[LG]《Thoughtbubbles: an Unsupervised Method for Parallel Thinking in Latent Space》H Liu, S Murty, C D. Manning, R Csordás [Stanford University] (2025)
Thoughtbubbles:无需额外监督,变革性实现Transformer隐空间中的并行自适应思考
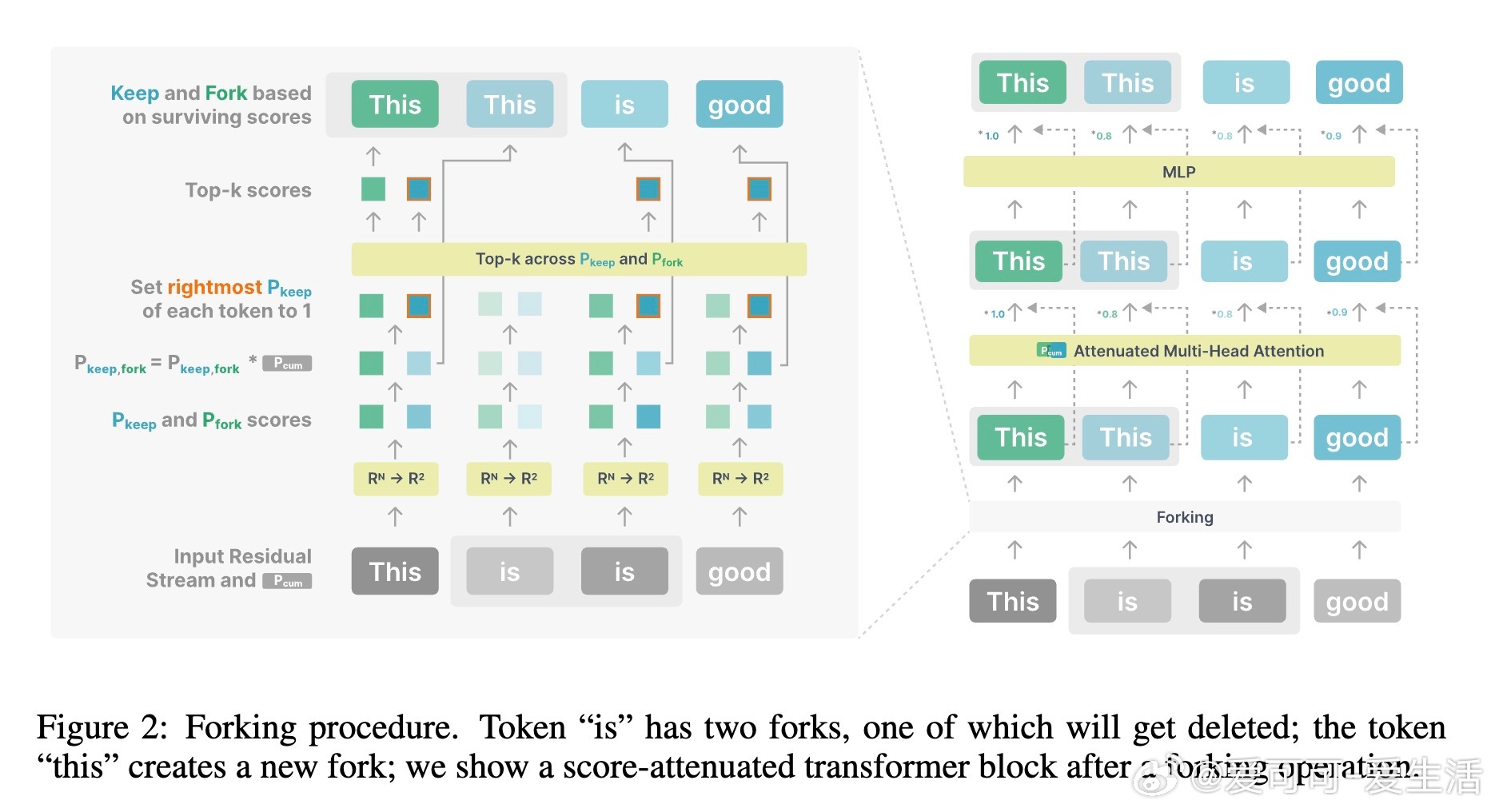
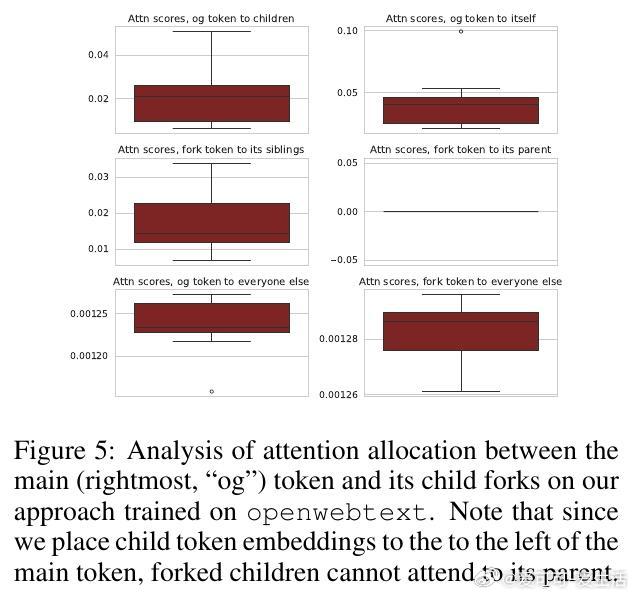
• 创新架构:Thoughtbubbles引入“forking”机制,动态复制或删减残差流,形成隐空间中针对复杂Token的“思考泡泡”,实现推理时的并行计算。
• 无需额外信号:该模型仅凭语言建模损失,在预训练阶段即学会自适应分配计算资源,无需人工设计的思考链或暂停令牌。
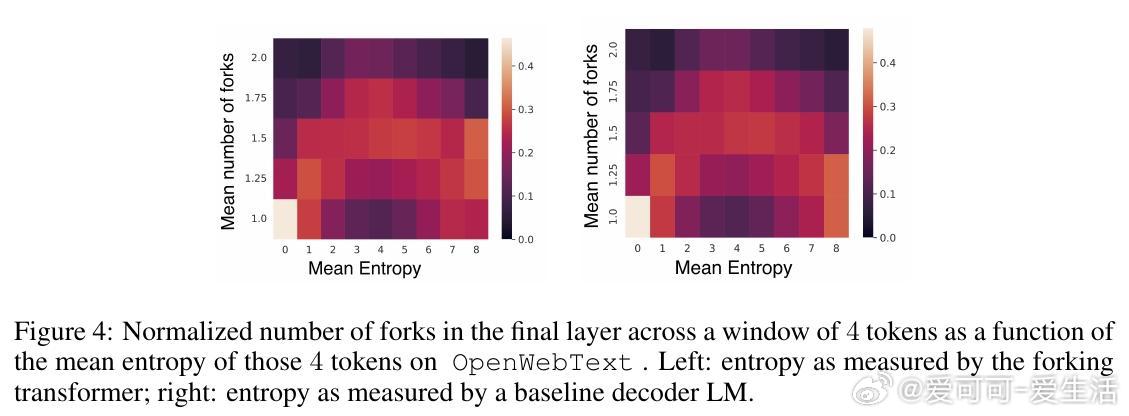
• 计算资源自适应:模型根据Token不确定性(如后验熵)智能调整计算量,重点“加思考”,而对极端不确定区域反而节约资源,提升效率和效果。
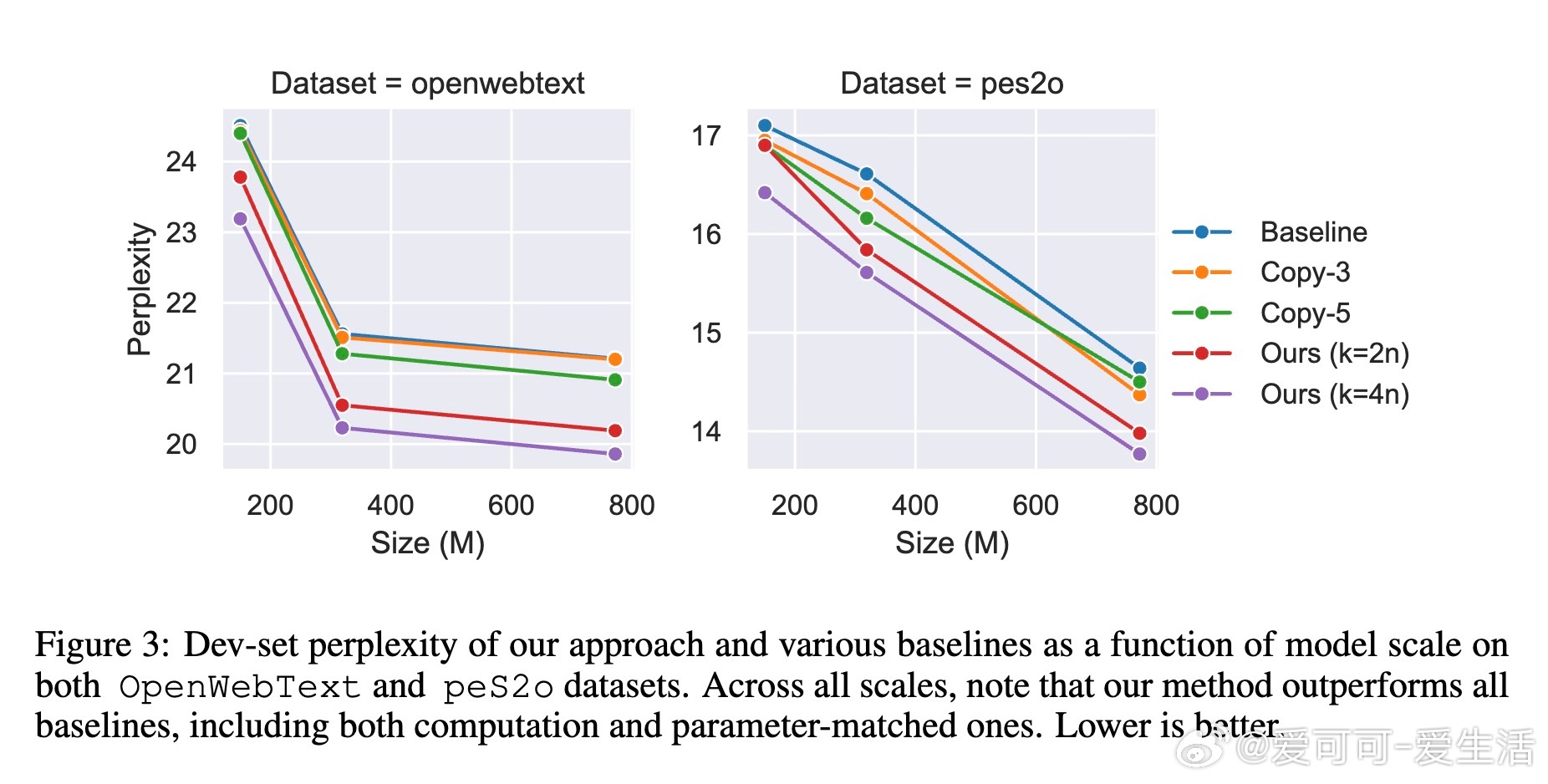
• 性能领先:在OpenWebText和peS2o数据集上,Thoughtbubbles在困惑度和零样本任务(如LAMBADA、HellaSwag)中均超越参数与计算量匹配的传统Transformer及复制填充Token基线,甚至小规模模型优于大规模基线。
• 位置编码创新:采用部分旋转的RoPE编码,确保多叉残差流间位置关系合理,有效支持多分支计算。
• 训练与推理统一:预训练即具备动态并行计算能力,推理时通过调整预算可灵活控制计算强度,支持高效自适应推断。
• 代码开源:提供PyTorch实现,便利社区复现和扩展。
心得:
1. 预训练阶段即学习动态计算分配突破了传统必须后期插入思考链的限制,实现训练与推理模式的无缝衔接。
2. 隐空间中并行复制残差流的思路,打破了Transformer固定计算预算的瓶颈,使复杂问题的“多线程”思考成为可能。
3. 模型自动聚焦于中等不确定性区域投入更多计算,反映了对计算资源利用的深刻理解与优化,启示未来模型设计需更智能调度算力。
了解详情🔗arxiv.org/abs/2510.00219
Transformer自适应计算并行推理语言模型机器学习自然语言处理