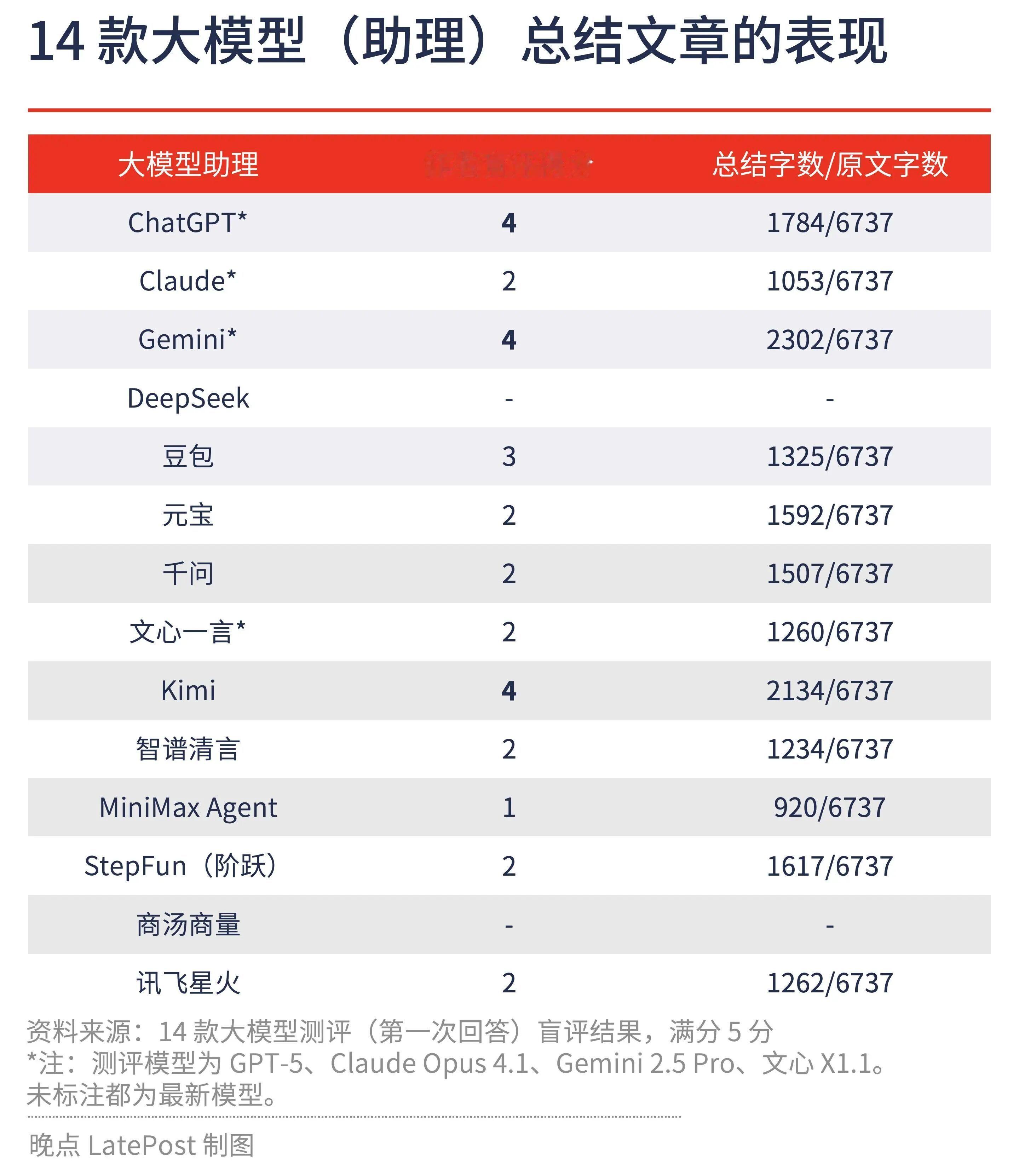
很多人都会用AI去总结文章和内容,那他们的准确度又如何呢?《晚点》的年度大模型测试,得出了一个有意思的结论:大模型的长文本处理,幻觉还在,比你还会偷懒。晚点给大模型提供了 2024 年中国具身智能大会的会议手册。手册一共有 36 页,在组织架构、会议日程、嘉宾简介部分都出现了参会人员信息,大部分人会出现多次。让大模型提供参会人员的姓名和机构。没有任何一个大模型完美解决这个问题,我们原定的追问环节也无法进行。其中,Claude、阶跃星辰、商汤商量都无法上传大于 30M 的文档。最接近正确答案的是 Google 的 Gemini(3.0 Pro)和腾讯的元宝,人数较全,但是会处理错一些参会人员所在的机构和人名等。表现相对较好的模型是 MiniMax、豆包、文心一言(文心 5.0)等,识别的人少一些,但都做到不重复提取参会人员。一些大模型在这个任务中出现幻觉,比如智谱清言在名单中添加了不少未参会的研究者,其中就有智谱的创始人、首席科学家唐杰。还有一部分模型会 “偷懒”,比如 GPT-5 驱动 ChatGPT 只提取 30 多人的名字,说这只是初稿。即便我们要求它继续整理,依然无法解决问题,出现类似问题的还有讯飞星火等。表现最糟糕的是通义千问(Qwen3-Max-Thinking-Preview),它只提取了 4 个参会者,单位错了 3 个(重复提交问题后依然如此)。用他们的文档阅读模式提取名单,给了 5 个参会者,没有一个是对的。第二个测试,总结长文,并且让原作者评分。ChatGPT、Gemini、Kimi 给出的总结质量最高,都遵循了原文,没有自己编造。它们在分析论证逻辑时存在瑕疵,比如 Gemini 说戴蒙谈了金融泡沫和工业泡沫的区分,事实上并没有。表现最差的助理是 MiniMax Agent,它给了 920 字总结,是所有模型中生成的总结最简短的,但只是泛泛而谈,也有事实错误。《晚点》这篇文章,还有其他相关的测试,我把原文链接,放在评论区一楼,有兴趣的朋友可以去读读。