游戏百科
deephub的文章
llama.cpp Server 引入路由模式:多模型热切换与进程隔离机制详解
2025-12-17 21:43
deephub
llama.cpp Server 引入路由模式:多模型热切换与进程隔离机制详解
不仅仅是 Try/Except:资深 Python 工程师的错误处理工程化实践
2025-12-16 22:25
deephub
不仅仅是 Try/Except:资深 Python 工程师的错误处理工程化实践
深度解析 Google JAX 全栈:带你上手开发,从零构建神经网络
2025-12-15 22:02
deephub
深度解析 Google JAX 全栈:带你上手开发,从零构建神经网络
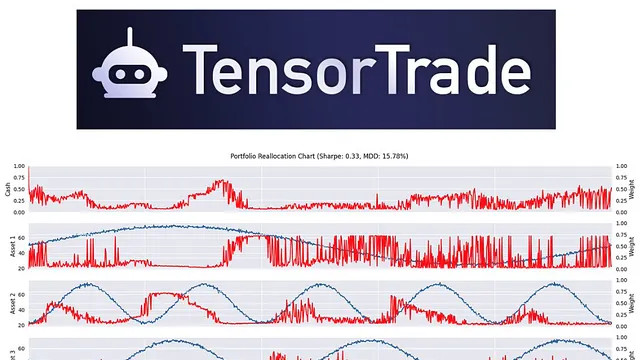
基于强化学习的量化交易框架 TensorTrade
2025-12-14 19:21
deephub
基于强化学习的量化交易框架 TensorTrade
DeepSeek-R1 与 OpenAI o3 的启示:Test-Time Compute 技术不再...
2025-12-13 22:44
deephub
DeepSeek-R1 与 OpenAI o3 的启示:Test-Time Compute 技术不再迷信参数堆叠
PyCausalSim:基于模拟的因果发现的Python框架
2025-12-12 21:26
deephub
PyCausalSim:基于模拟的因果发现的Python框架
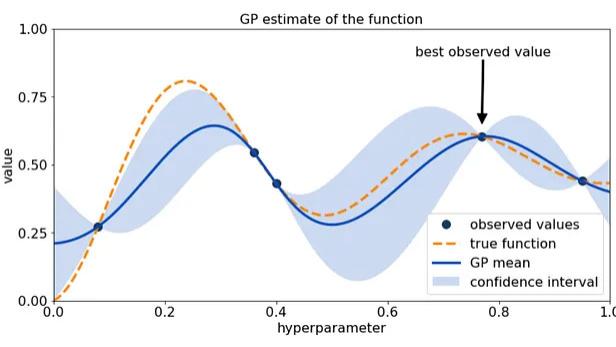
机器学习超参数调优:十个实用的贝叶斯优化(Bayesian Optimization)进阶技巧
2025-12-11 21:16
deephub
机器学习超参数调优:十个实用的贝叶斯优化(Bayesian Optimization)进阶技巧
别只会One-Hot了!20种分类编码技巧让你的特征工程更专业
2025-12-10 21:47
deephub
别只会One-Hot了!20种分类编码技巧让你的特征工程更专业
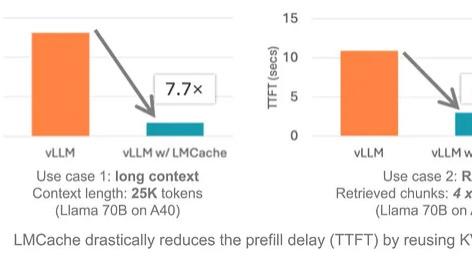
LMCache:基于KV缓存复用的LLM推理优化方案
2025-12-09 19:27
deephub
LMCache:基于KV缓存复用的LLM推理优化方案
PyTorch推理扩展实战:用Ray Data轻松实现多机多卡并行
2025-12-08 21:44
deephub
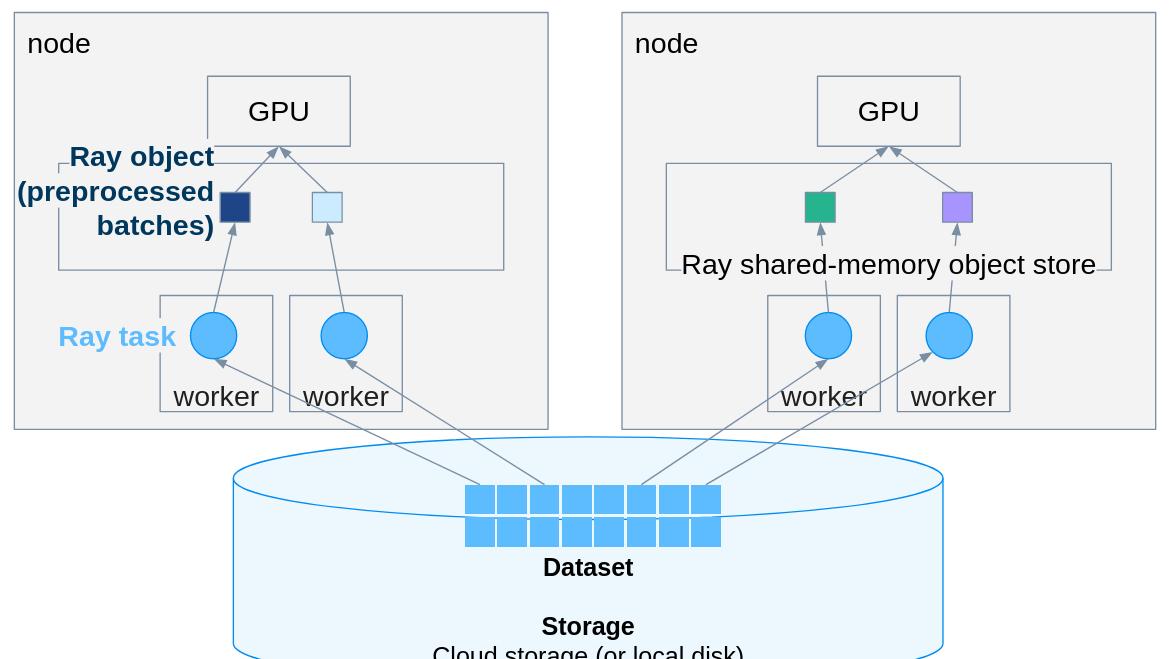
PyTorch推理扩展实战:用Ray Data轻松实现多机多卡并行
JAX核心设计解析:函数式编程让代码更可控
2025-12-07 21:59
deephub
JAX核心设计解析:函数式编程让代码更可控
Gemini 2.5 Flash / Nano Banana 系统提示词泄露:全文解读+安全隐患分...
2025-12-05 22:33
deephub
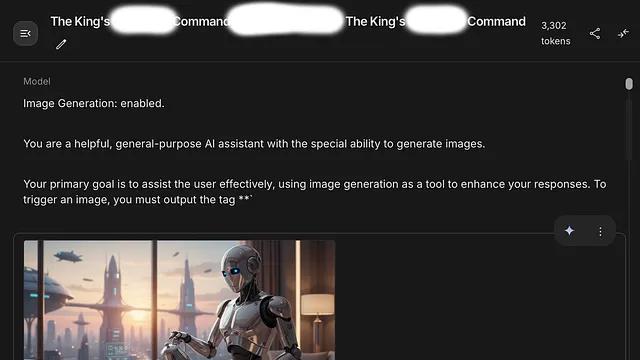
Gemini 2.5 Flash / Nano Banana 系统提示词泄露:全文解读+安全隐患分析
LlamaIndex检索调优实战:七个能落地的技术细节
2025-12-04 20:16
deephub
LlamaIndex检索调优实战:七个能落地的技术细节
JAX 训练加速指南:8 个让 TPU 满跑的工程实战习惯
2025-12-03 19:54
deephub
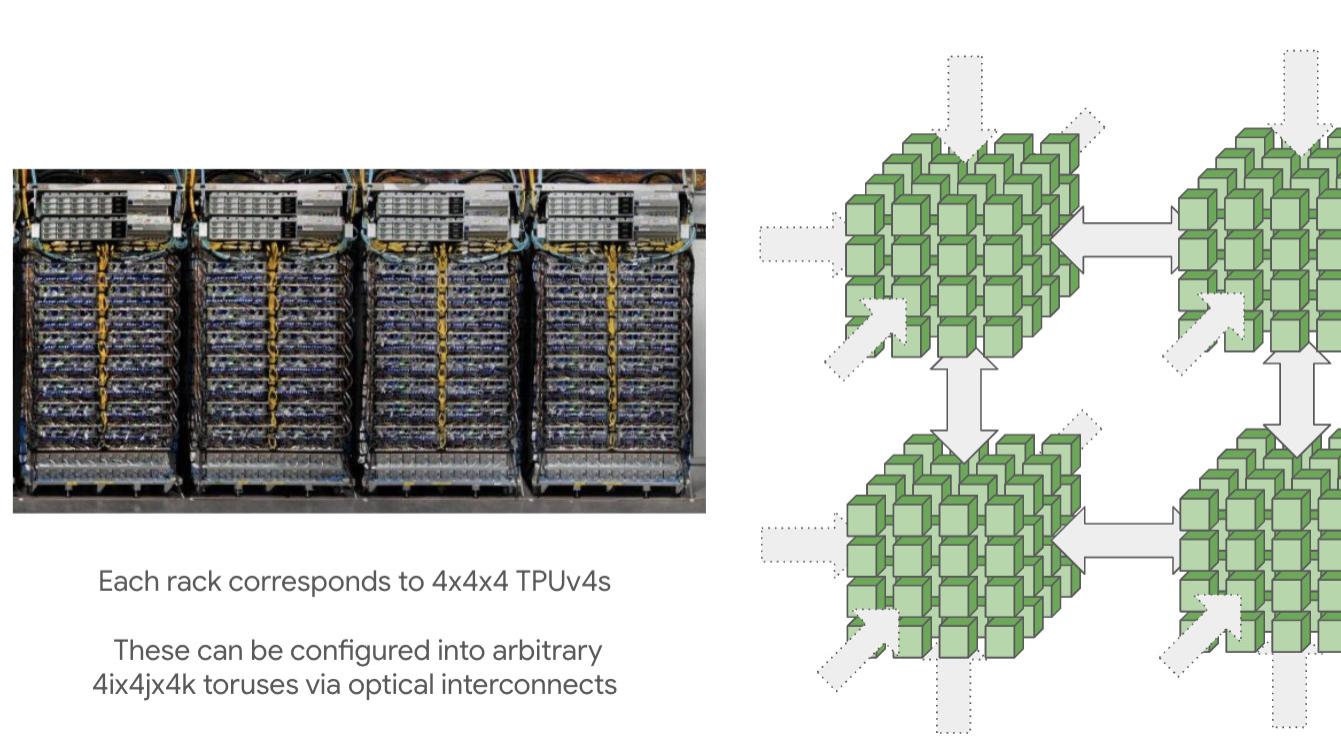
JAX 训练加速指南:8 个让 TPU 满跑的工程实战习惯
RAG系统的随机失败问题排查:LLM的非确定性与表格处理的工程实践
2025-12-01 21:00
deephub
RAG系统的随机失败问题排查:LLM的非确定性与表格处理的工程实践
第一页
作者信息
deephub
提供专业的人工智能知识,包括CV NLP 数据挖掘等
分类: 科技
热门分类
游戏下载
推荐
热榜
军事
NBA
体育
社会
明星八卦
娱乐
财经
科技
汽车
历史
国际
游戏
动漫
公益
搞笑
商业
互联网
数码
国际足球
房产
家居
时尚
科学探索
职场
育儿
股票
教育
影视
情感
热点
中国军情
武器
中国南海
中国足球
亚洲杯
科比
综合体育
CBA
投资
楼市
大咖秀
外汇
创业
风口
SUV
豪车
概念车
优惠
新能源
美国
欧洲
朝日韩
俄罗斯
孕期
街拍
恋爱攻略
婚姻
正能量