
新智元报道
[新智元导读]加州大学河滨分校团队发现,AI组合推理表现不佳部分源于评测指标过于苛刻。他们提出新指标GroupMatch和Test-TimeMatching算法,挖掘模型潜力,使GPT-4.1在Winoground测试中首次超越人类,0.2B参数的SigLIP-B16在MMVP-VLM基准测试上超越GPT-4.1并刷新最优结果。这表明模型的组合推理能力早已存在,只需合适方法在测试阶段解锁。
前沿的人工智能模型虽然在众多任务上取得了显著进展,但研究发现,它们在组合推理(compositionalreasoning)方面仍表现不佳,在多个经典基准测试上甚至低于随机猜测水平。
加州大学河滨分校YinglunZhu研究团队重新审视了这一问题,发现其根源之一在于评测指标本身——它系统性地低估了模型的真实能力。

博客链接:https://yinglunz.com/blogs/ttm.html
代码链接:https://github.com/yinglunz/test-time-matching
团队据此提出了新的GroupMatch指标,能够挖掘被现有评测掩盖的潜在能力,使GPT-4.1首次在Winoground基准测试上超越人类表现。
基于这一洞见,团队进一步提出一种无需外部监督、能够自我改进的迭代算法Test-TimeMatching(TTM),可在模型推理阶段显著提升性能。
得益于TTM,仅0.2B参数的SigLIP-B16就在MMVP-VLM基准测试上超越了GPT-4.1,刷新了当前最优结果。
研究背景
组合推理(compositionalreasoning)体现了AI是否具备「举一反三」的能力——能否将对象、属性和关系重新组合,去理解新的情境。
像Winoground这样的基准测试通过2×2群组设计来考察这种能力:其中两条文本用词相同但顺序不同,每条只对应其中一张图像。
尽管这些模型在多模态任务中表现出强大能力,但对比式视觉语言模型(VLMs)和多模态大语言模型(MLLMs)在这类基准测试中表现依然有限。
在Winoground基准测试上,即便是前沿模型的得分也远低于人类水平(约85.5分);
此前的最佳结果仅为58.75,且是通过对GPT-4V进行scaffolding和prompttuning实现的。
重新审视评测指标
从随机猜测到群组匹配
加州大学河滨分校(UCR)研究团队发现,模型在组合推理任务中的低分,部分源自评测指标本身。
当前广泛使用的GroupScore指标过于严格:它要求每张图像都与正确的文本匹配、每段文本也与正确的图像匹配,但并不检查整个群组的全局一致性。
只要有一次错配,整组得分就会被判为0。
假设每组包含k张图像和k条文本描述,GroupScore只逐一检查图像与文本之间的匹配情况,而忽略整体关系。
在随机匹配下,成功率仅为(k−1)!/(2k−1)!;当k=2时,这个概率只有六分之一。
为解决这一问题,团队提出了新的GroupMatch指标,用于评估群组内的整体最优匹配,而不是孤立的成对比较。
GroupMatch会考虑所有可能的匹配方式(共k!种),并选择最可能的那一个。
这样,在随机猜测下的成功率提升为1/k!——当k=2时为二分之一,比原来的六分之一大幅提高。
更关键的是,如果模型能在GroupMatch下找到正确匹配,只需在测试阶段对该匹配进行过拟合,就能在原始GroupScore下获得满分。
基于这一发现,团队提出了一个简单的SimpleMatch两步法:
1.使用GroupMatch选择最可能的匹配;
2.在测试阶段对该匹配进行过拟合。
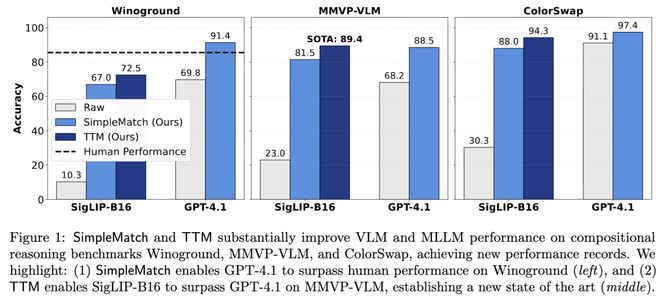
如上图所示,SimpleMatch揭示了模型中大量「被隐藏」的潜力——它让仅有0.2B参数的SigLIP-B16超越了此前所有结果,并使GPT-4.1首次在Winoground上超过人类表现。
Test-TimeMatching
在测试阶段自我迭代提升模型能力
为进一步提升模型表现,UCR研究团队提出了一种无需外部监督、能够自我改进的迭代算法Test-TimeMatching(TTM)。
每次迭代包括三个步骤:
1.模型对所有群组进行匹配预测;
2.仅保留置信度高的匹配(即得分差距超过阈值)作为伪标签,并在这些伪标签上自我微调;
3.随着迭代进行,逐步放宽阈值,以纳入更多样本。
TTM的核心在于两点:
1.基于GroupMatch的伪标签能更有效地利用群组结构,提供更强的监督信号;
2.阈值的逐步衰减机制让模型先从高置信数据学习,再逐步扩展覆盖范围。
这一算法可以看作测试时训练(test-timetraining)的一种形式,结合了自训练(self-training)、半监督学习(semi-supervisedlearning)和主动学习(activelearning)的思想。
从实验结果来看,TTM在多个数据集和模型上都稳定优于SimpleMatch:相对性能提升最高可达10.5%,相对错误率下降54.8%
值得注意的是,TTM让SigLIP-L16在ColorSwap数据集上提升至GPT-4.1的水平,并使SigLIP-B16(仅0.2B参数)在MMVP-VLM上超越GPT-4.1,刷新了当前最优结果。

TTM的广泛适用性
虽然前面的结果主要基于方形群组(k×k)的组合推理任务,但TTM同样适用于矩形群组,甚至是没有群组结构的数据集。
指标变化不带来提升的情况
在只有1×k结构的群组中,GroupMatch与GroupScore等价,因此单纯更换指标并不会改进结果。
即便如此,TTM在SugarCrepe和WhatsUp等数据集上依然带来了显著提升,其中在WhatsUp上的相对增幅高达85.7%,让原本困难的任务变得可解。
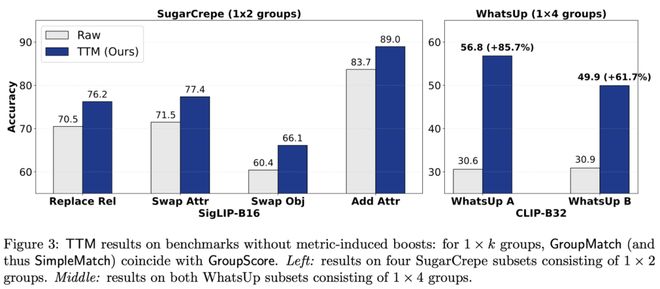
无群组结构的情况
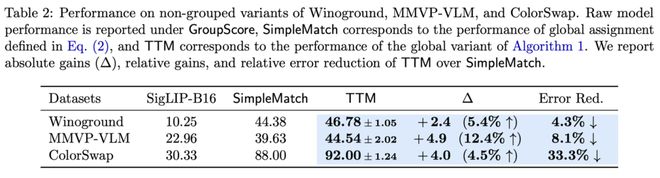
TTM还能将整个数据集视为一个全局的「图像-文本匹配问题」(assignmentproblem),并在多项式时间内求解。
即使将Winoground、MMVP-VLM和ColorSwap等数据集全部「打平」为无群组结构,TTM依然能显著提升表现,最高可带来33.3%的相对错误率下降。
讨论与展望
UCR研究团队重新审视了多模态模型在组合推理上的长期难题,指出:许多被认为的「失败」,其实源自评测指标的局限。
团队提出的GroupMatch指标与Test-TimeMatching(TTM)算法表明,模型的组合推理能力早已存在——只需要在测试阶段,用合适的方法将其「解锁」。
在覆盖16个不同数据集变体的系统实验中,TTM在多种设置下都展现出稳定而显著的改进,推动了多模态推理研究的前沿进展。
展望未来,团队认为有两个方向值得进一步探索:
参考资料: