[LG]《Discovering state-of-the-art reinforcement learning algorithms》J Oh, G Farquhar, I Kemaev, D A. Calian... [Google DeepMind] (2025)
谷歌DeepMind团队推出了自动发现强化学习(RL)算法的新方法——DiscoRL,实现了超越人类设计规则的性能。通过让大量智能体在多样复杂环境中自主“进化”学习规则,DiscoRL不仅在经典Atari游戏中表现优异,还在未见过的挑战性任务中展现出强大泛化能力。
核心亮点:
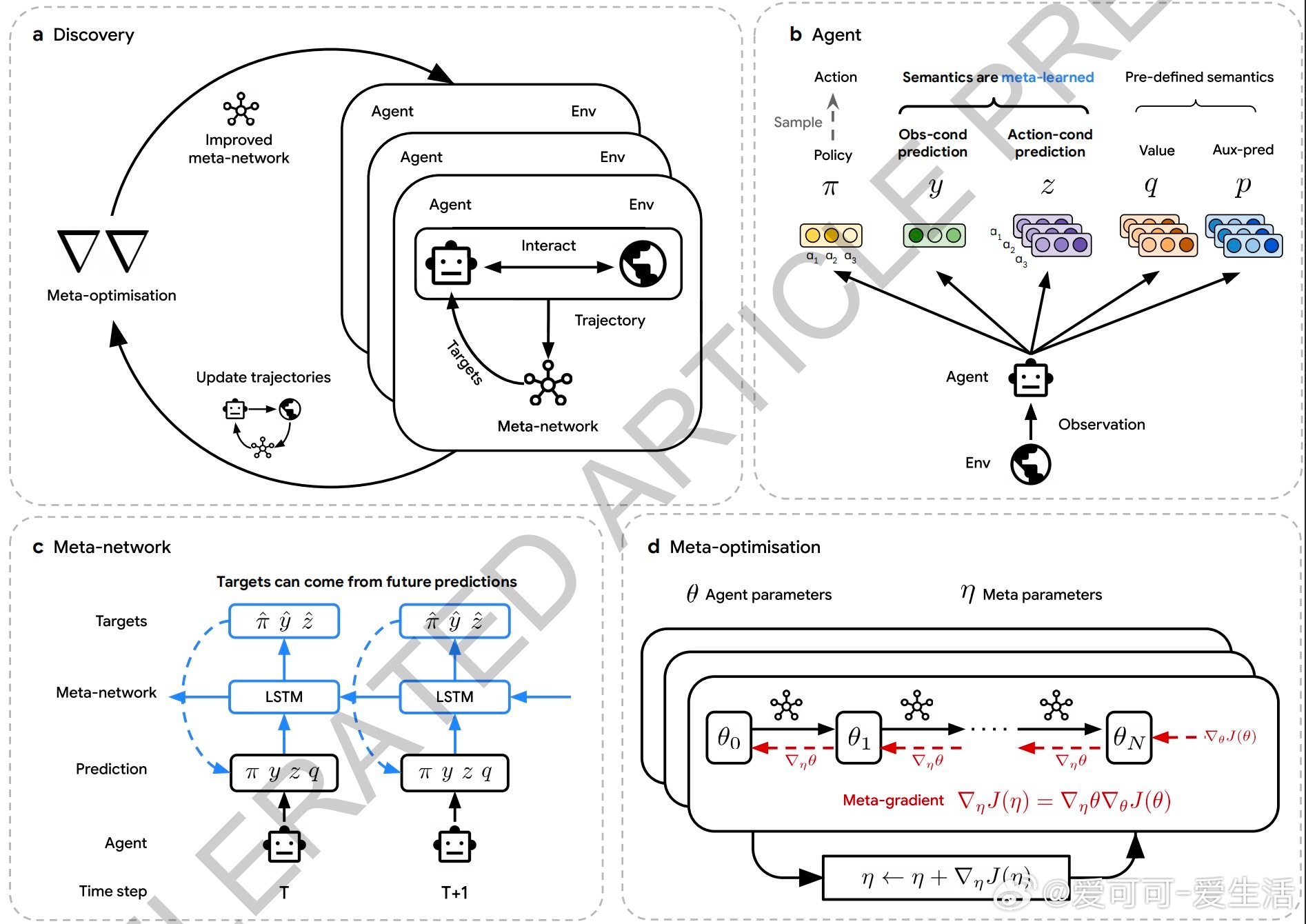
1. 自动发现RL算法:不同于传统依赖人工设计规则,DiscoRL通过元学习(meta-learning)从大量智能体经验中自动提炼更新策略和预测的规则。
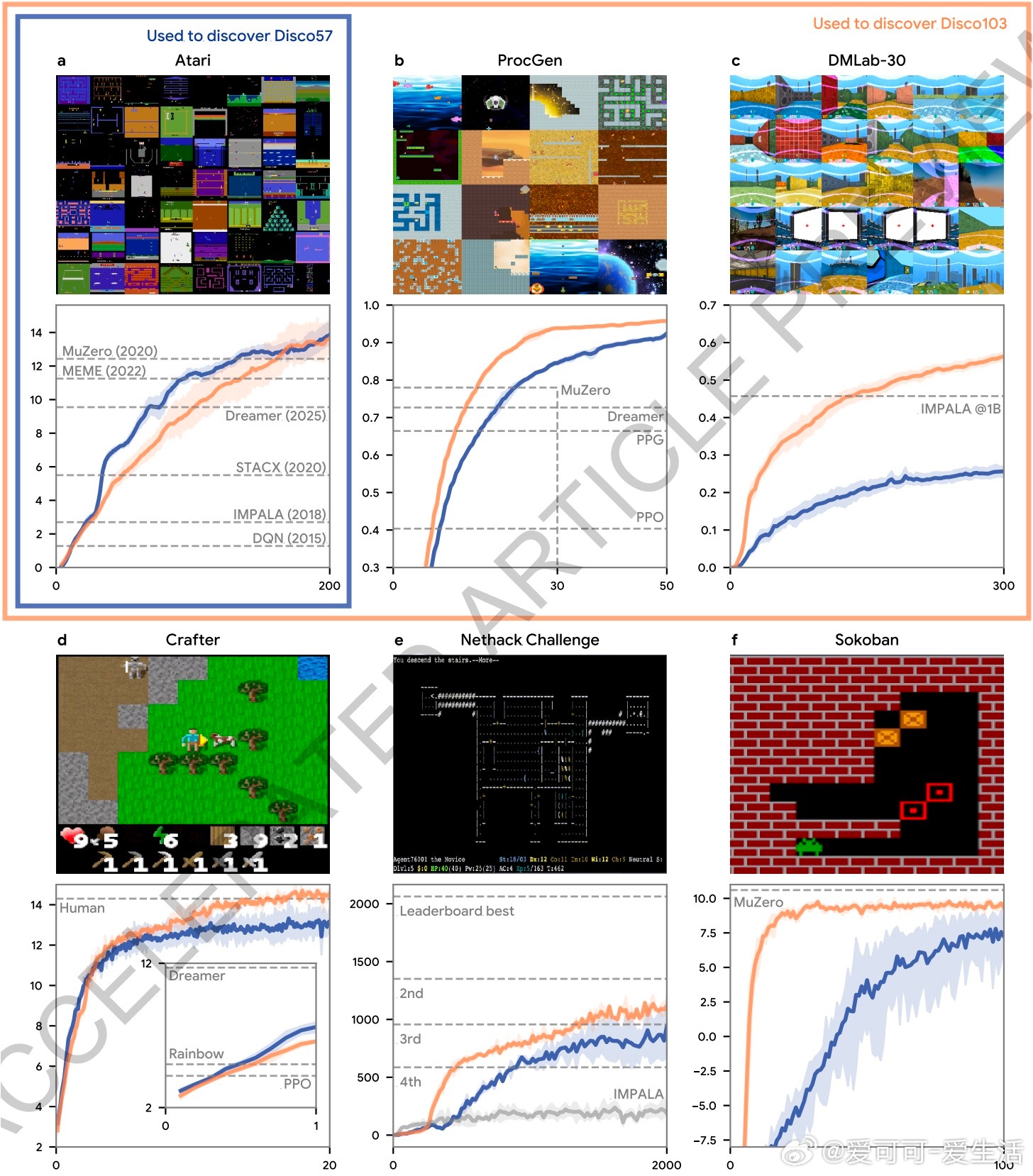
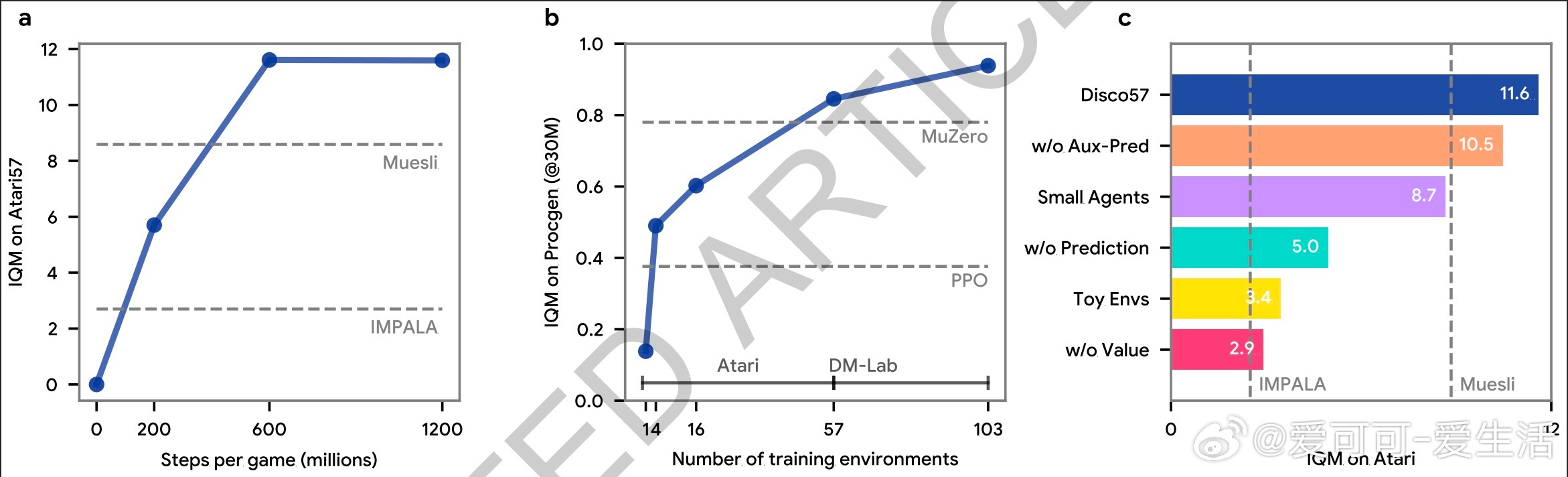
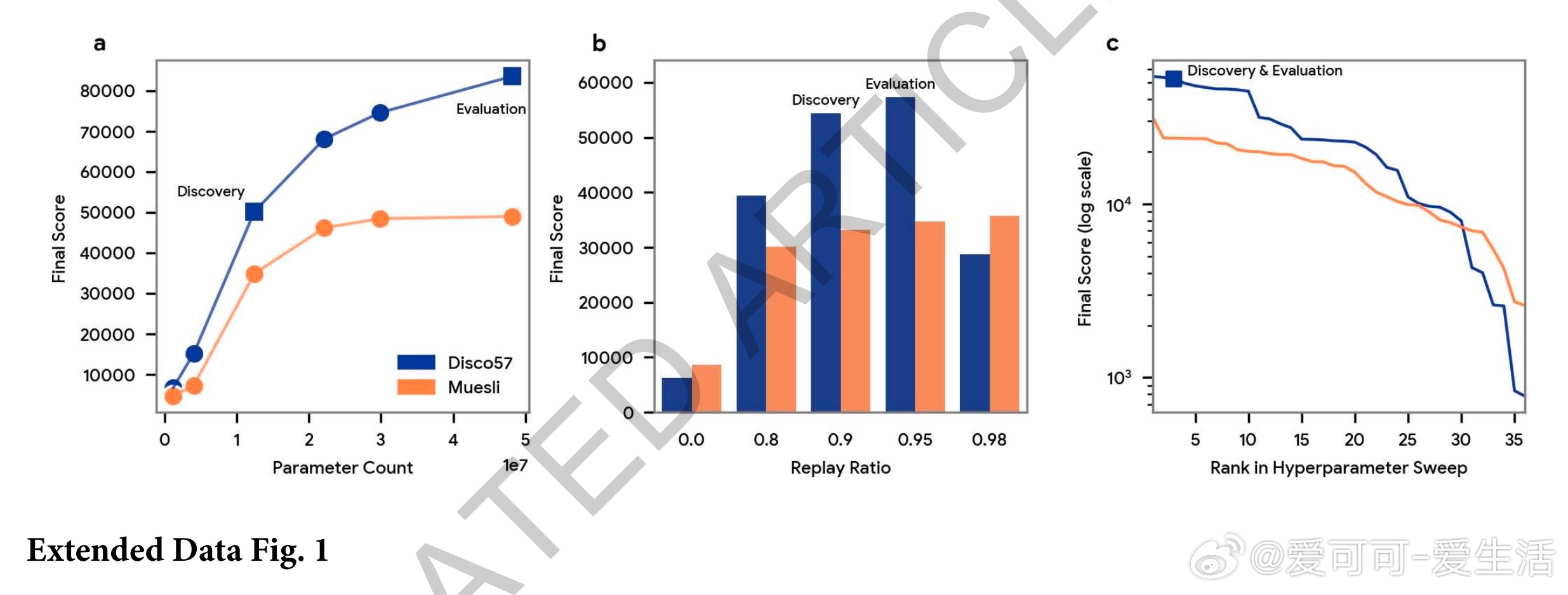
2. 广泛适用且高效:在57款Atari游戏上击败MuZero等顶尖算法,且计算效率提升约40%。在ProcGen、Crafter、NetHack等多种未见环境中也表现优异。
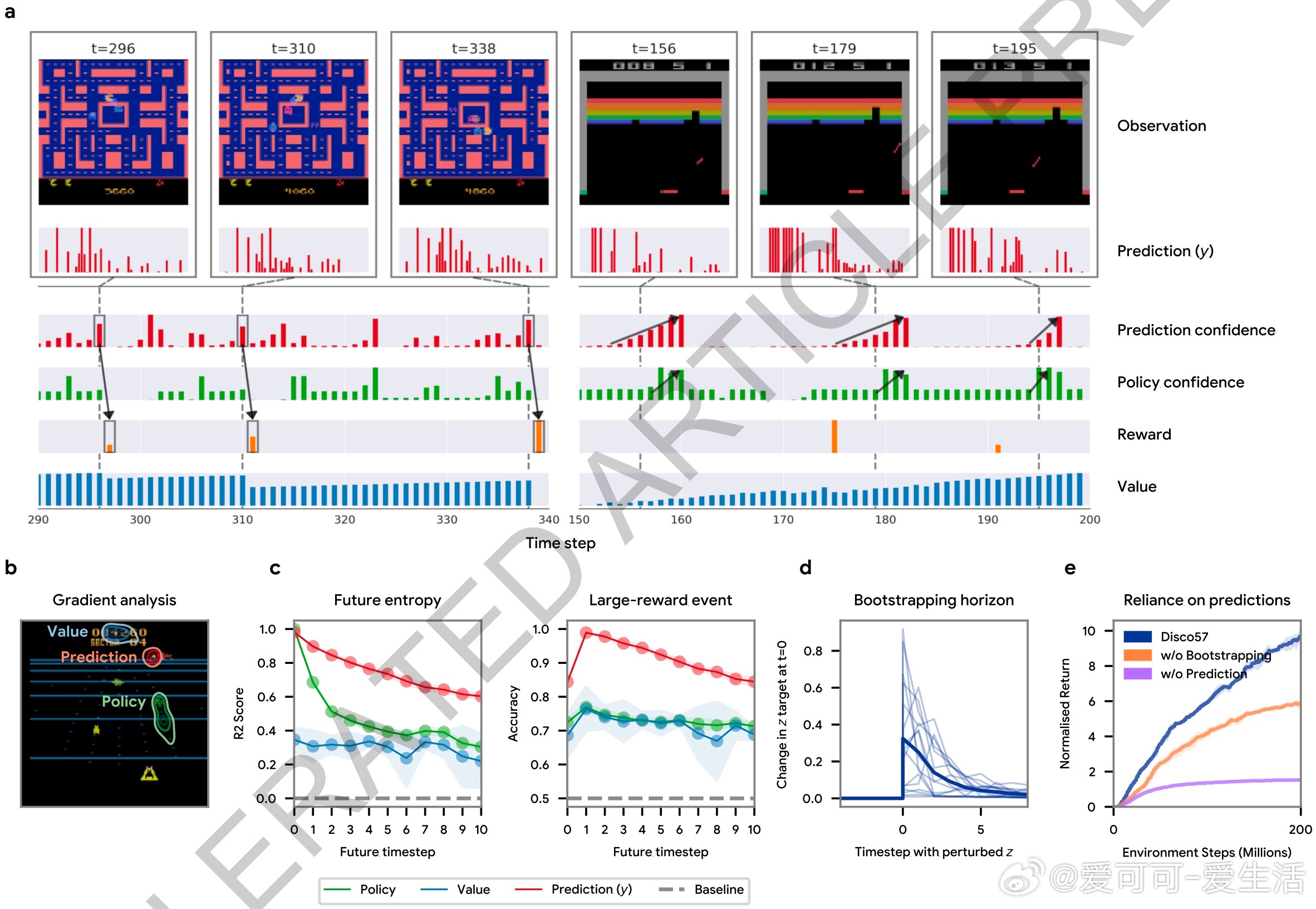
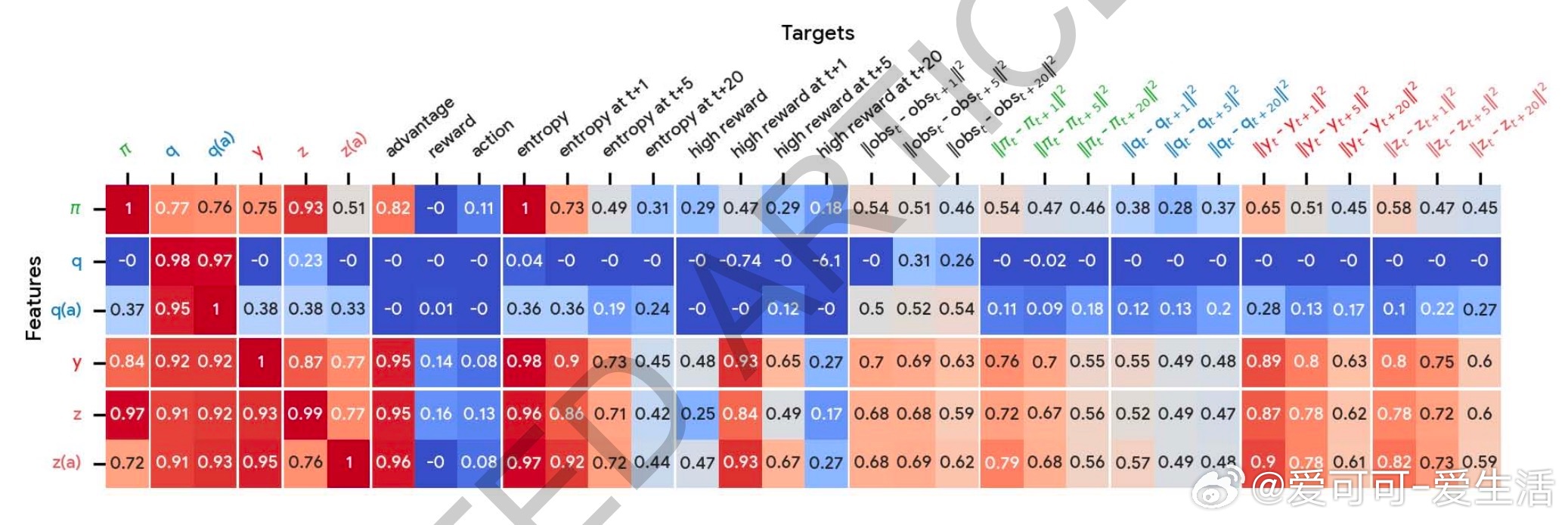
3. 丰富预测机制:智能体不仅预测价值函数,还自主发现新的预测语义,捕捉未来奖励和策略熵等关键信息,辅助决策更精准。
4. 引入元网络设计:采用LSTM处理智能体轨迹和奖励信息,动态生成更新目标,支持复杂动作空间和多样代理架构,提升算法通用性。
5. 规模化训练:利用TPU集群并行训练数百个智能体,在多样环境中持续迭代优化元参数,实现快速且稳定的规则发现。
研究启示:
- 复杂多样的训练环境对发现更强泛化规则至关重要,简单环境难以驱动出高效算法。
- 机器自动设计学习规则可能成为未来AI发展的主流,突破了人类设计的瓶颈,实现持续自我进化。
- 发现的新算法不仅提升性能,还揭示了强化学习中未曾重视的预测结构和引导策略更新的新机制。
未来展望:
这项工作标志着人工智能从“人设计算法”迈向“机器自发现算法”,为开发更智能、更高效、更通用的学习系统奠定基础。随着计算资源和环境多样性的增加,自动发现的RL算法将不断进化,推动AI达到前所未有的高度。
详细阅读论文:
nature.com/articles/s41586-025-09761-x
强化学习 元学习 人工智能 DeepMind DiscoRL 自动算法设计