[CL]《Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity》J Zhang, S Yu, D Chong, A Sicilia... [Northeastern University & Stanford University] (2025)
人类偏好数据中的“典型性偏差”导致大规模语言模型(LLM)模式崩塌,限制了输出多样性。如何恢复并释放模型固有的创造力?一招“口述采样”(Verbalized Sampling, VS)帮你解锁多样性新天地。
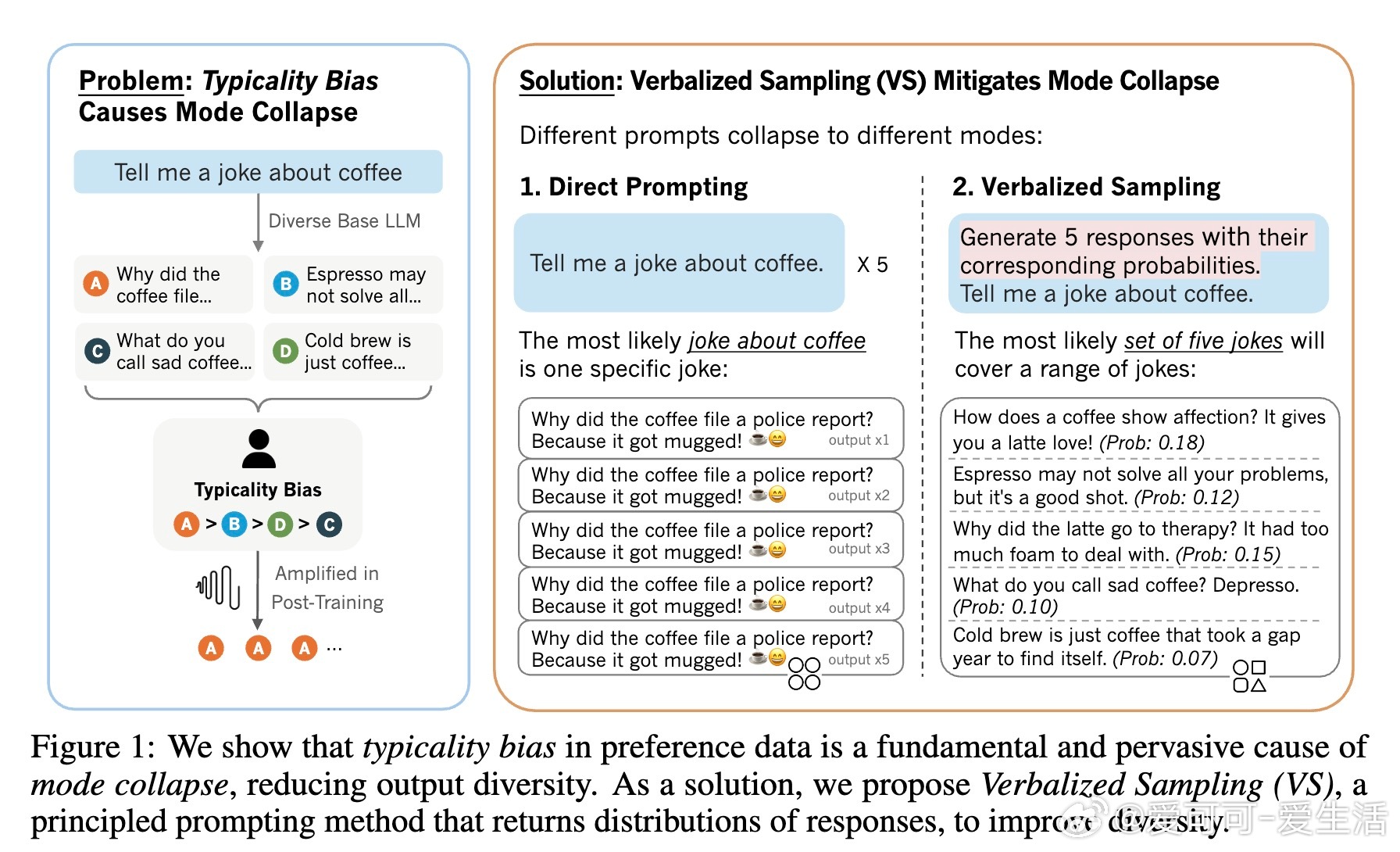
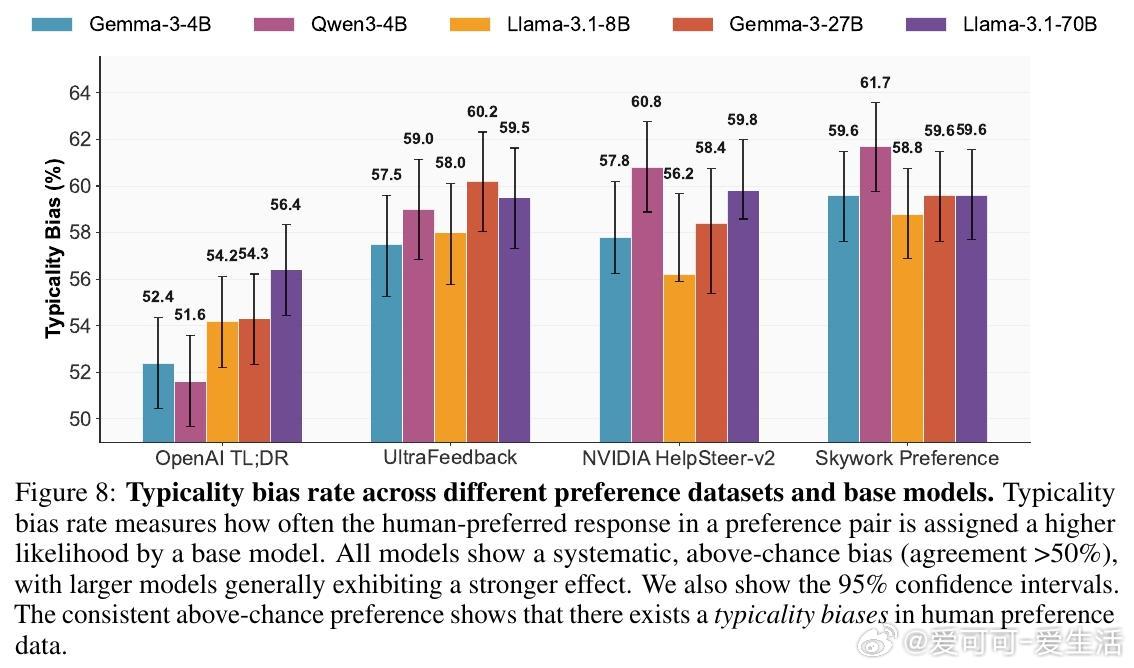
• 典型性偏差根源于认知心理学:人类评注者偏爱熟悉、流畅且可预测的文本,导致训练偏向少数“典型”输出,压缩了模型生成的多样性。
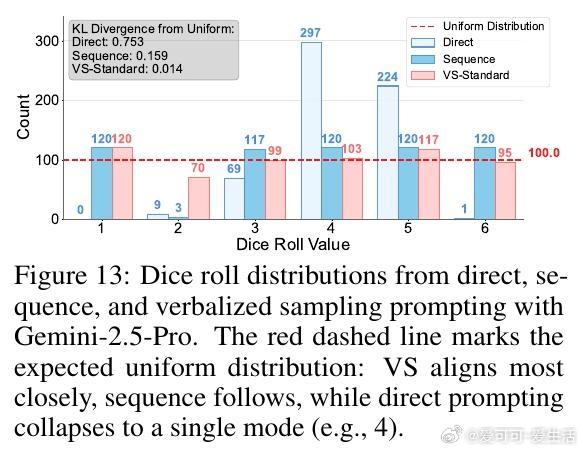
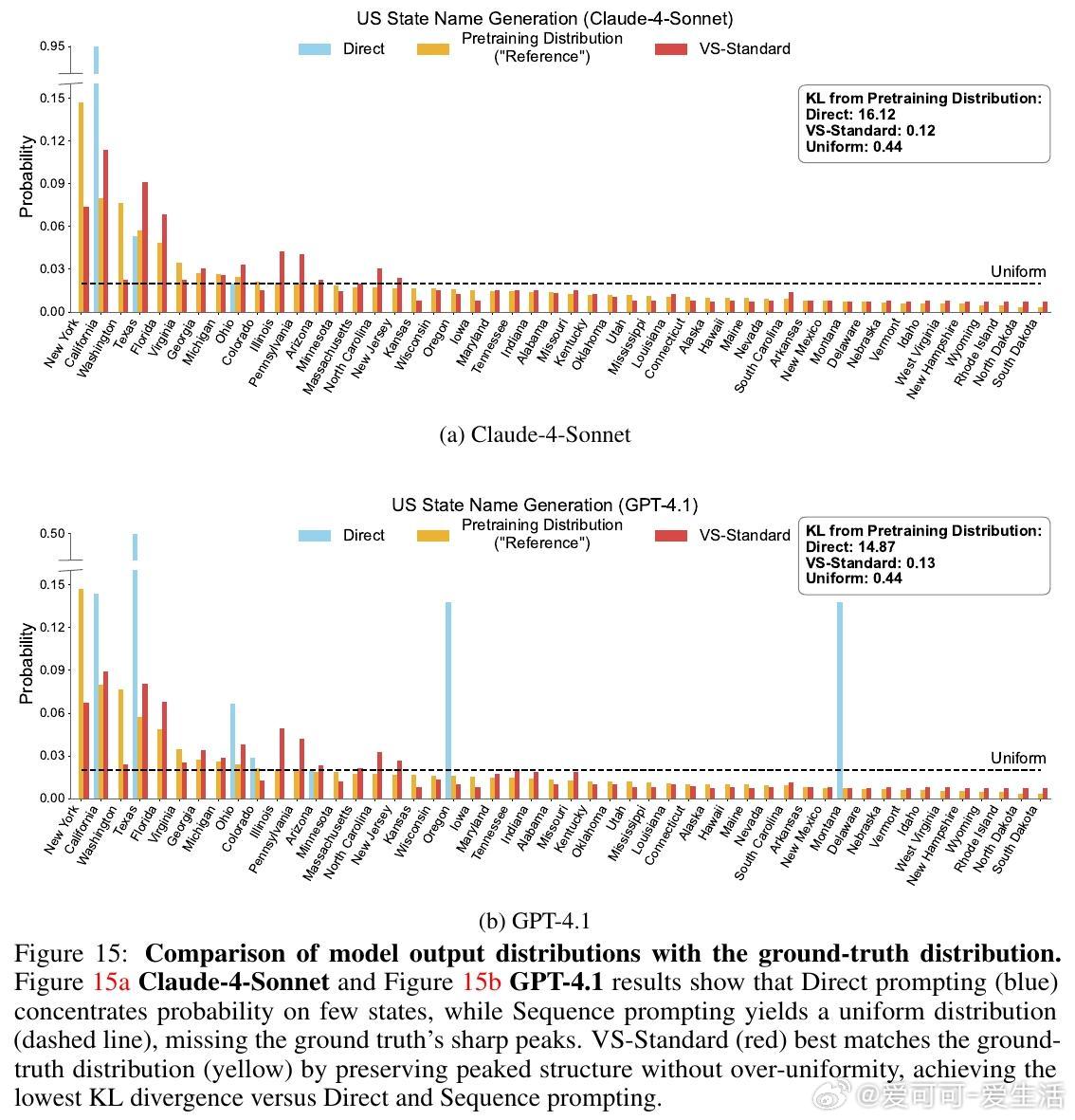
• VS 通过训练后无额外调优,仅在推理时改写提示,要求模型“生成多条回答及其对应概率”,显式表达输出分布,恢复预训练模型的多样性。
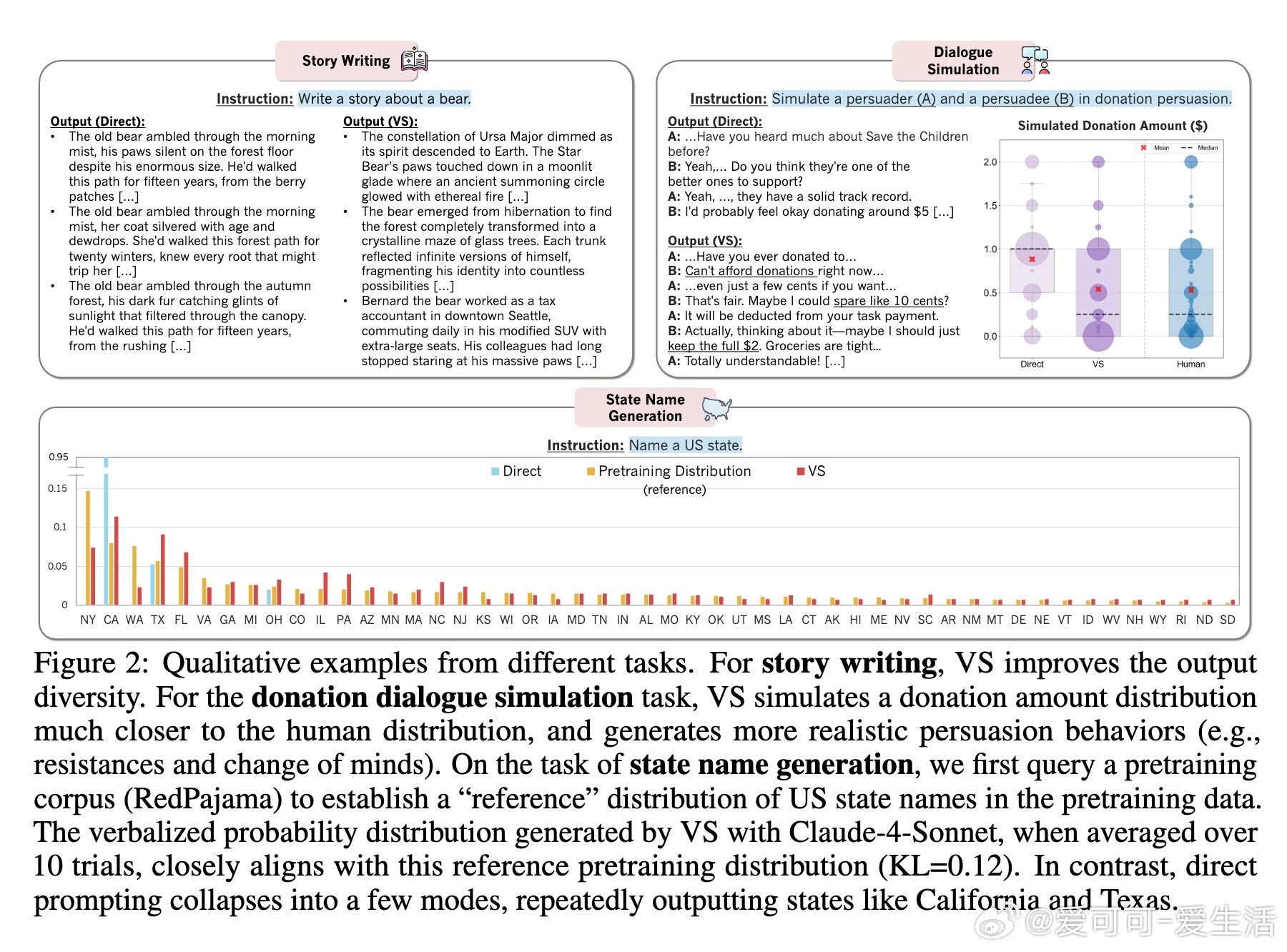
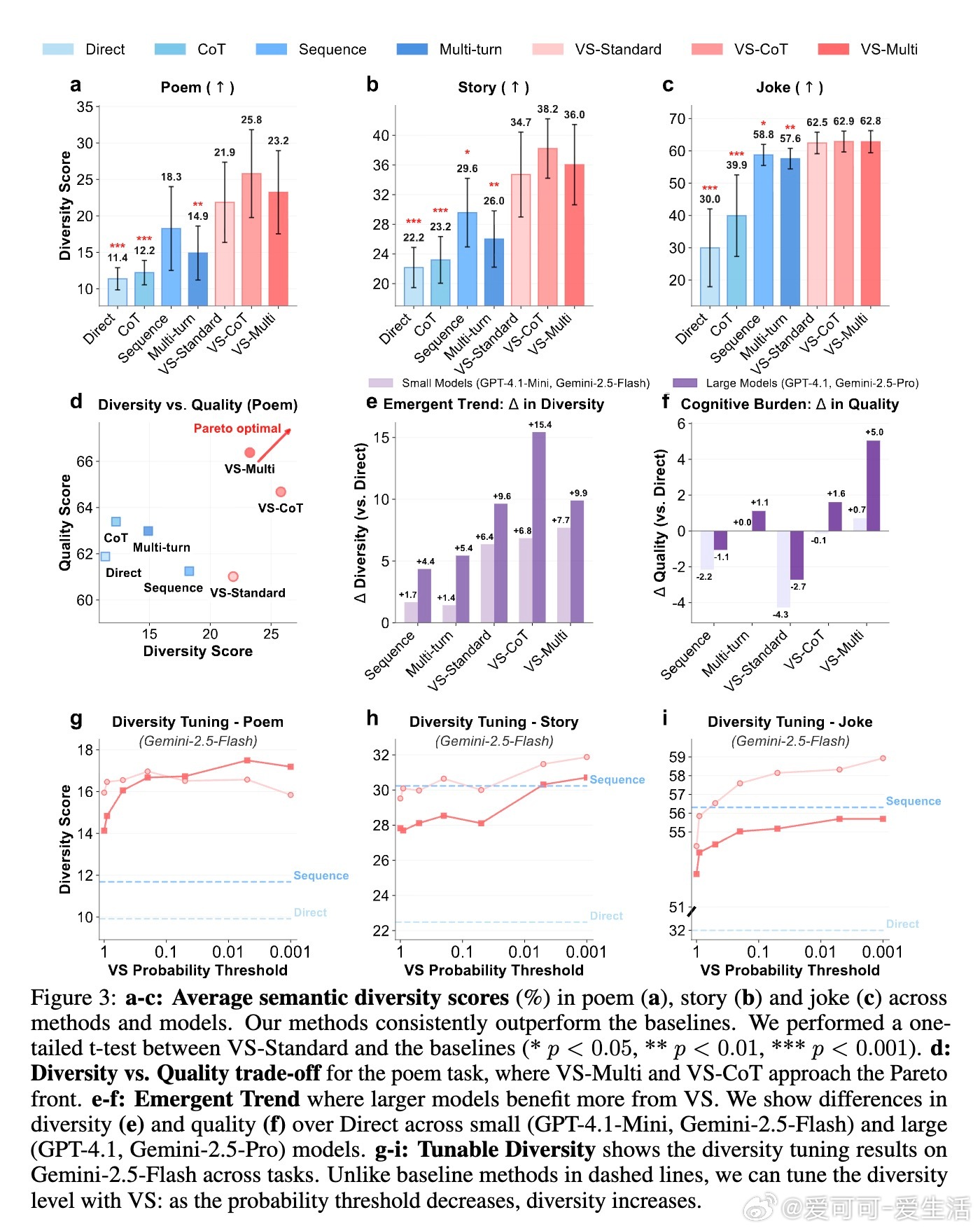
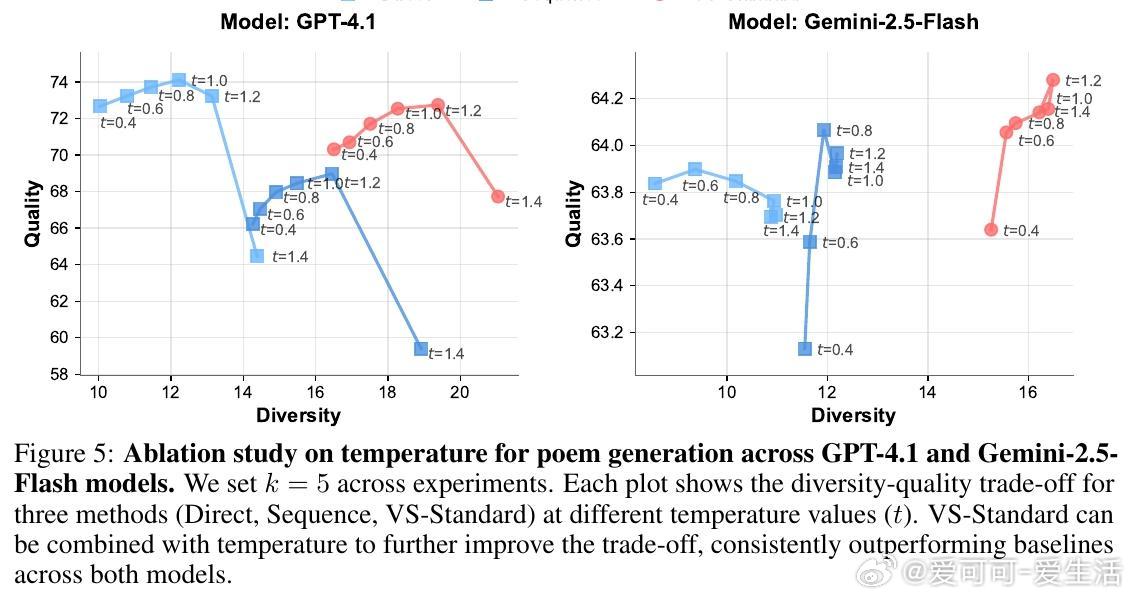
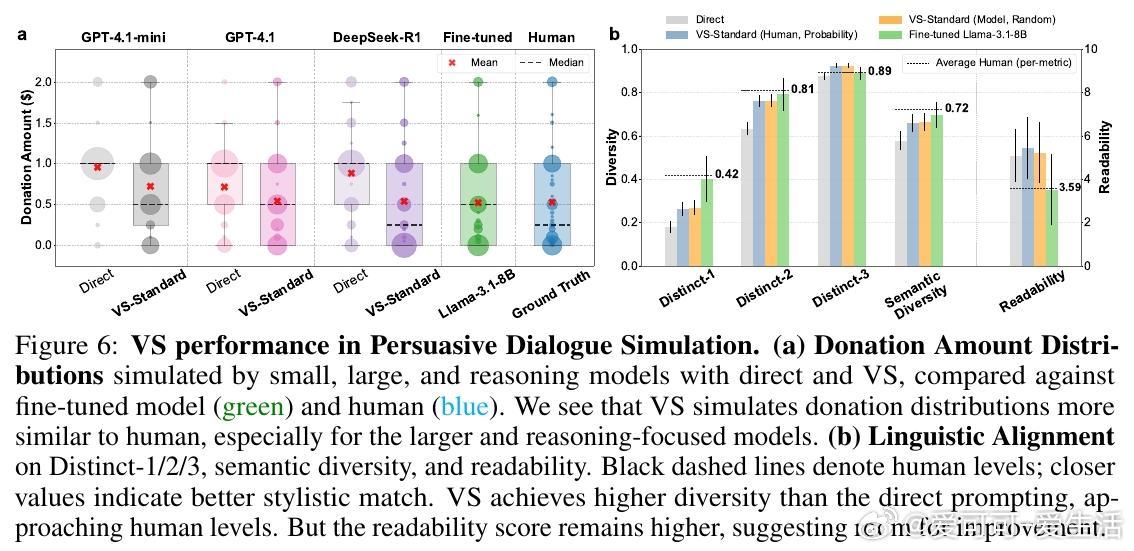
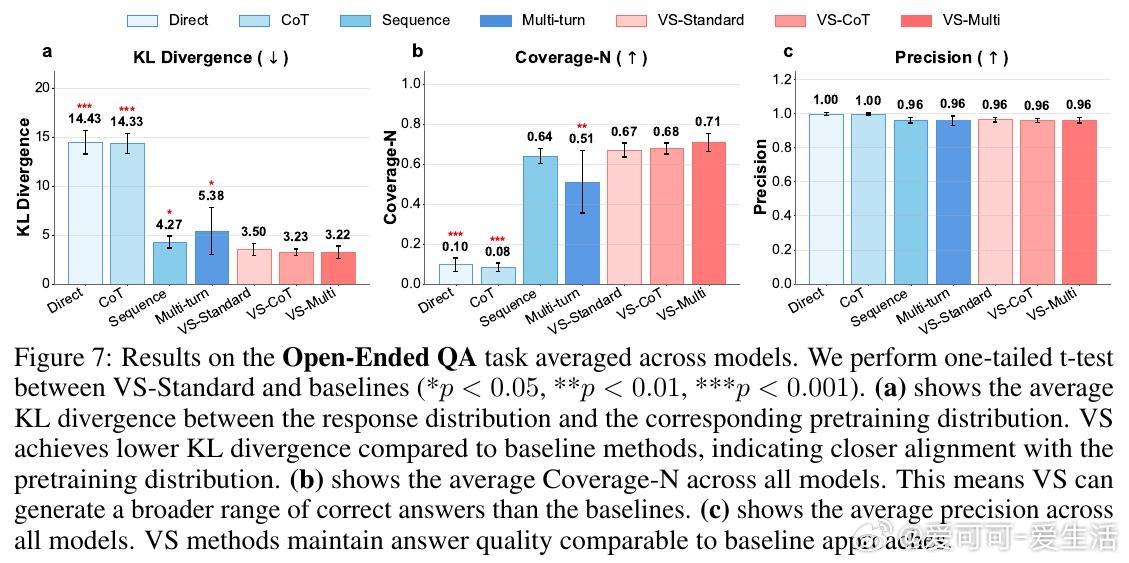
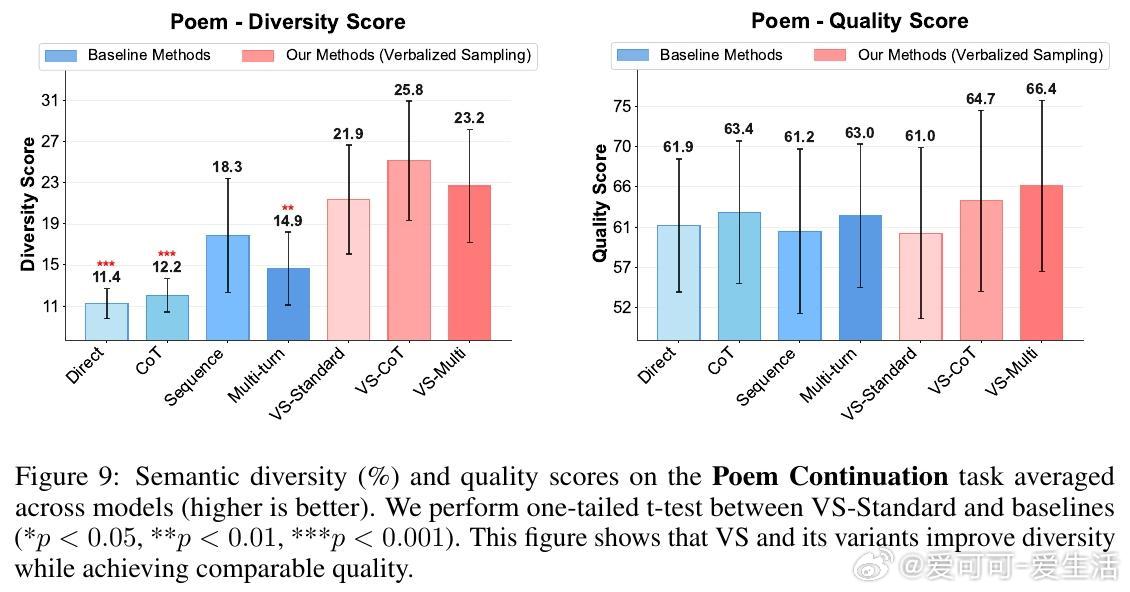
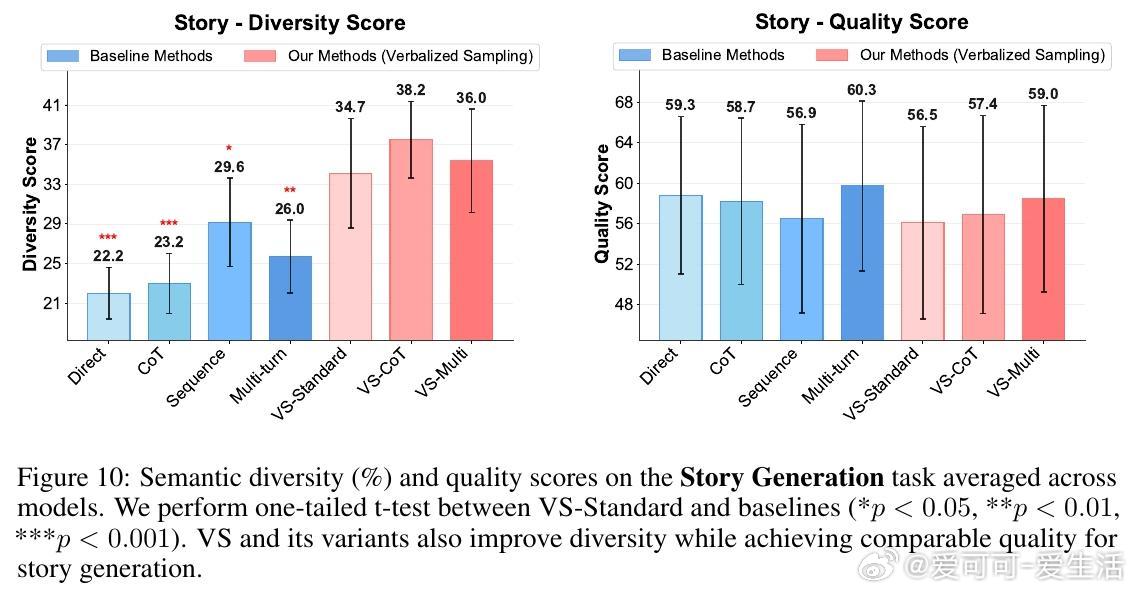
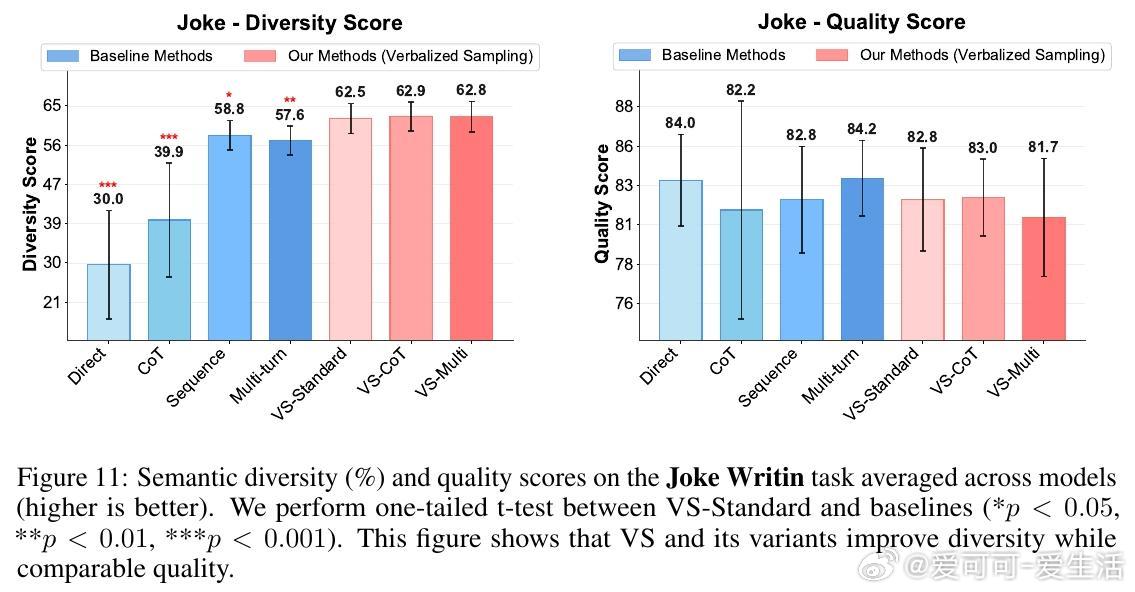
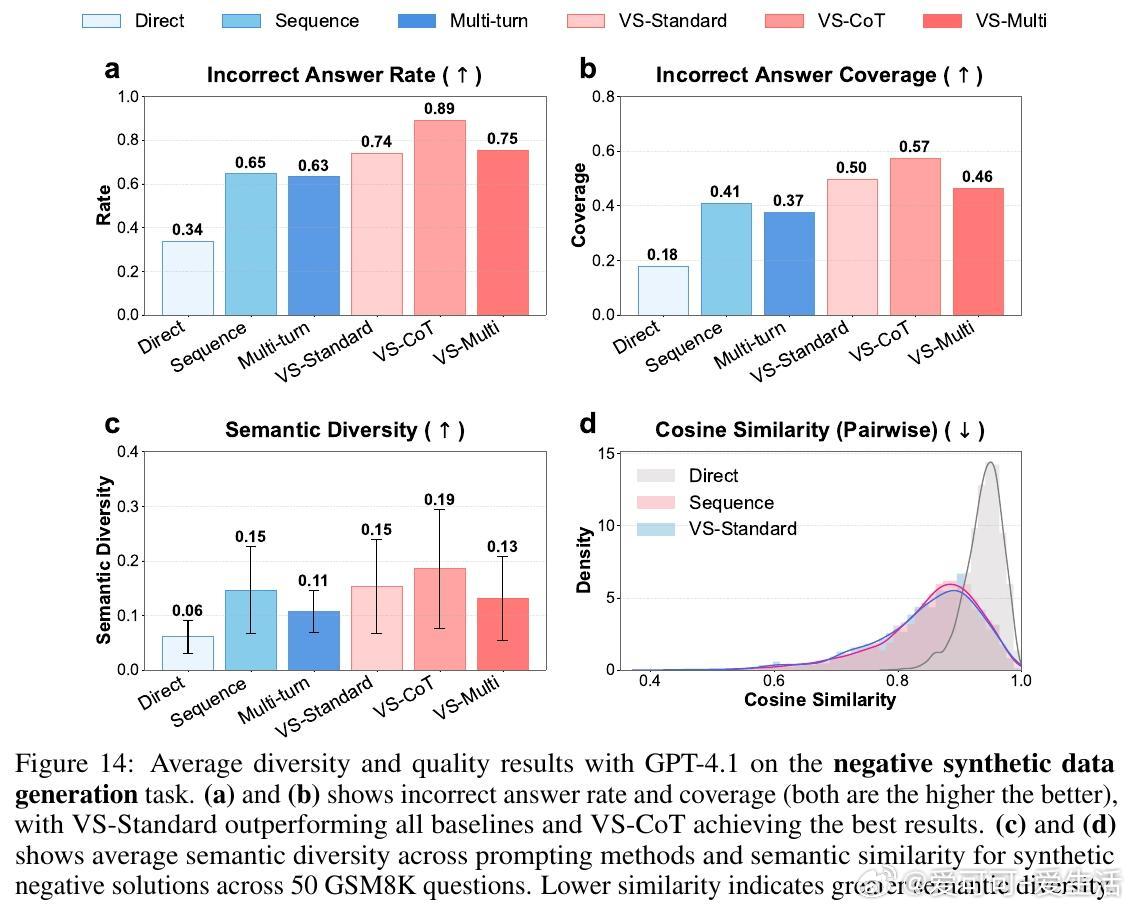
• 适用广泛:在诗歌、故事、笑话创作;多轮对话模拟;开放式问答;合成数据生成等多任务中,VS 均显著提升多样性(创作类任务多样性提升1.6-2.1倍),且不牺牲准确性和安全性。
• 大型模型受益更明显:复杂提示虽可能带来认知负担,但更强模型反而因 VS 获得质量和多样性的双重提升。
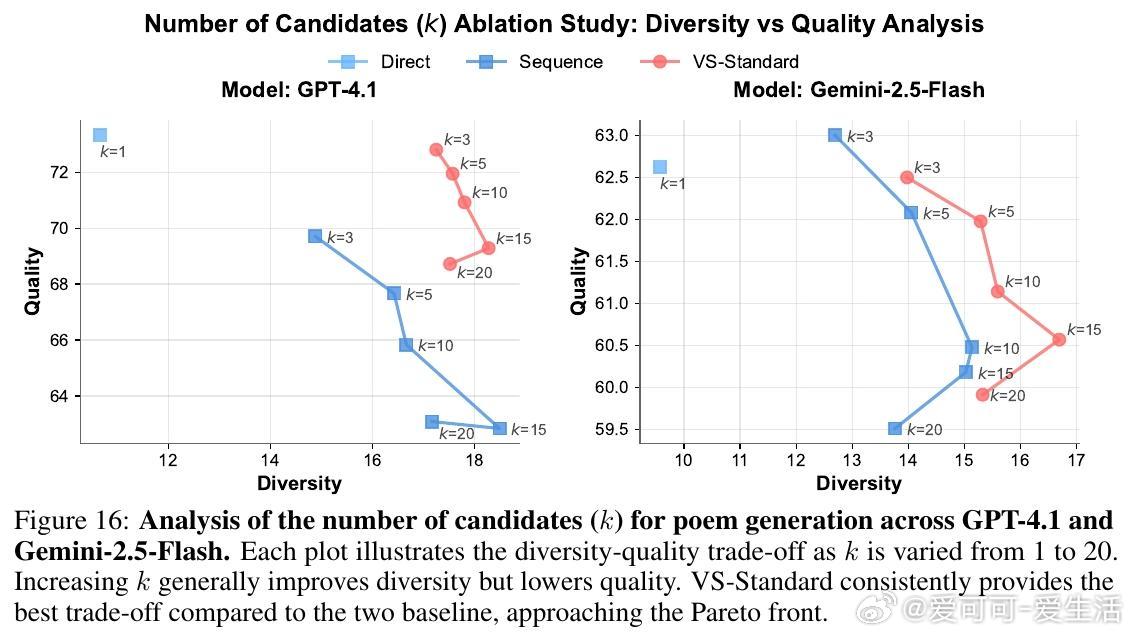
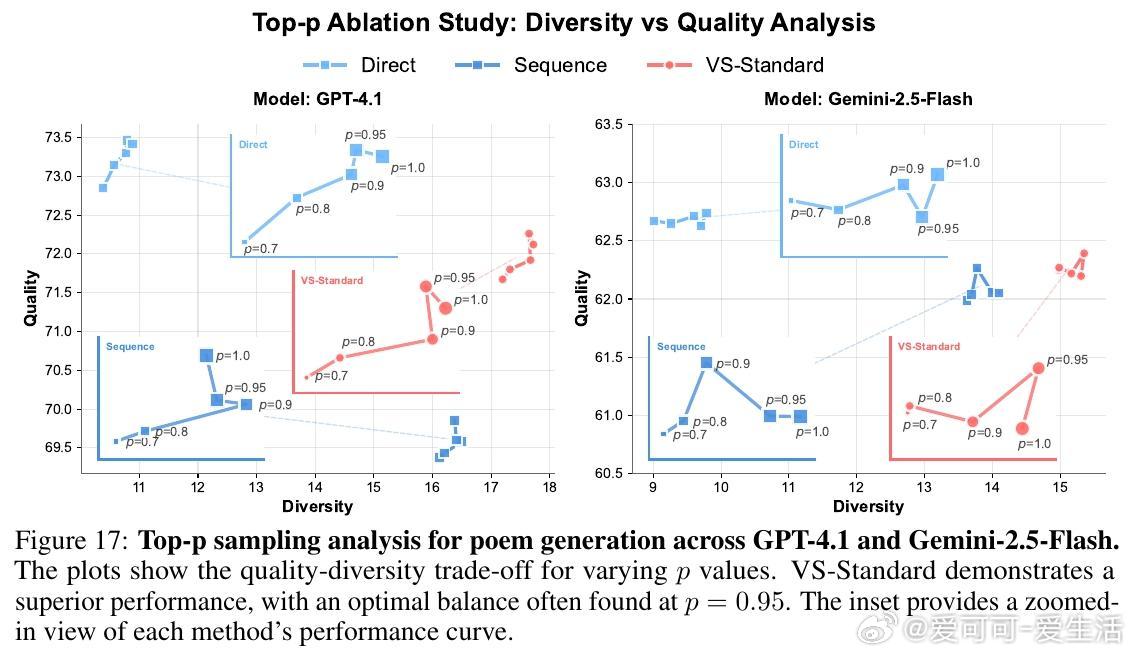
• VS 允许用户通过调整概率阈值灵活控制多样性,满足不同应用需。
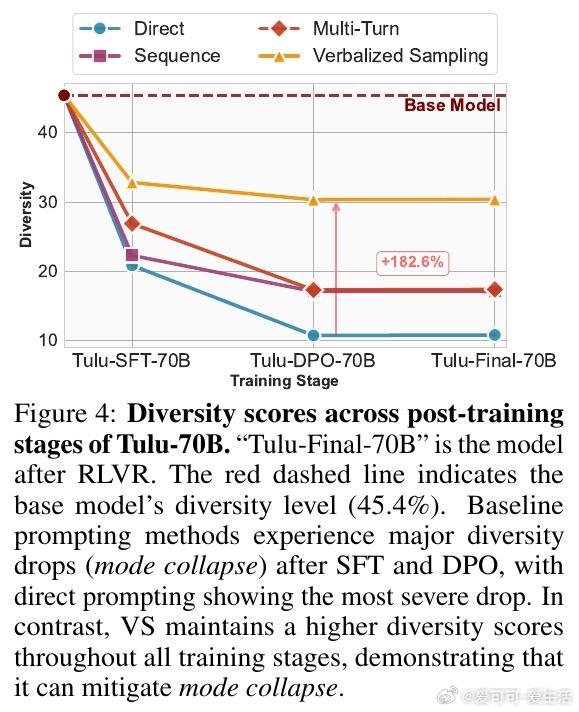
• 理论与实证结合:首次确证典型性偏差在偏好数据中的普遍存在及其对模式崩塌的本质影响,提出推理端解决方案,开辟了训练外的多样性恢复新路径。
心得:
1. 训练数据本身的认知偏差是限制模型创造力的关键瓶颈,单纯算法优化难以根治。
2. 明确表达和利用模型内部概率分布有助于打破输出单一化,恢复潜在多样性。
3. 多样性与质量并非零和,合理设计提示可实现两者兼顾,尤其在大模型上效果显著。
详情见👉 arxiv.org/abs/2510.01171
大规模语言模型模式崩塌生成多样性认知偏差提示工程人工智能