[LG]《The Free Transformer》F Fleuret [FAIR at Meta] (2025)
本文提出了一种创新的Transformer扩展方法,称为Free Transformer。
核心思想:
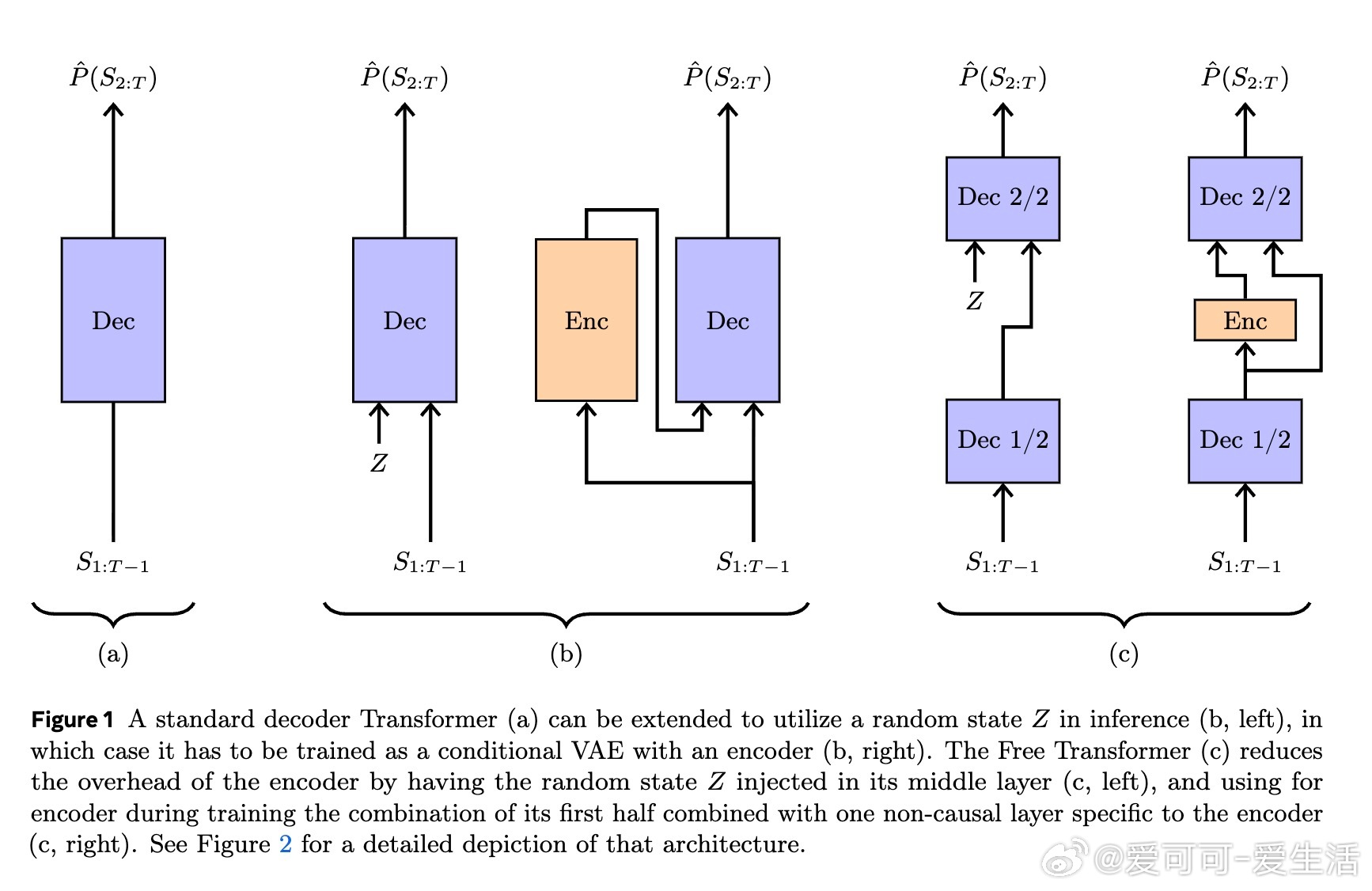
传统Decoder Transformer通过自回归方式生成序列,逐步预测下一个token,所有决策仅基于已生成的token,缺少显式的潜变量建模。Free Transformer引入无监督学习的随机潜变量Z,借助条件变分自编码器(Conditional VAE)框架,使生成过程可显式依赖于潜变量,从而捕获序列更丰富的结构信息。
技术亮点:
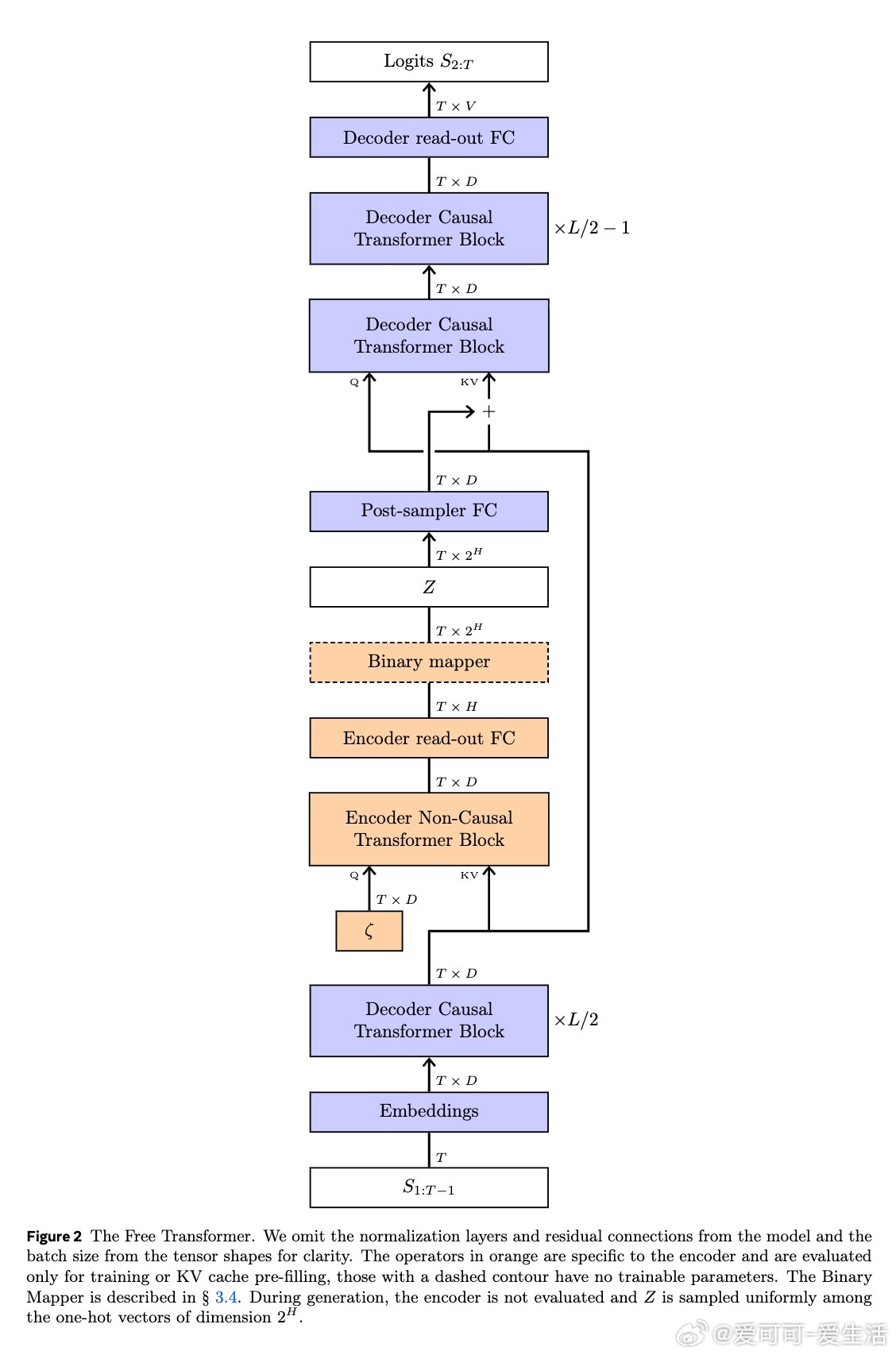
- 在Transformer中途层注入潜变量Z,兼顾编码器和解码器功能,计算和内存开销仅增加约3%。
- 设计了专门的非因果编码器块和二进制映射层,保证训练稳定并有效传递梯度。
- 通过自由比特(free bits)策略控制KL散度,防止潜变量信息过度泄露导致模型崩溃。
实验验证:
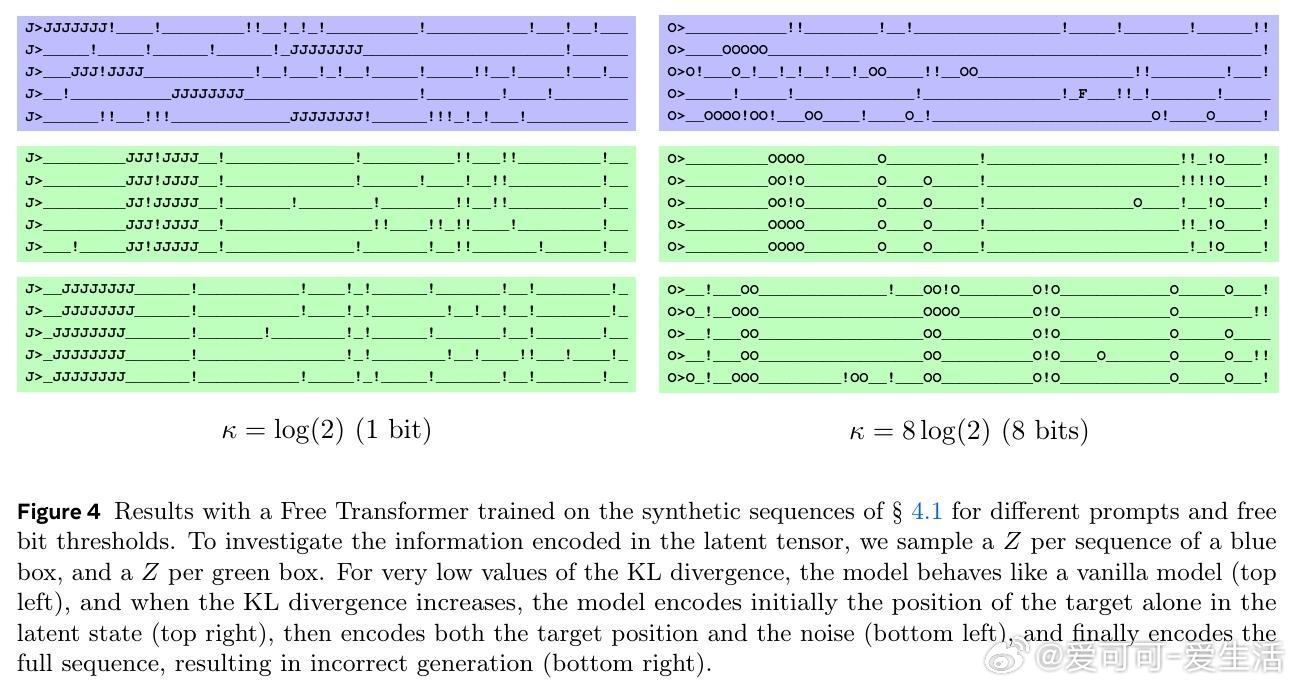
- 在合成数据任务中,Free Transformer能成功编码序列中关键结构(如目标位置),展现潜变量效果。
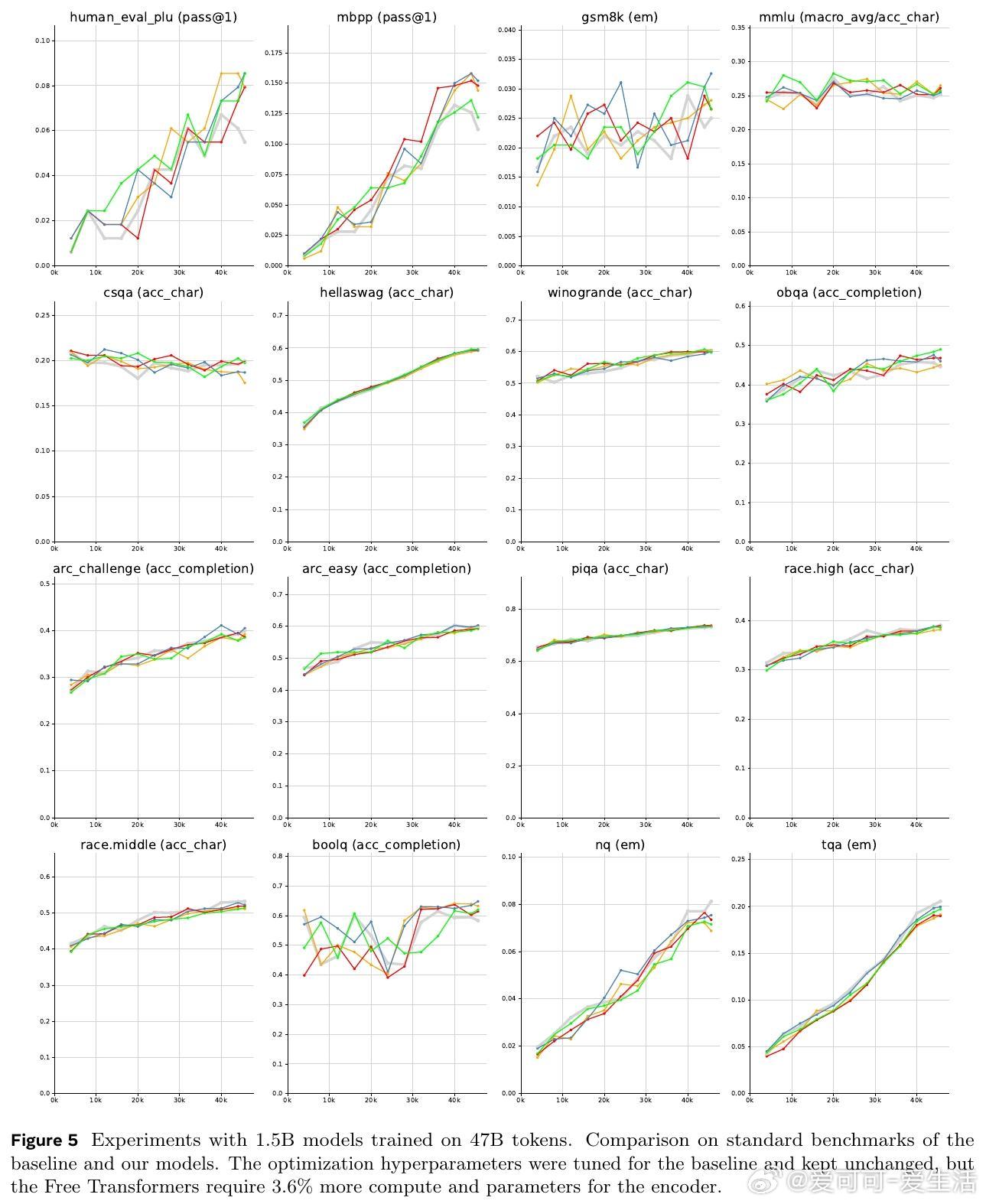
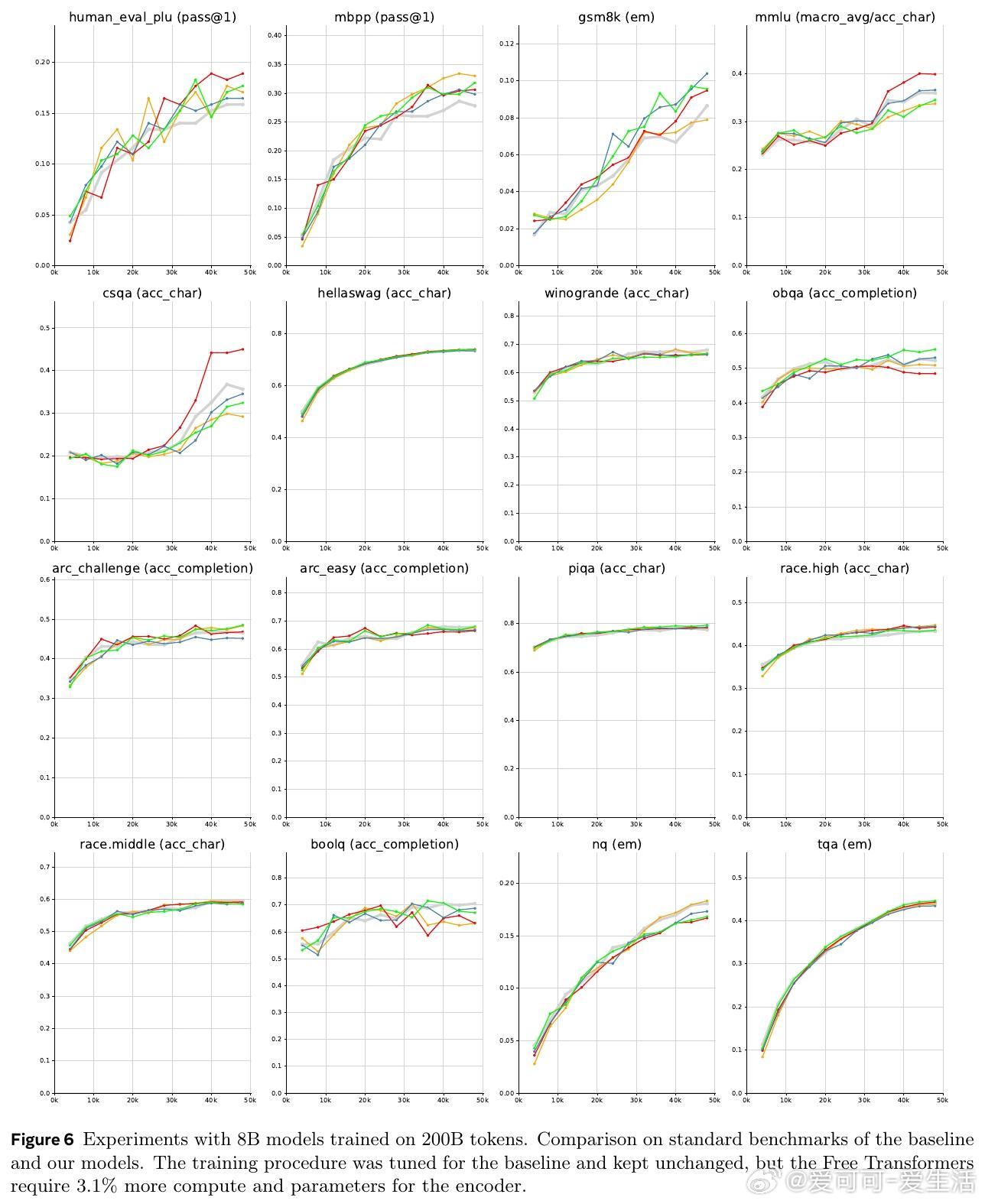
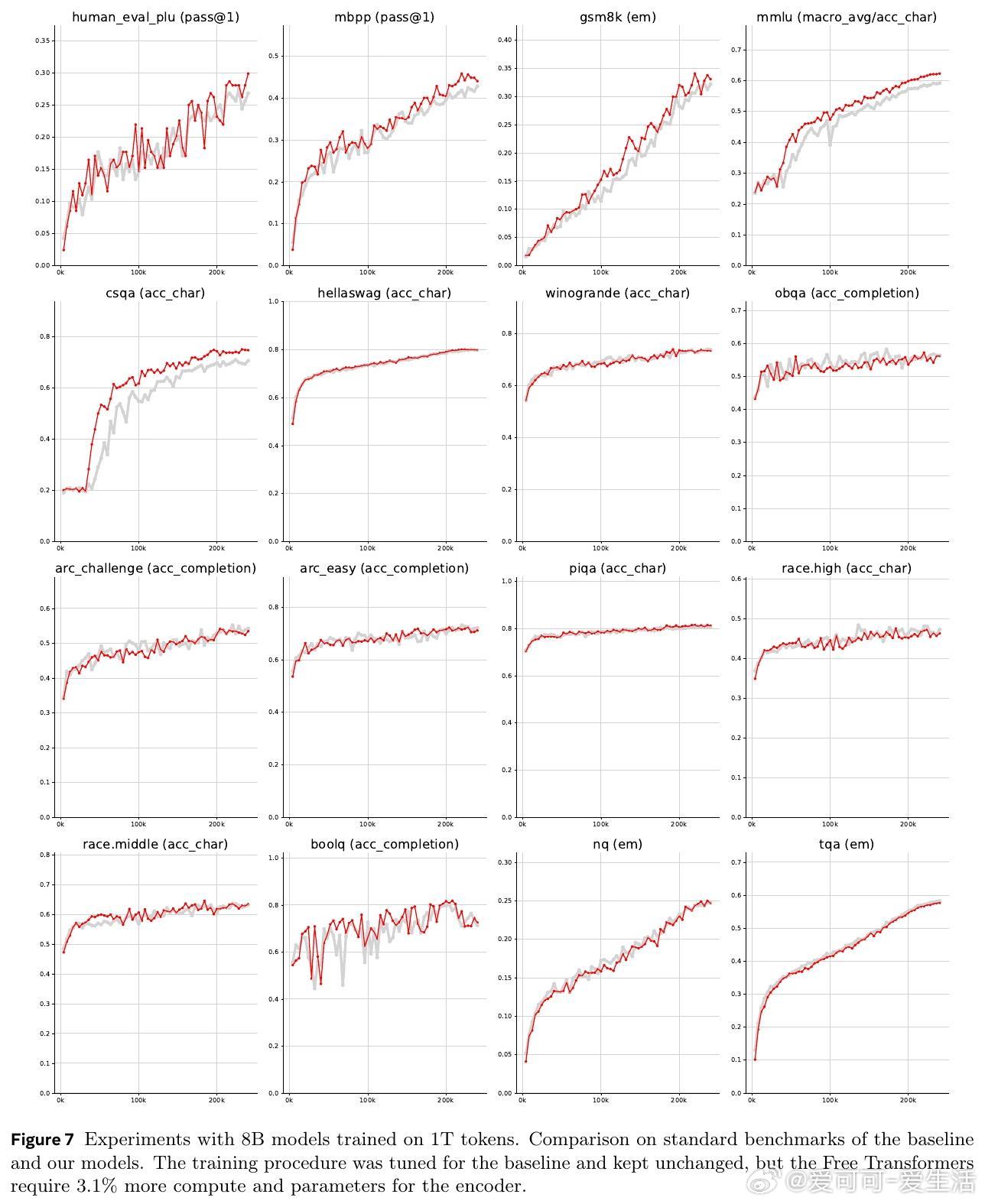
- 1.5B和8B参数模型在多项NLP和编程任务(HumanEval+、MBPP、GSM8K、MMLU等)上显著优于传统Transformer,尤其在需要推理的任务上提升明显。
- 8B模型在训练1万亿tokens后,进一步验证了Free Transformer的稳定性和性能提升。
意义与展望:
此方法突破了自回归模型对序列生成的限制,允许模型在潜空间中做出更自然的全局决策,类似于引入“隐式思维链条”。Free Transformer为未来结合链式推理与潜变量建模开辟了新方向,有望推动更高效、更智能的生成模型发展。
论文链接:arxiv.org/abs/2510.17558
Transformer VAE 机器学习 自然语言处理 生成模型 MetaFAIR