[LG]《Per-example gradients: a new frontier for understanding and improving optimizers》V Roulet, A Agarwala [Google Deepmind] (2025)
深度学习训练中,传统优化器仅利用mini-batch梯度均值,忽略了丰富的梯度统计信息。最新研究揭示:通过“计算图手术”技术,可以高效获取并利用每个样本的梯度统计,极大拓展优化算法设计空间。
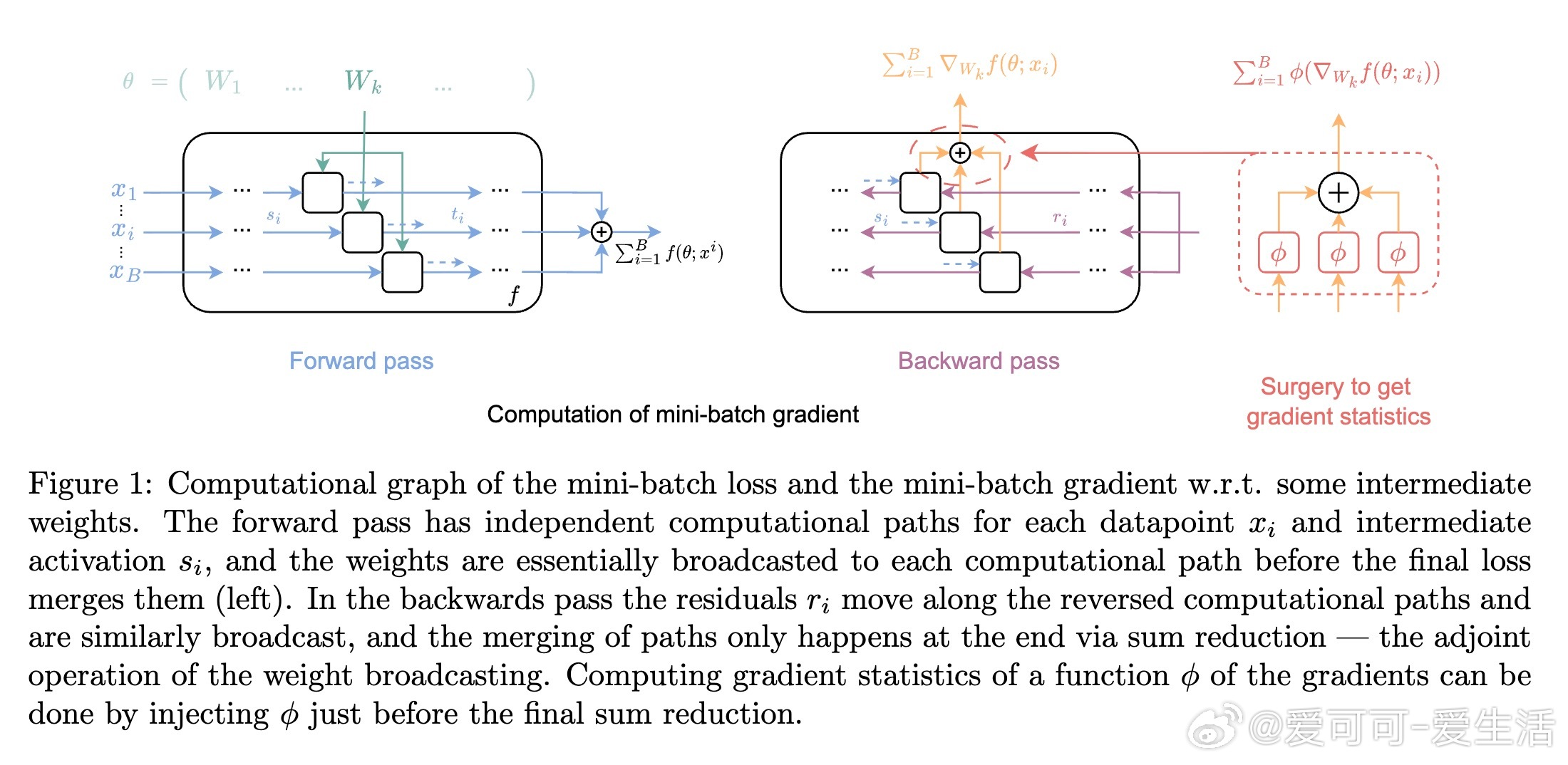
• 传统自动微分框架仅计算mini-batch梯度均值,难以获得单个样本梯度分布及高阶矩信息,限制了训练算法的理解和创新。
• 通过解析计算图,将非线性函数ϕ注入梯度计算的最后求和前,可高效计算如梯度平方、方差、符号等复杂统计,且内存和计算开销接近传统梯度计算。
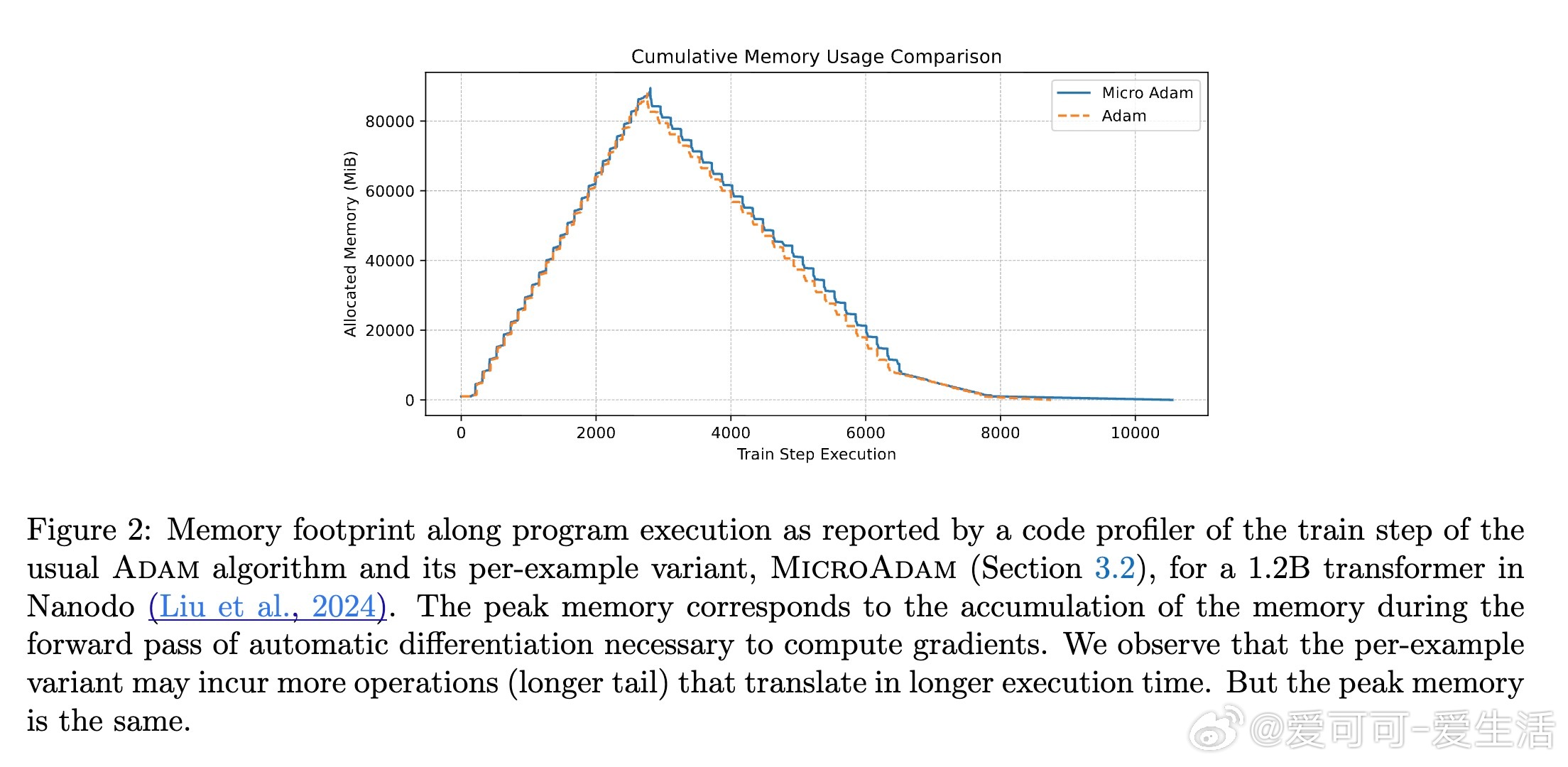
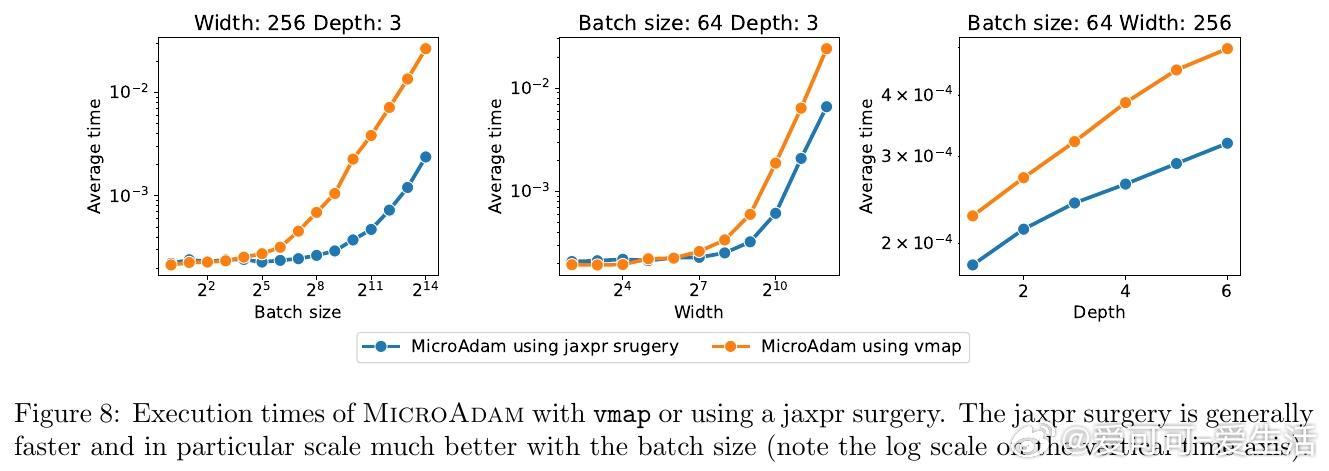
• 针对序列模型(如Transformer),利用JAX的vmap矢量化实现,既方便快速原型设计,也仅带约17%计算开销,峰值内存不增。
• SignSGD优化器中,符号函数的最佳应用时机是尽可能晚,靠前应用会严重降低信噪比(SNR),影响训练稳定性和速度。
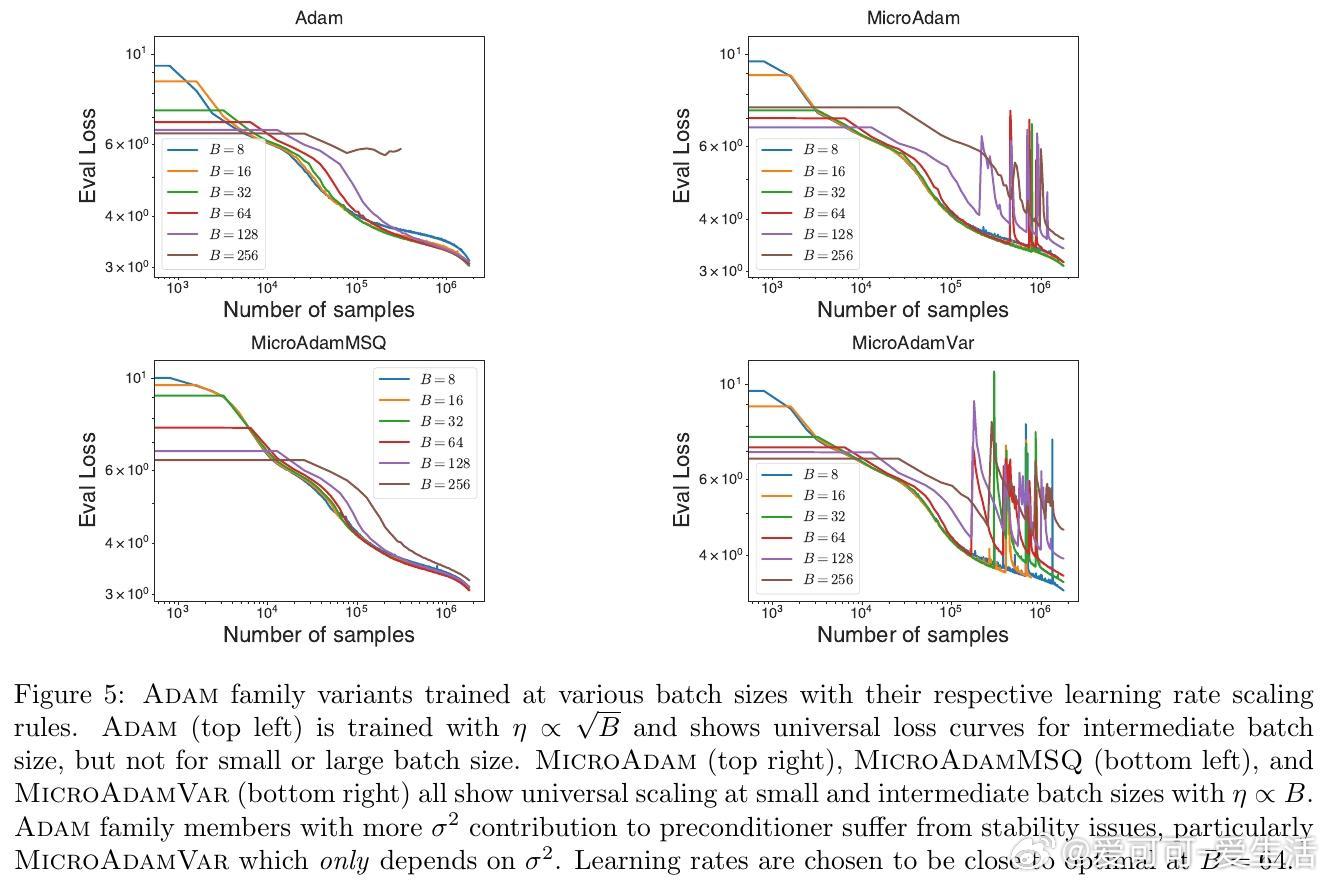
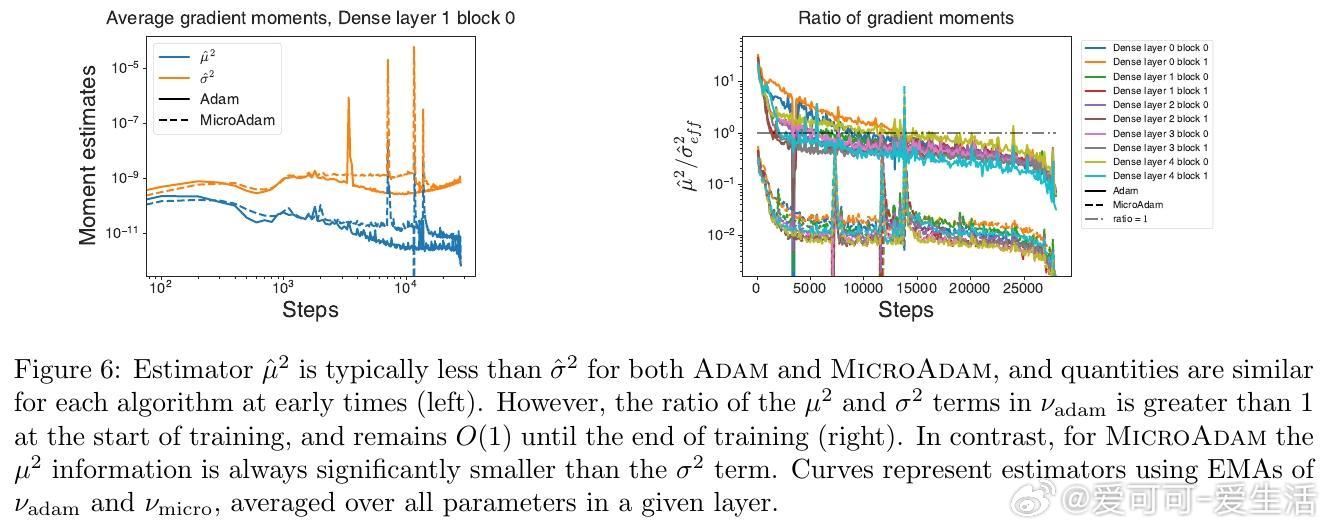
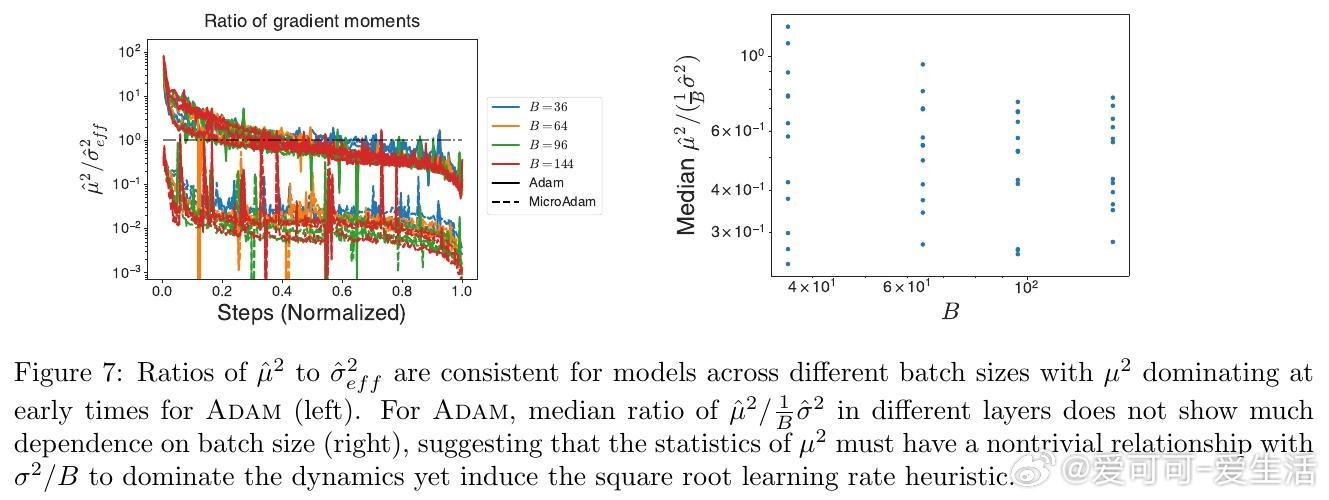
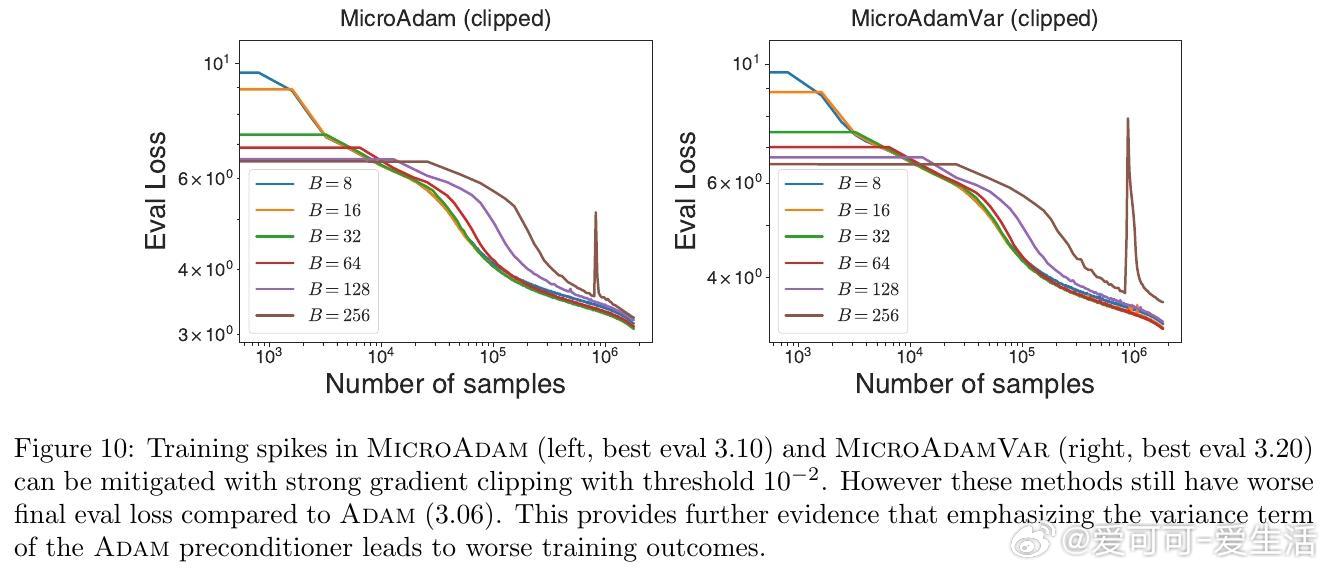
• Adam优化器变体MicroAdam通过利用真实的单样本梯度二阶矩,发现预处理器以均值平方主导效果更优于以方差主导,颠覆传统认为方差信息更重要的观念。
• 扩展的Adam家族(MicroAdamVar,MicroAdamMSQ)中,过度强调方差导致训练不稳定甚至性能下降,合理平衡均值和方差信息是关键。
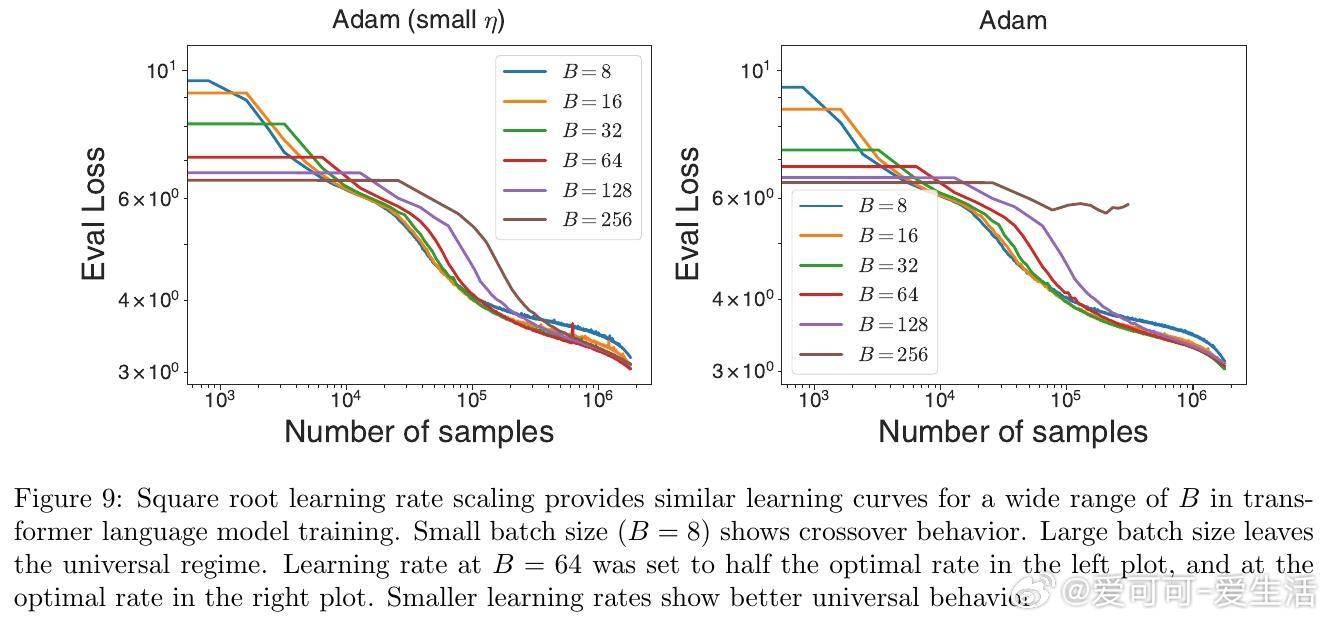
• 该方法助力全面剖析梯度分布动态,揭示批量大小、学习率缩放(如Adam的平方根规则)背后的统计本质,提升大规模训练的理论和实践水平。
心得:
1. 利用单样本梯度统计,不仅能理解现有优化算法的内在机理,还能设计更鲁棒高效的新型优化器。
2. 计算图“手术”与JAX矢量化结合,巧妙避开了内存瓶颈,为复杂梯度操作提供了可行路径。
3. 传统优化器设计中忽视的批内梯度分布信息,实际上对训练稳定性和性能有深远影响,未来优化研究应重视这一层面。
了解详情🔗 arxiv.org/abs/2510.00236
深度学习优化器自动微分梯度统计TransformerJAX机器学习算法