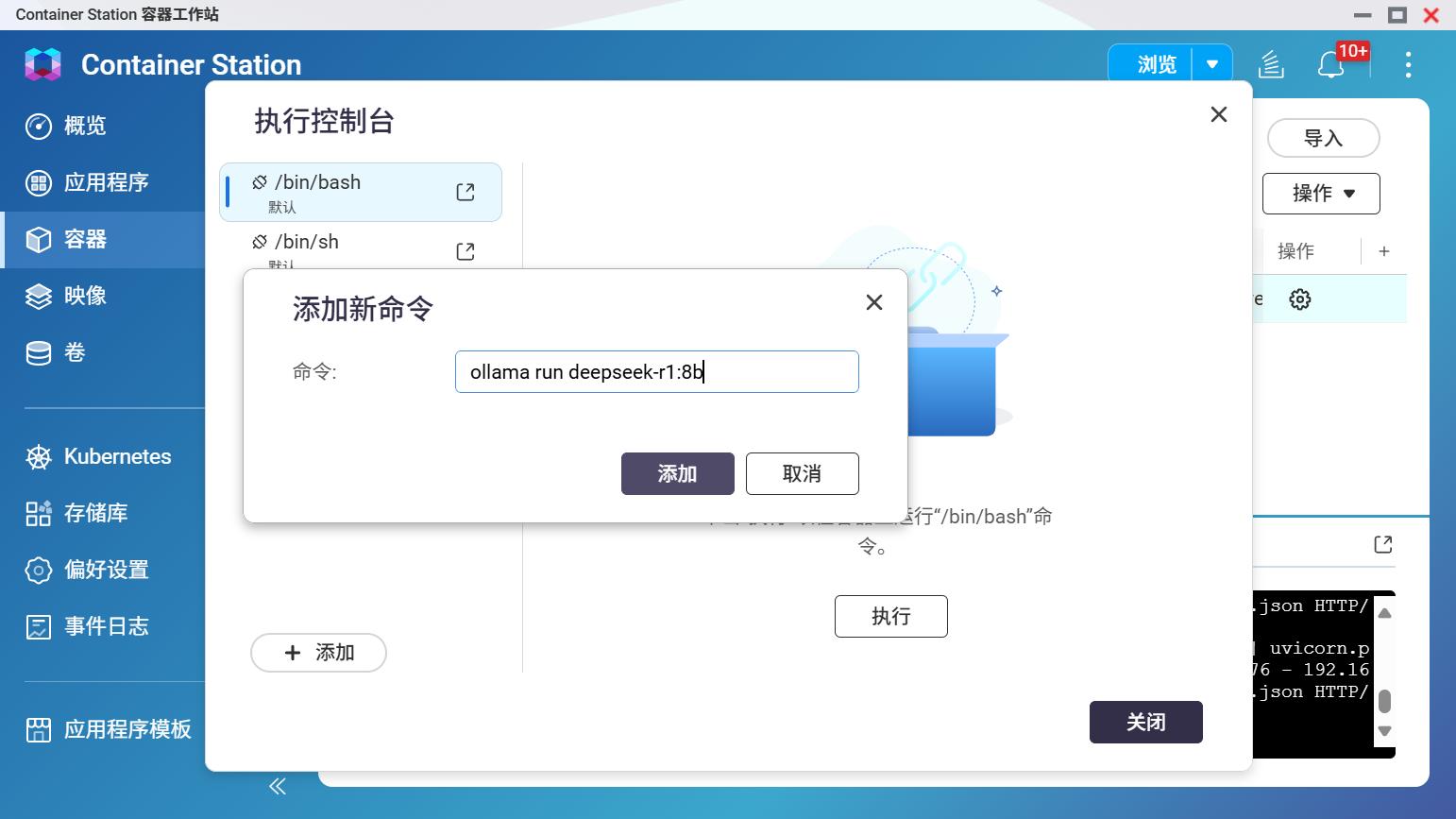
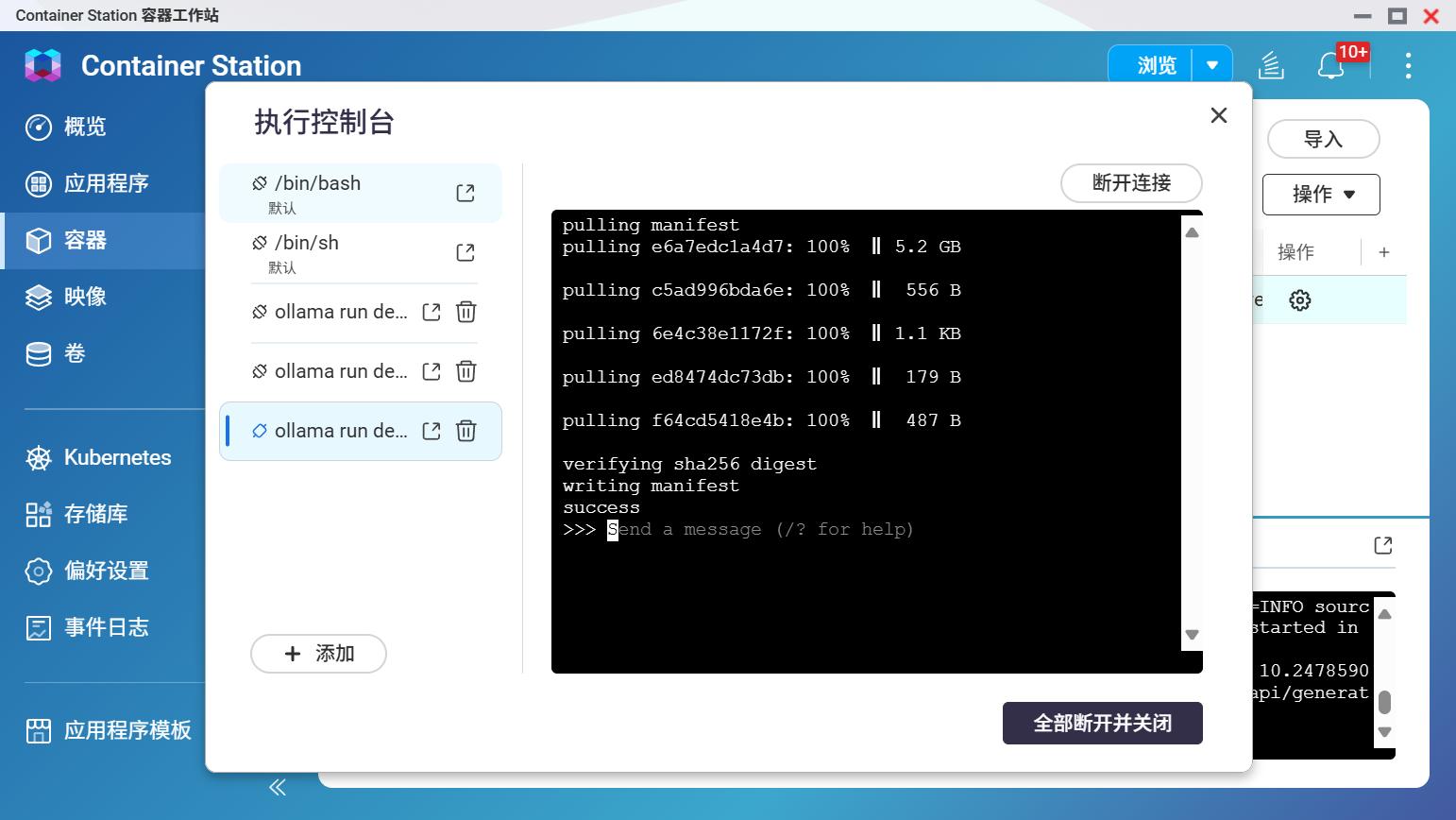
下载完成之后重启容器,然后在控制台执行命令,并且,之后每次使用模型都需要先执行命令。
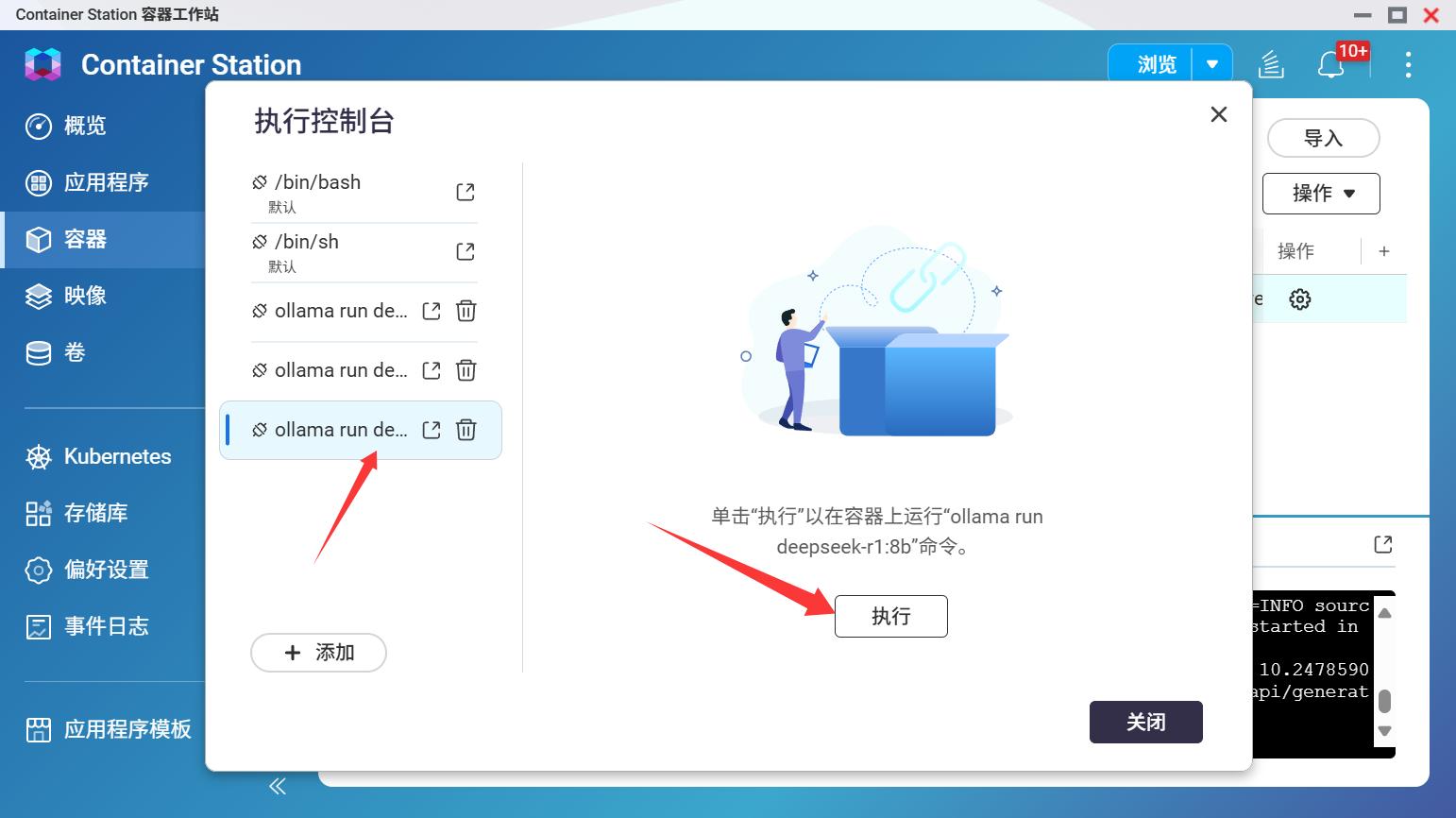
重新登录 Open WebUI ,在左上角确认模型是否成功加载。
选择所需模型就可以愉快地与AI对话啦。

利用OpenWebUI+Ollama可以部署DeepSeek、GPT、千问、Gemma等众多主流AI模型,而利用NAS部署DeepSeek这些大语言模型的核心价值在于能实现离线运行,延迟更低、响应速度更快,更能保障数据隐私与安全,感兴趣的小伙伴还不快动起来!