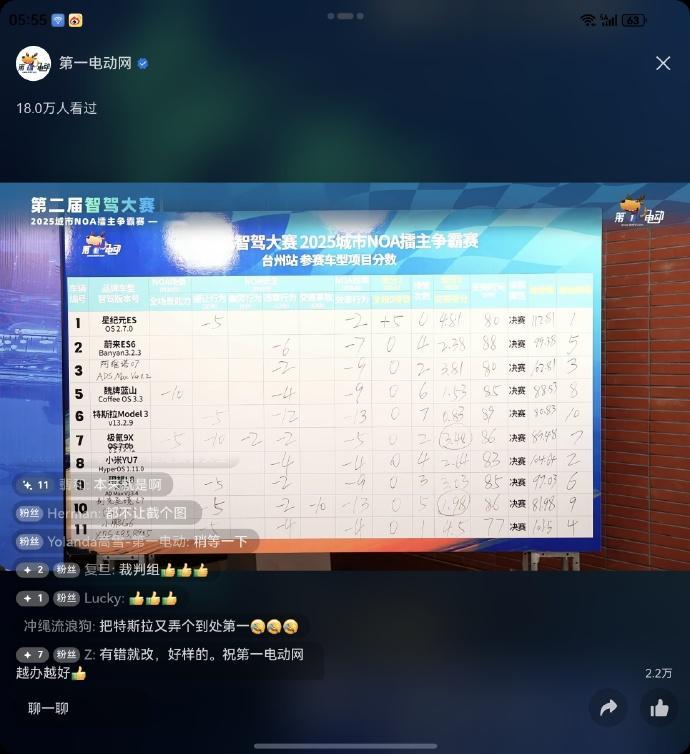
别克至境 L7 在中国智驾大赛宁波站以绝对优势获得冠军。而在昨天的台州站,以 81.98 分的成绩遗憾落败。我想聊聊这个结果。很多朋友会觉得,既然是比赛,又是智驾大赛,肯定是比谁更“智能”,换句话说是比的系统“智商”,但遗憾的是这个观点并不对。 智驾系统发展到现在,本质上还是一个归纳系统,它的“智能”来自于样本中的模式总结,而并非演绎式的推理理解。说白了就是你知道的越多,了解的越多,你可能做出越接近正确的决策。系统最终的逻辑结果以及操作都是基于“像不像”,而非基于“为什么”。这个机制决定了无论智驾类型,全部都是来自海量数据的大规模统计归纳,最终产生从相似性上诞生的推测和操作。所以智驾大赛真正比的内容可以从简单和复杂两方面说明,简单来说就是:“比谁更熟悉考题,比谁的数据和处理更接近标准答案”。复杂点来说就是:1,谁的数据分布更接近比赛路况。2,谁的模型更抗噪。3,谁的工程更精细。4,谁的安全边界更稳定。 5,谁更幸运。所以,我认为智驾比赛的结果是一个单点样本,而过程实际上更为重要,它能够体现系统能力。当我们一旦认清智驾本质后,再来复盘评分表就能更好理解至境 L7 这次的参赛结果。我此前多次在动态评测节目中表示,智驾在拍摄中成功的主要因素在于当天的路线、路况、其他交通参与者动态,结果唯一且无法复现。这能解释从宁波站全程 0 接管夺冠到台州站惜败的表现。路况的复杂程度以及随机度,超出了当前通过归纳所产生合理结果的能力。比如第一点,昨天出发时窄路遇大货车会车,以及大货车后的对头车,外加路人指挥干扰,这种随机交通行为远超智驾的归纳能力,最后驾驶员无奈手动接管。第二点,L7 在智驾期间准确判断出了行动缓慢的老人,直接停车等待老人通过而没使用任何“丝滑绕行”。这种安全第一以及符合道路交通基本道德准则的操作却导致了效率分被扣。第三点,因为裁判组和司机产生分歧,并且赶上了台州晚上的高峰期,这种随机事件以及复杂度数量级陡升的事件都对结果产生了直接影响。所以别克开始了连夜复盘辅助驾驶大赛路线的工作。这个工作的的意义不是对输赢的反应,而在能够在发现问题的基础上,快速把问题抽象成模型,学回去并处理好。这种快速响应并有较强适应性的能力是当前归纳模型最重要的能力,也是 至境 L7 上搭载的 Momenta R6 大模型领先其它模型的一个突出特点。这个特点就是基于 R6 上的强化学习能力。这个能力的特点在于成功就“记住”,失败就“避免”。所以复盘的很大一部分工作是让系统强化对成功的正确记忆以及规避失败的错误记忆。而且快速复盘,也同样基于 R6 的部署后可 OTA 升级特性。复盘后新的路况数据,新的场景反馈“再训练-再优化”闭环可以直接影响后续智驾操作决策。通过别克快速的复盘复测结果,实际上能够印证 R6 在宣传时的 AI 驱动与持续优化的这种智驾系统的代际更新并非演过其实。至境 L7 与 R6 大模型目前是行业最高水平的强化学习+ 真实用户大规模行为数据(通用 2000 万用户)+ 海量安全驾驶样本(通用 Super Cruise 8.77 亿公里安全行驶经验)共同驱动的闭环。比赛的结果实际上就像我前面说的一样是个单点样本,出现波动我认为非常正常。这意味着它在宁波赢,在台州失利、直到在下一个城市重新卷土重来,都是可以预期的。反倒是别克现在这么重视民间测试,快速连夜的响应能力让我非常赞赏。说到模型的 OTA 能力,至境L7 今天将开启首轮OTA 升级,距离它的上市仅仅两个月。这次的升级主要就是聚焦在智能驾驶,智能辅助相关的多项功能。这就是别克的数据基础与 R6 持续进化很好的证明。相信这次的测试和经验,能让后续的 OTA 升级更有意义,我觉得这才是智驾大赛最有价值的地方。别克连夜复盘辅助驾驶大赛路线别克至境L7开启首轮OTA