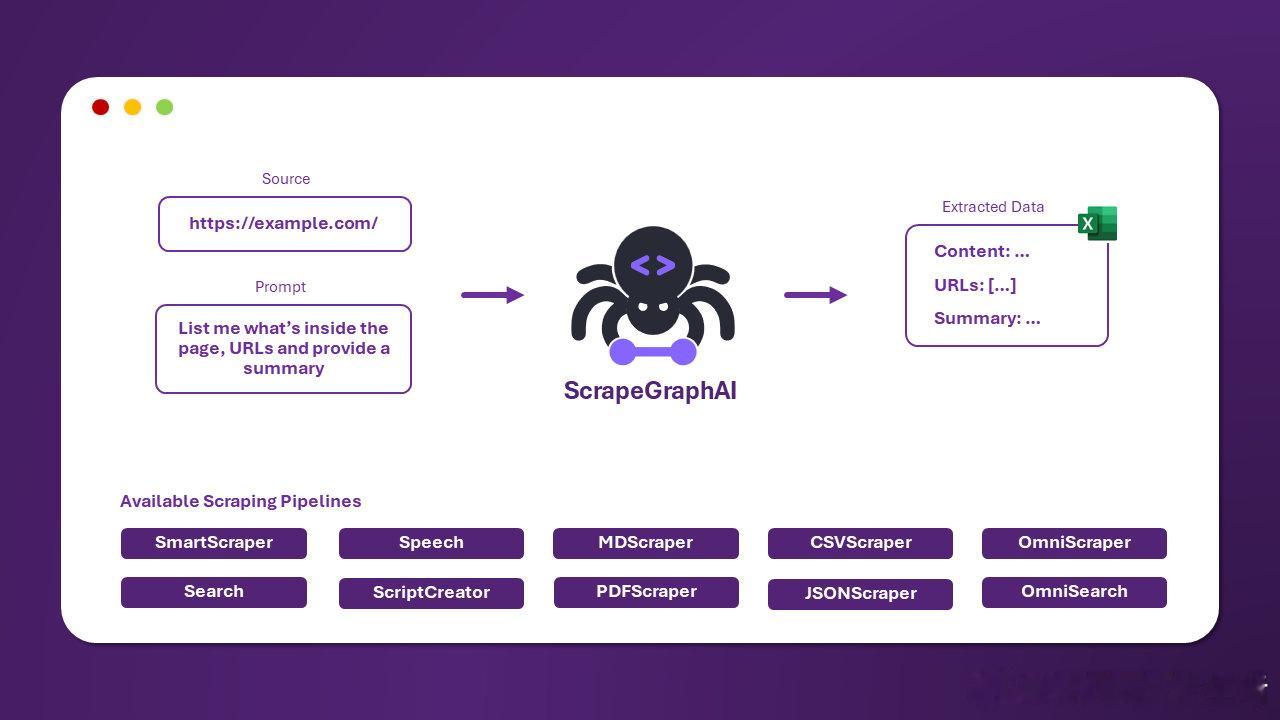
ScrapeGraphAI:基于大型语言模型与图逻辑的Python爬虫库,实现“一次爬取,多次利用”的高效数据提取方案。🕸️
• 利用LLM(如OpenAI、Ollama等)和图结构构建灵活爬取管线,支持网页及本地文档(HTML、Markdown、JSON、XML等)
• 多种爬取模式:单页智能提取(SmartScraperGraph)、多页搜索结果抓取(SearchGraph)、音频生成(SpeechGraph)、自动生成Python脚本(ScriptCreatorGraph)等,满足复杂场景需求
• 完善集成生态:支持Python、Node.js SDK,兼容Langchain、Llama Index、Zapier、Bubble等主流低代码/无代码平台,极大降低二次开发门槛
• 简单易用:5行代码快速上手,官方推荐虚拟环境安装,Playwright支持动态网页内容抓取
• 透明开源,MIT协议授权,活跃社区持续更新,20.5k⭐,1700+ Fork,适合科研、数据分析、自动化工程长期参考与实践
• 详尽文档与示例代码覆盖多语言接口,支持多模型并行调用,灵活切换本地或云端LLM,强调方法论与长远适用性
ScrapeGraphAI通过“语言理解+图结构”策略,将爬虫从传统规则驱动转向智能语义驱动,极大提升数据清洗和结构化效率,是下一代智能数据抽取范式的典范。
了解详情🔗 github.com/ScrapeGraphAI/Scrapegraph-ai
智能爬虫 大语言模型 数据自动化 Python 开源项目 WebScraping