[CL]《Scaling Latent Reasoning via Looped Language Models》R Zhu, Z Wang, K Hua, T Zhang... [ByteDance Seed] (2025)
深入解析Looped Language Models(LoopLM)如何通过递归循环计算,实现参数效率与推理能力的质的飞跃。
一、背景与创新
传统大语言模型(LLM)依赖不断增大模型参数和训练数据来提升能力,但带来成本高、部署难的问题。LoopLM提出了第三条路径:在固定参数预算下,通过循环复用共享层实现动态计算深度,提升推理能力和参数效率。该架构源自Universal Transformer,强调“隐式潜在推理”,迭代优化内部表示,而非简单堆叠层数。
二、核心技术亮点
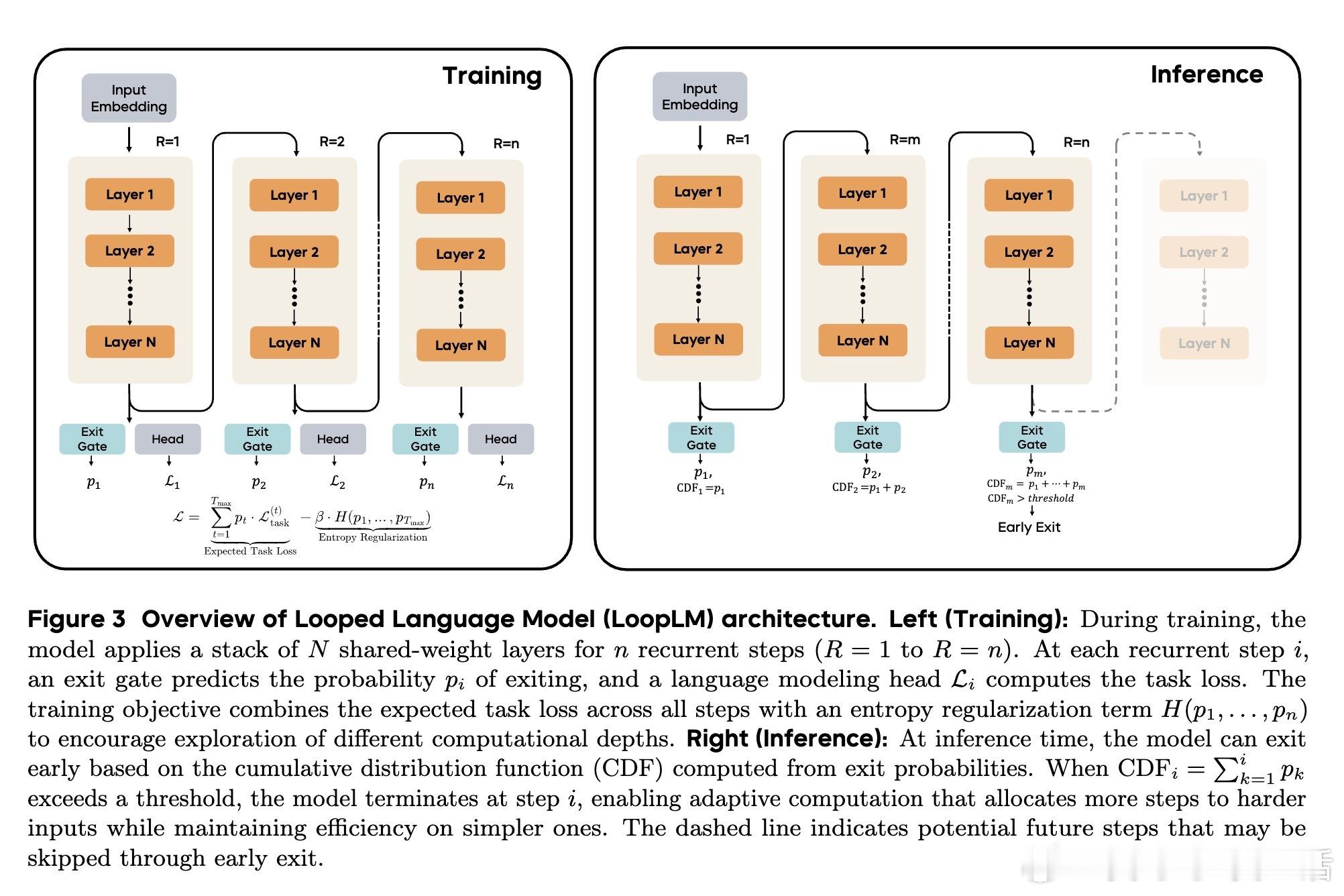
1. 结构设计:模型包括N层共享权重的Transformer块,循环应用t次(称为“循环深度”),每步通过门控机制自适应决定是否提前退出,兼顾效率与性能。
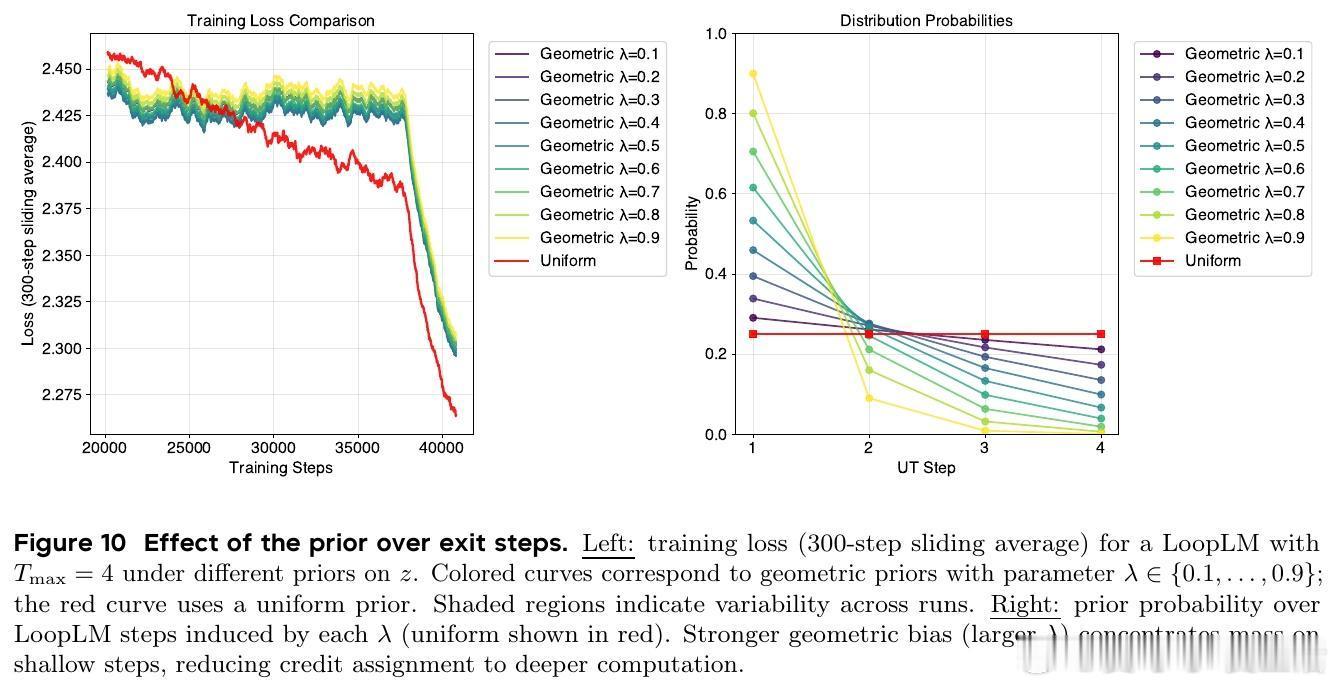
2. 训练目标:引入熵正则化的自适应深度学习目标,使用均匀先验鼓励探索所有循环深度,避免过早偏向浅层计算。
3. 两阶段门控训练:阶段一联合训练语言模型与退出门,阶段二专注门控优化,衡量迭代带来的性能提升指导退出决策。
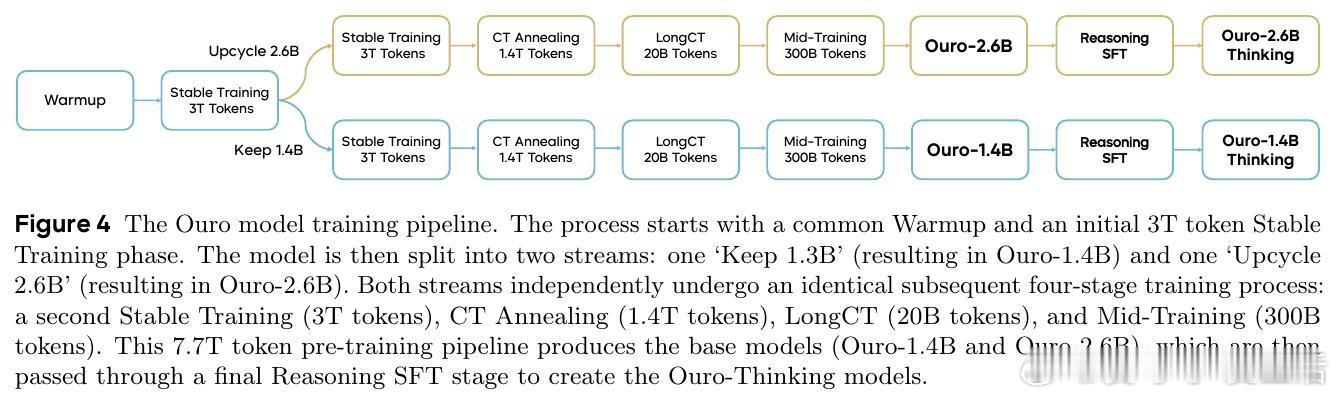
4. 训练规模:预训练7.7万亿token,涵盖多阶段数据和长上下文,支持1.4B和2.6B参数模型,兼顾稳定性与规模化。
5. 推理优化:提出KV缓存重用策略,减少循环步骤带来的内存开销,实现实用部署。
三、实验成果
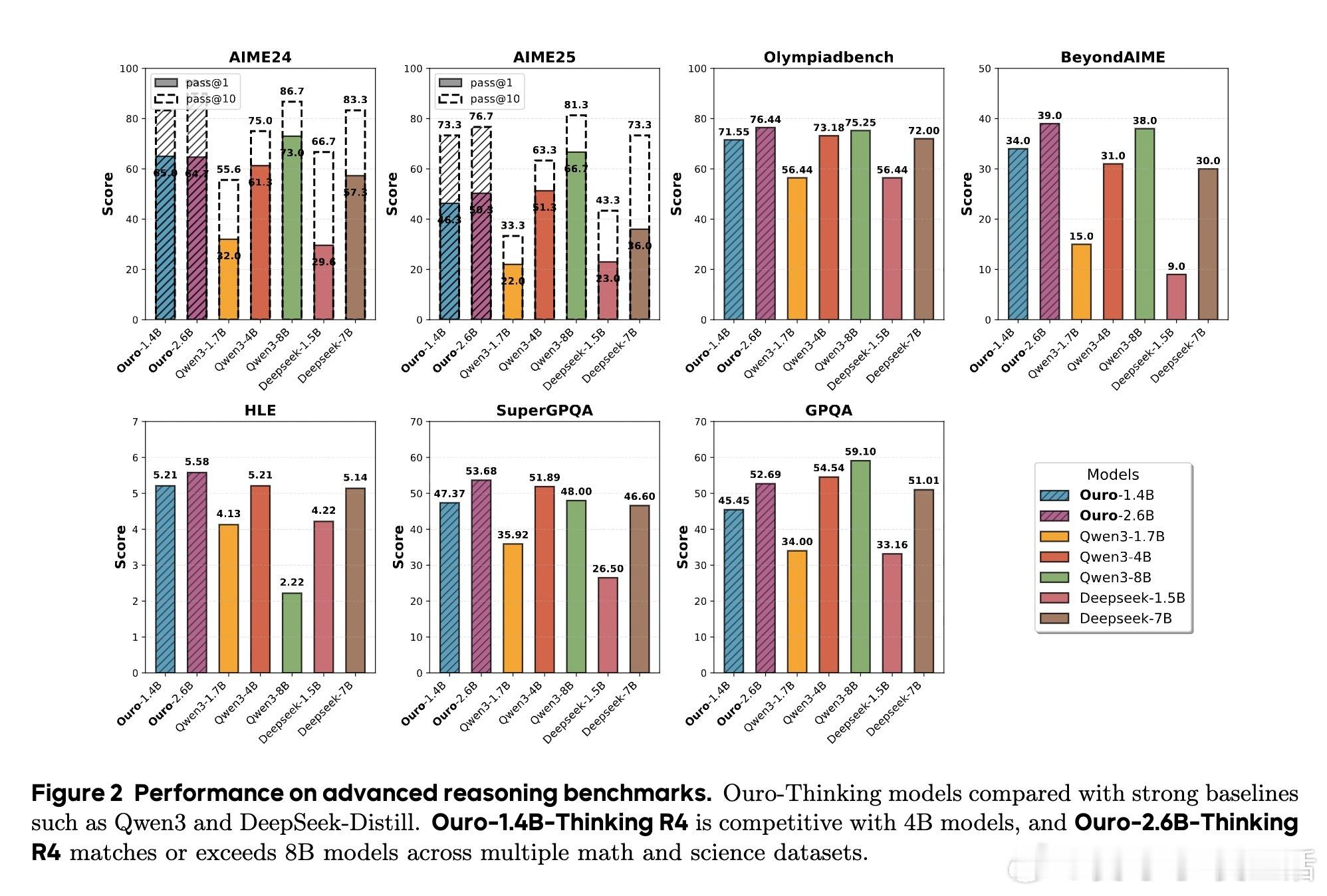
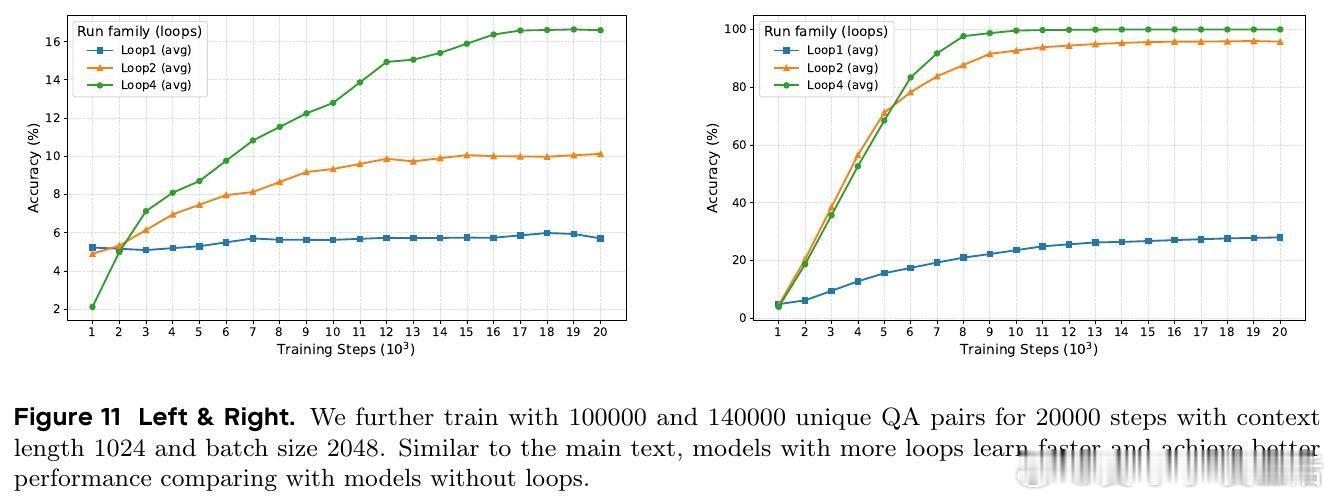
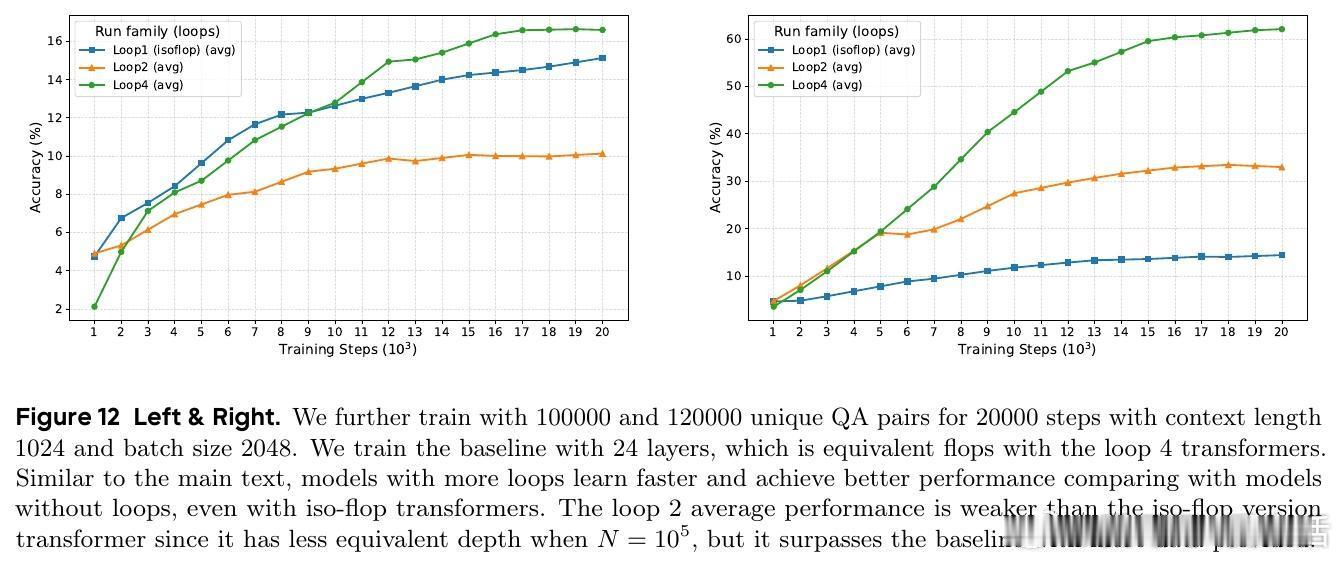
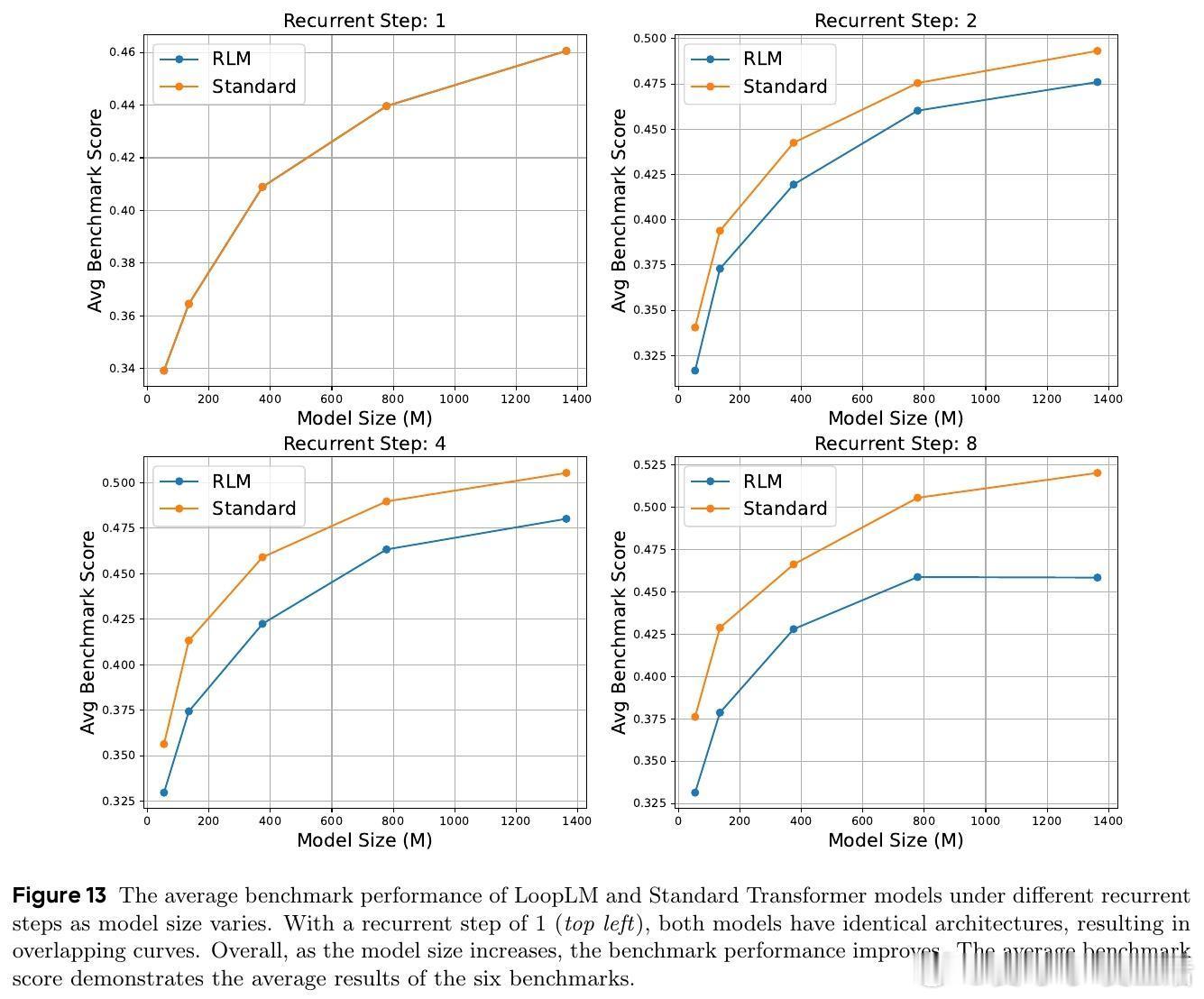
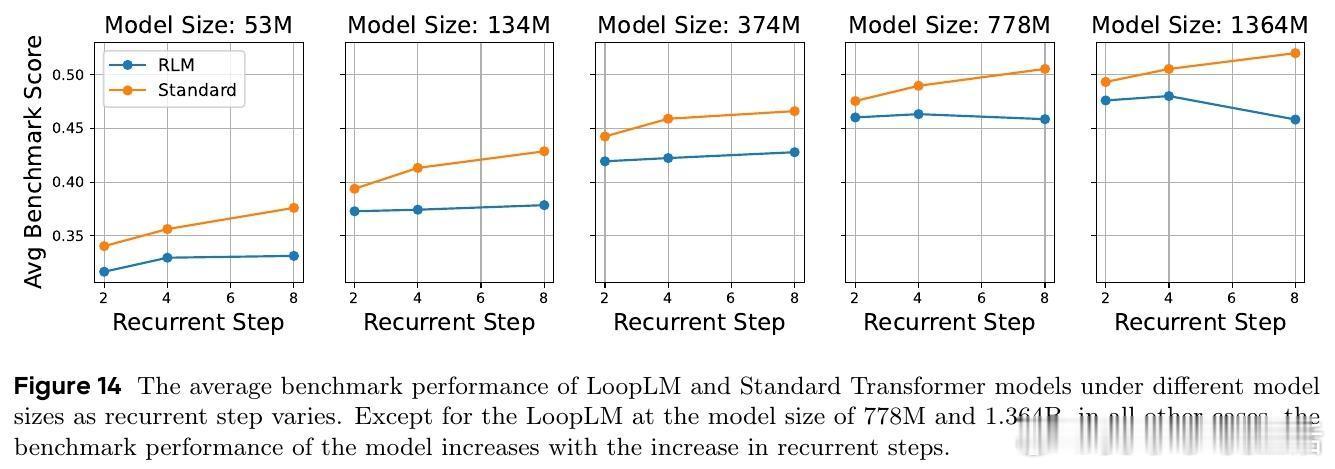
1. 参数效率显著:1.4B和2.6B LoopLM模型性能相当于4B和8B传统Transformer,参数效率提升2-3倍。
2. 推理能力提升:在多项数学、科学和多跳推理基准(如MMLU-Pro、BBH、GSM8K、AIME)中,循环模型优于同参数传统模型,且超过更大规模对标模型。
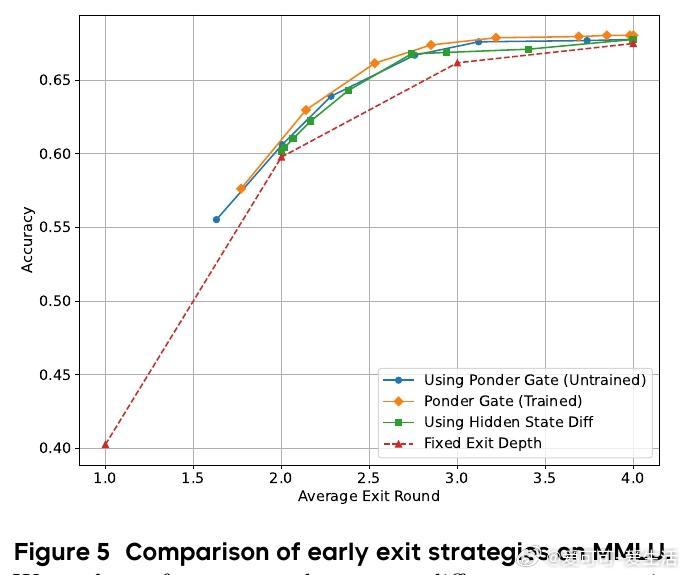
3. 自适应推理:训练的门控机制能根据输入难度自适应调整循环深度,实现更优的计算-性能平衡。
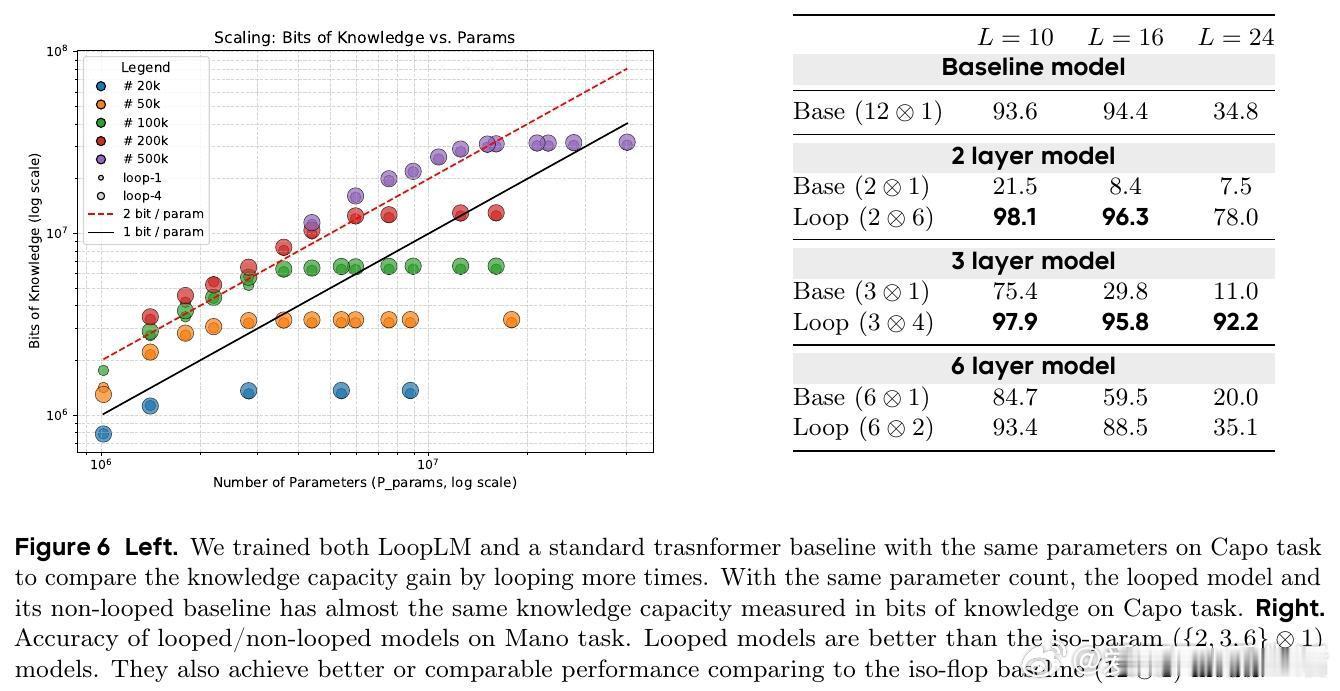
4. 机制解析:循环并未提升知识存储容量(约2 bits/参数),而是显著增强了知识操作和组合能力,尤其对多步推理任务表现突出。
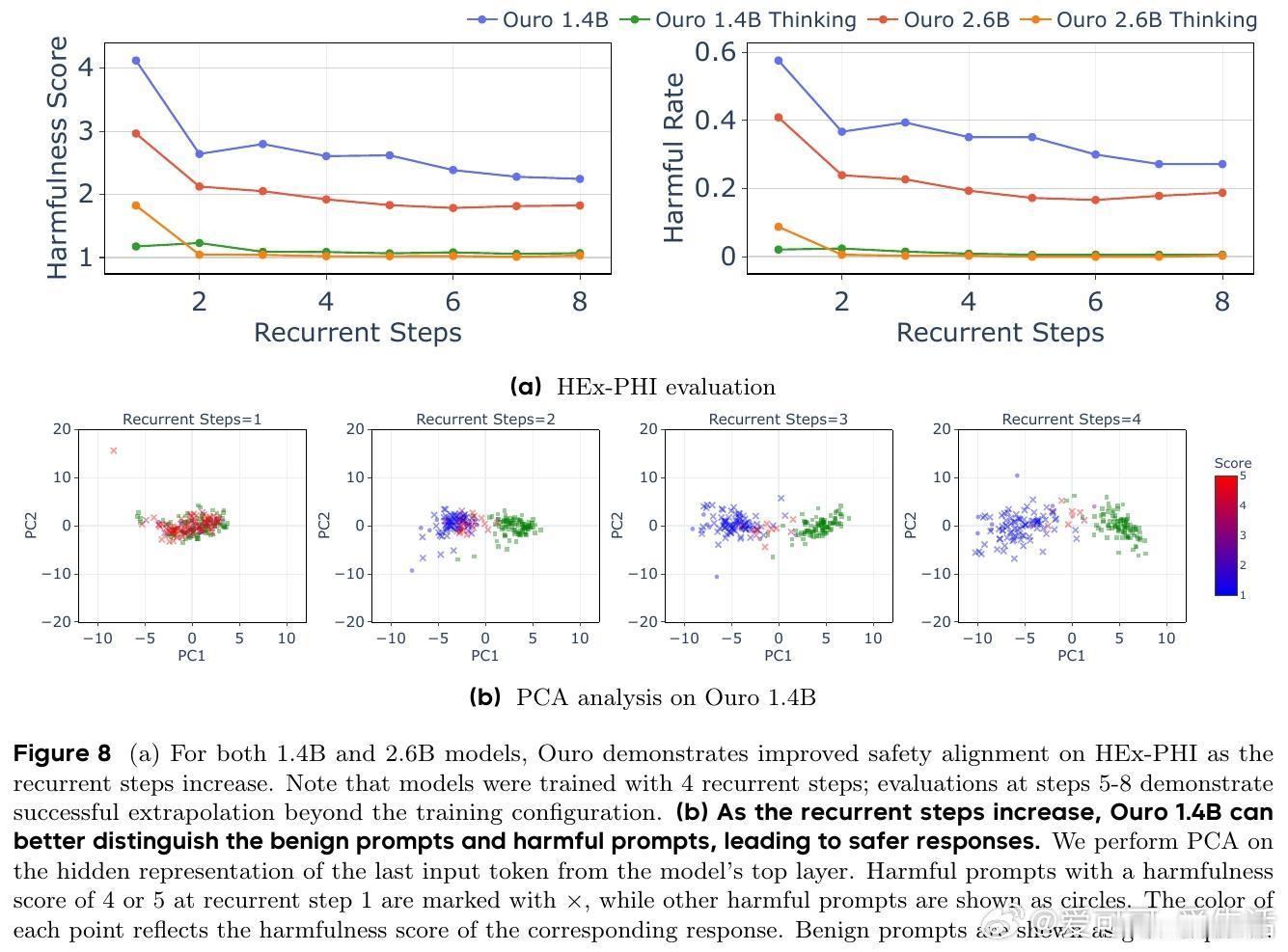
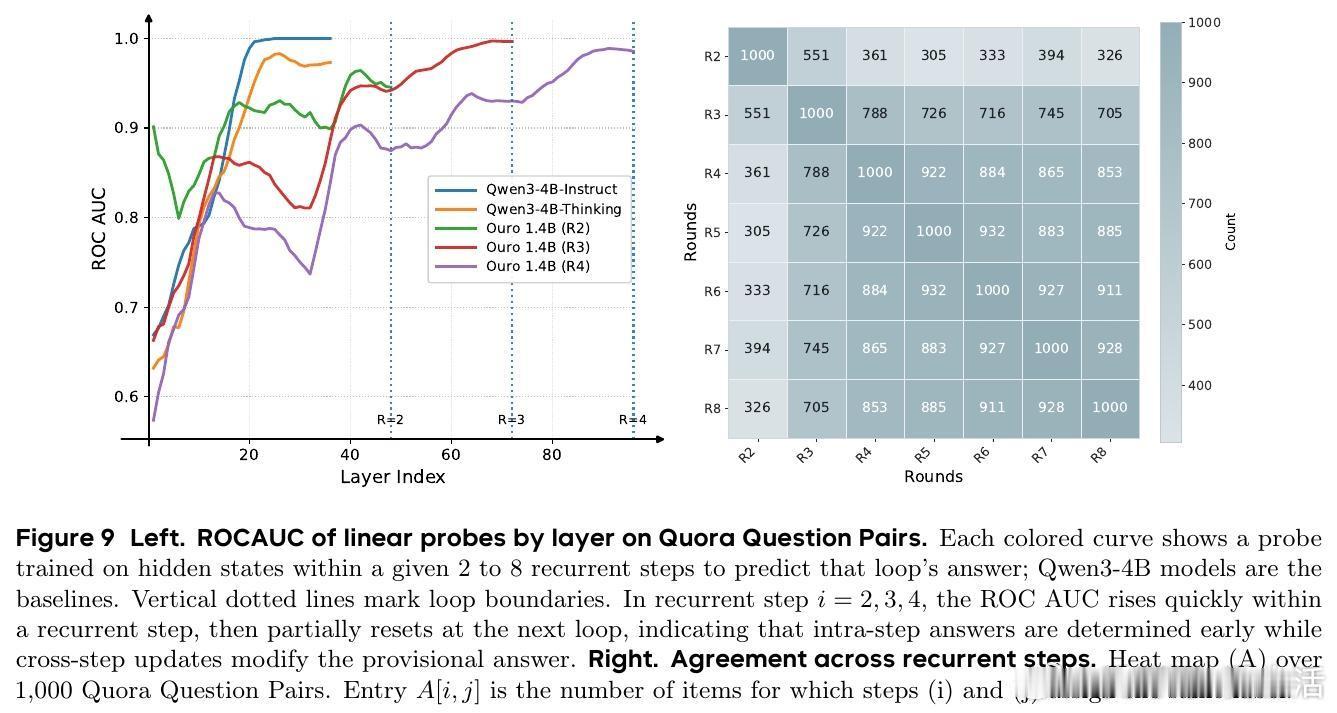
5. 安全与可信度:循环深度增长提升模型区分有害与无害输入的能力,减少错误和有害输出,且推理过程更具因果连贯性,避免传统CoT的事后合理化问题。
四、理论分析
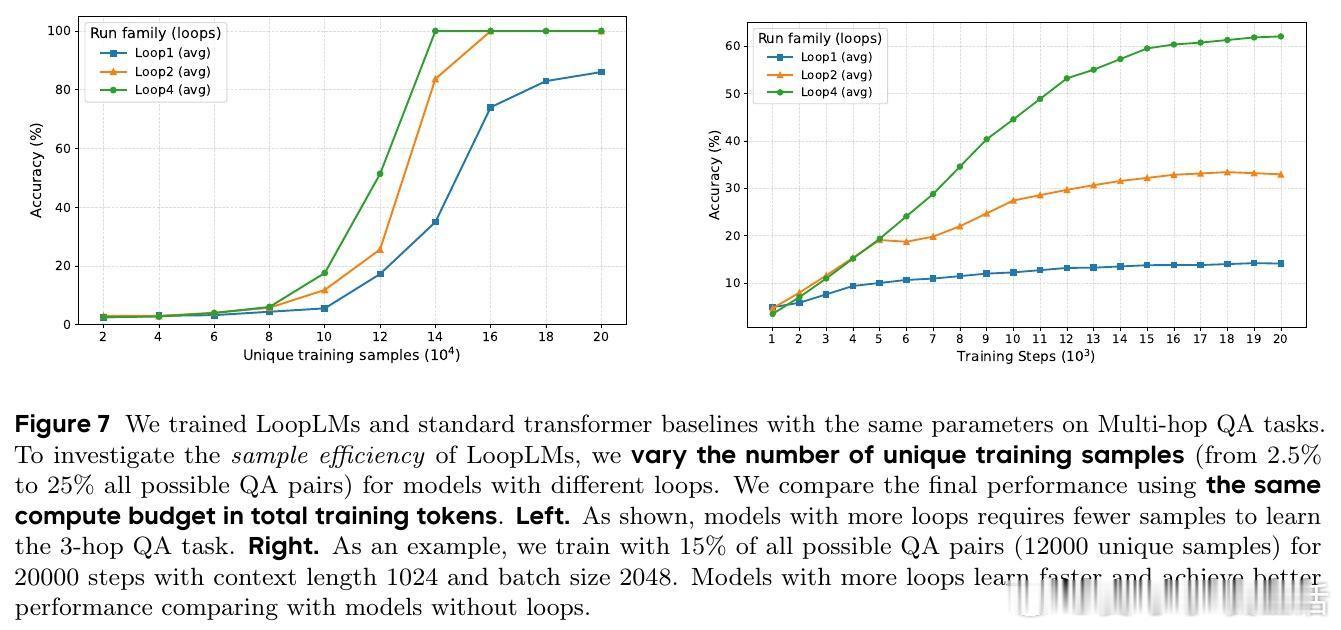
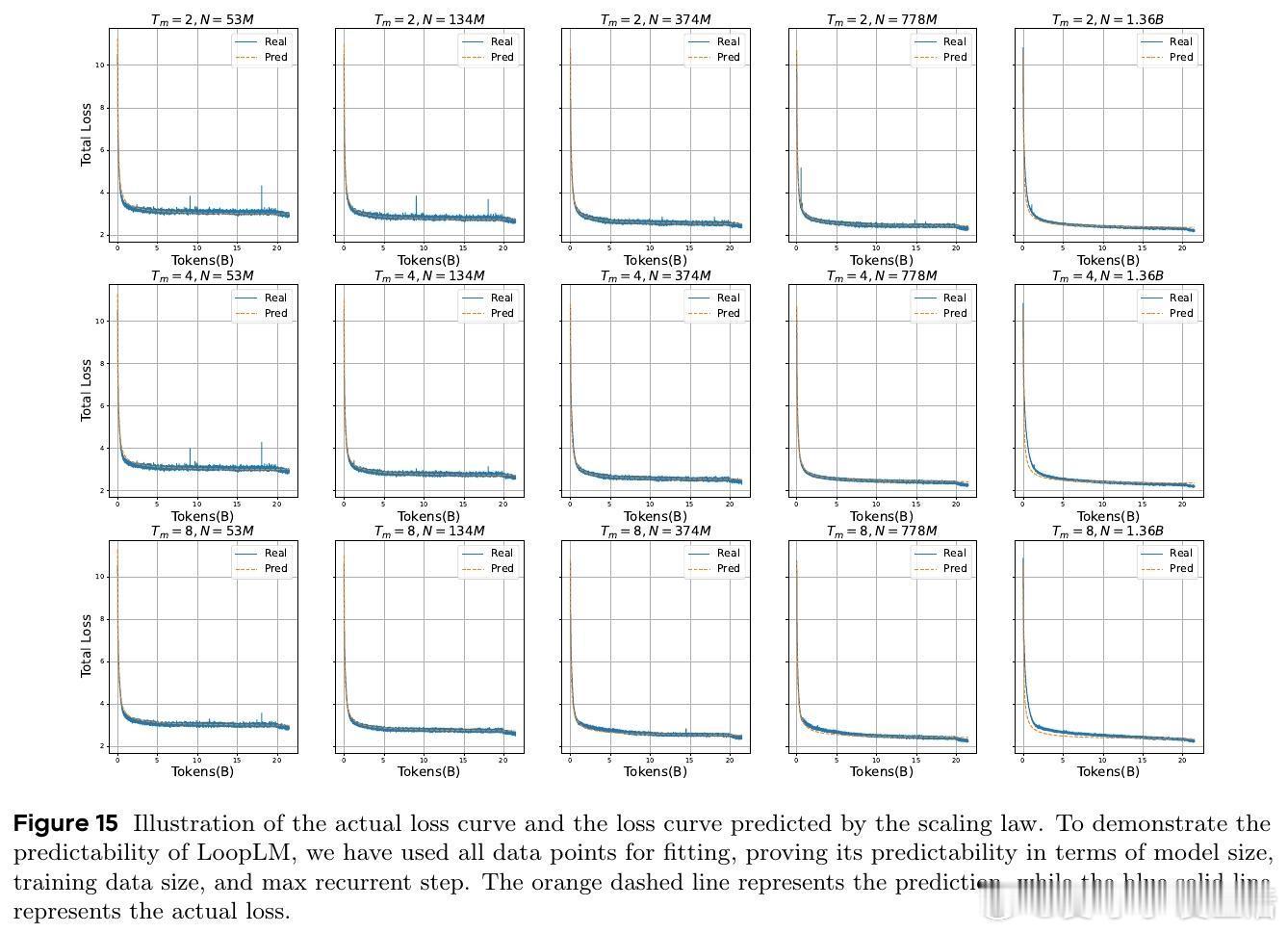
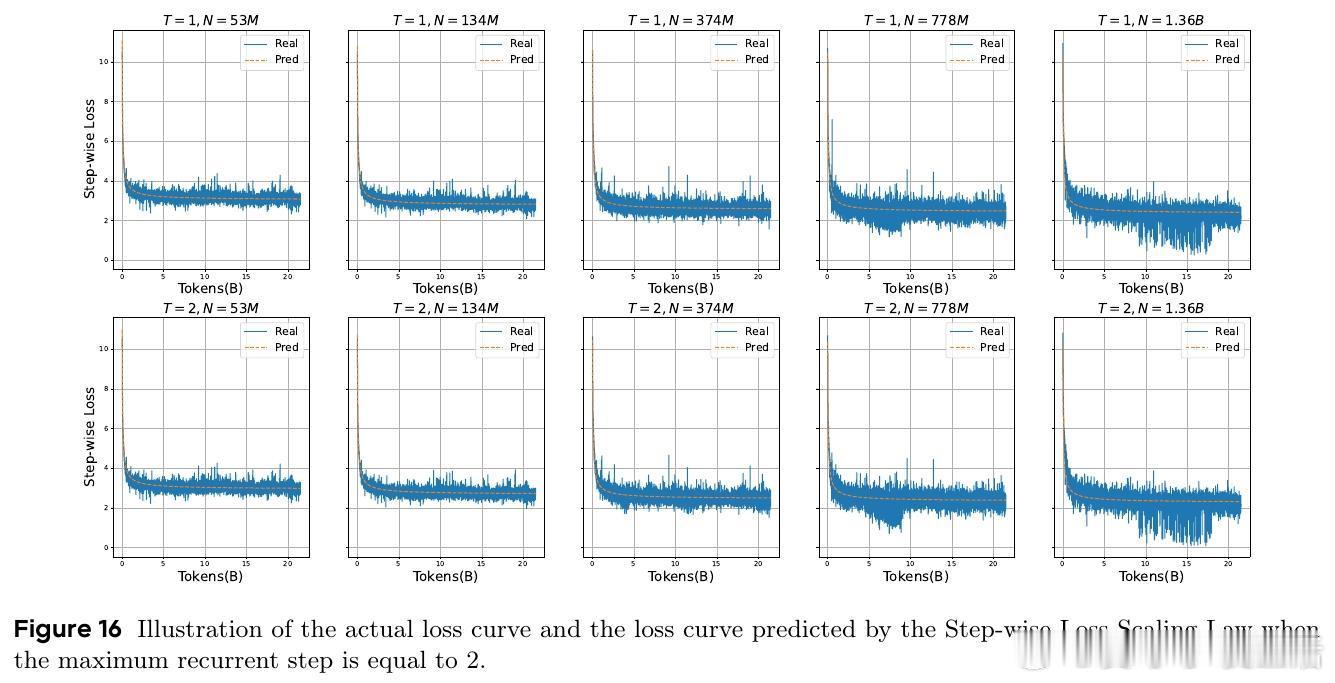
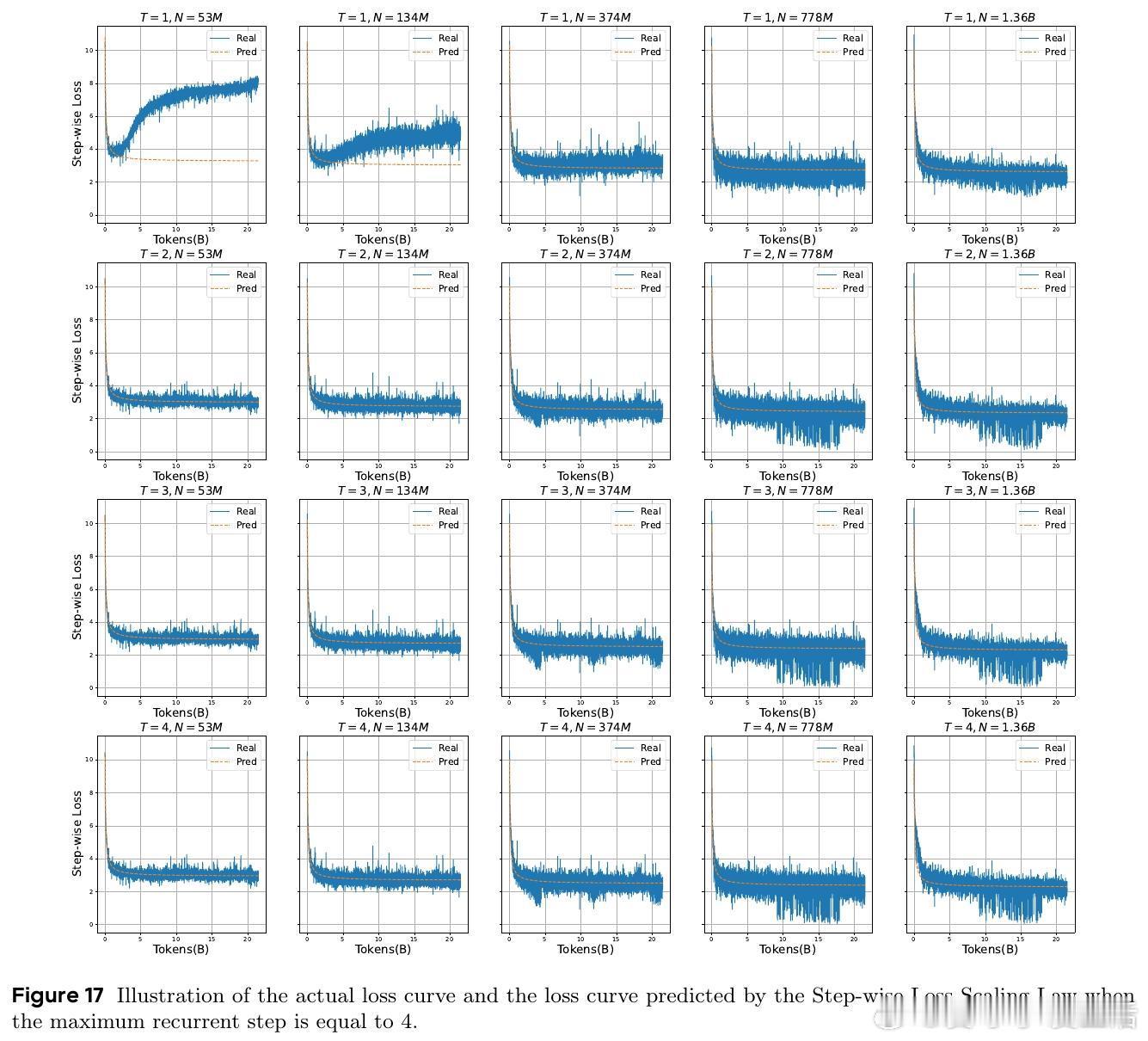
证明LoopLM能在对数级别递归深度内完成复杂图结构的路径可达性判定,极大缩短推理所需顺序步骤数,展现超越传统CoT的潜力。且循环结构通过参数共享缩小假设空间,提升样本效率。
五、应用前景
LoopLM代表了推理时代的新型扩展维度——“递归深度”,与参数量和数据量并列。其高效的参数利用和动态计算机制,适合资源受限环境部署,并为安全、可信的AI推理提供架构保障。未来可进一步探索更深递归和复杂循环机制,推动高效推理模型的实用化。
项目开源地址:
总结:
LoopLM通过循环复用Transformer层实现了参数级别的推理能力爆发,突破了单纯依赖模型规模扩张的瓶颈。其创新的训练机制和推理架构,为构建更智能、更高效、更安全的大模型开辟了新方向,值得AI研发者和研究者重点关注。
原论文全文详见:arxiv.org/abs/2510.25741