[LG]《Outcome-based Exploration for LLM Reasoning》Y Song, J Kempe, R Munos [FAIR at Meta] (2025)
强化学习提升大语言模型(LLM)推理能力的背后隐忧与突破:
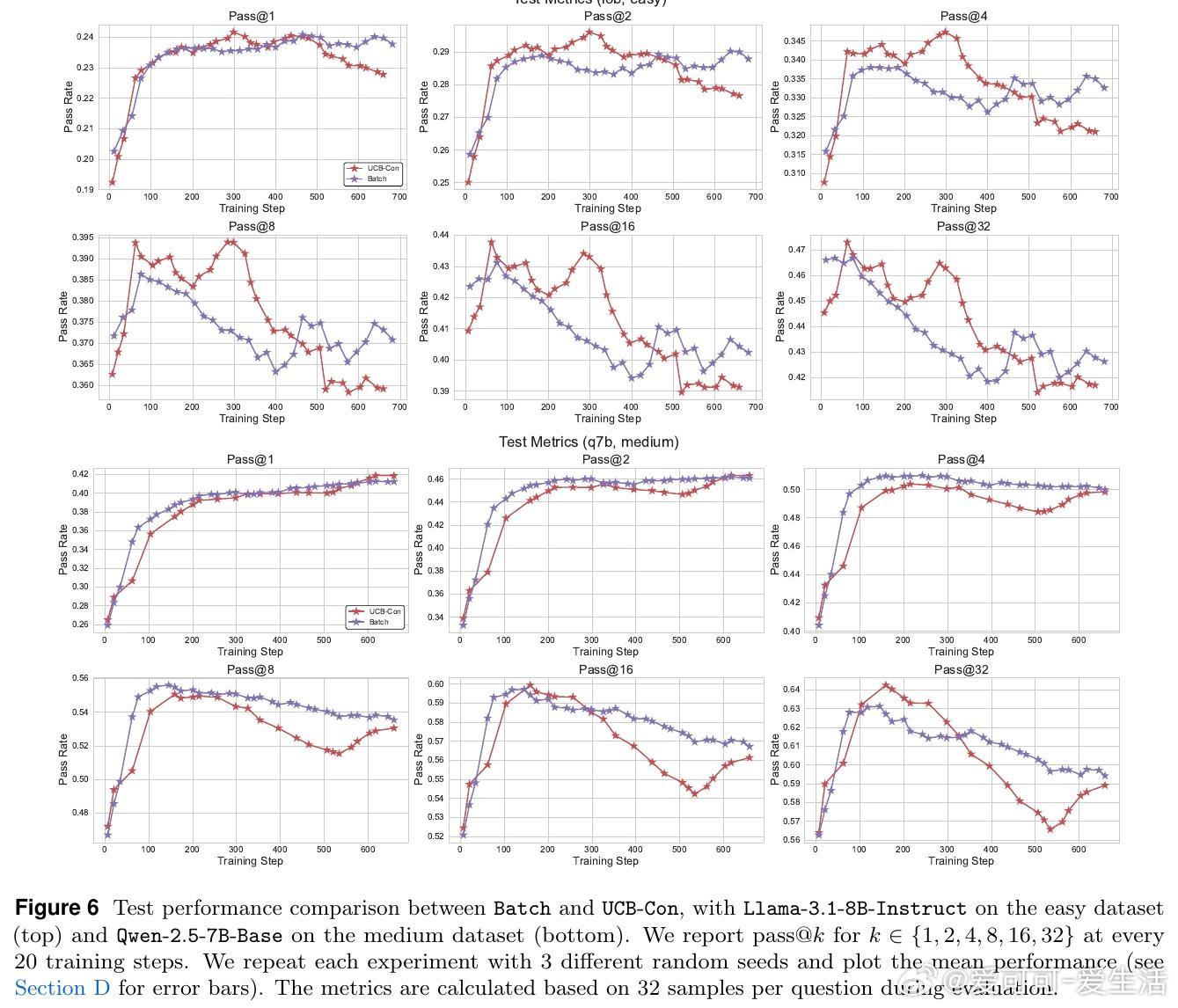
• 传统基于结果的强化学习只奖励最终答案正确性,虽提升准确率,却引发生成多样性急剧下降,削弱模型在实际环境中通过多样性放大性能的能力。
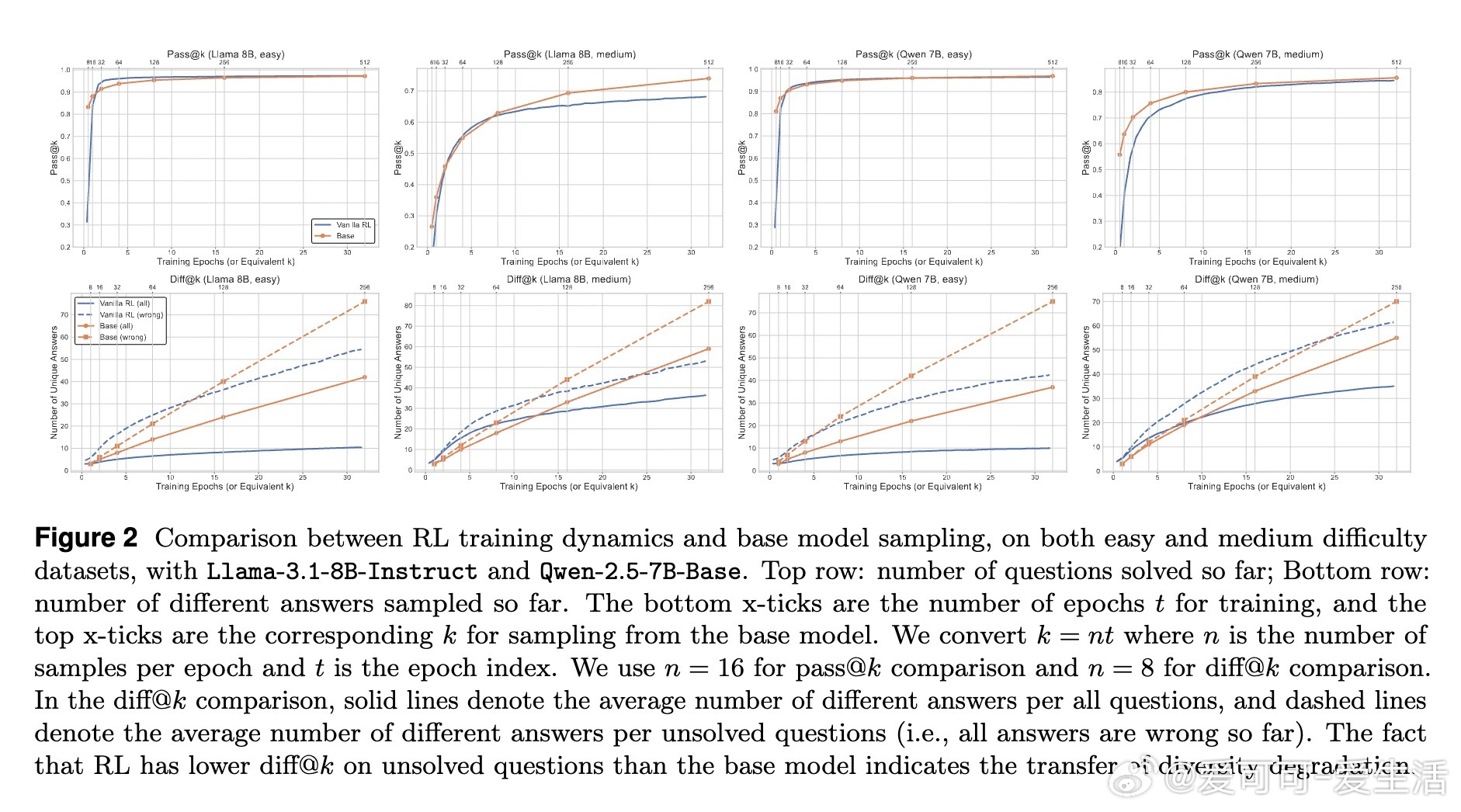
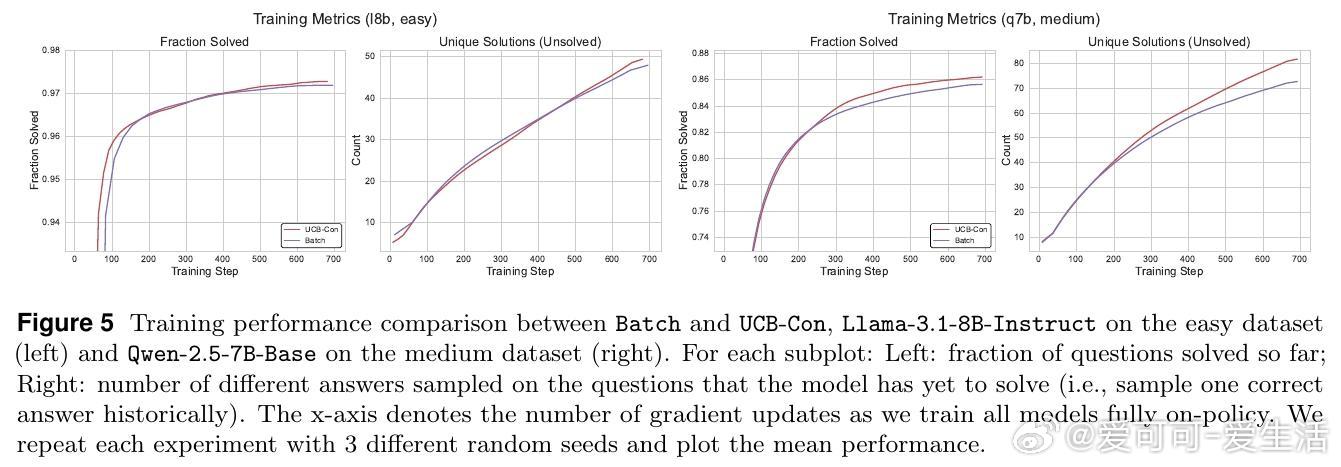
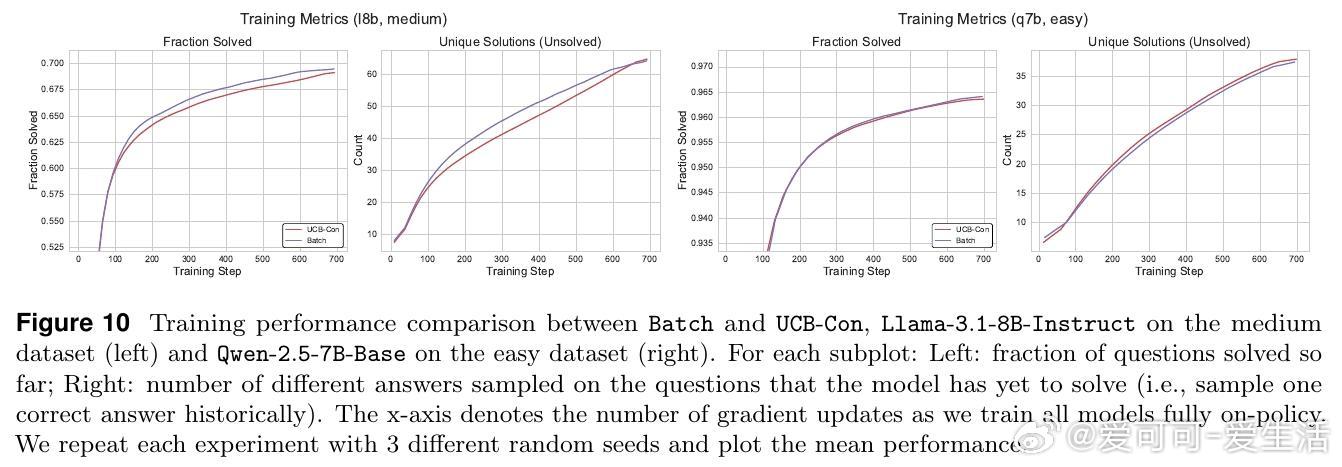
• 多样性下降不仅表现在测试时,训练阶段亦已显著;尤其在已解决问题上多样性降低,进而“传染”至未解决问题,称为多样性退化的转移效应。
• 推理任务的答案空间有限,利用最终结果作为探索奖励的依据可行且高效,解决了序列级探索的指数复杂度难题。
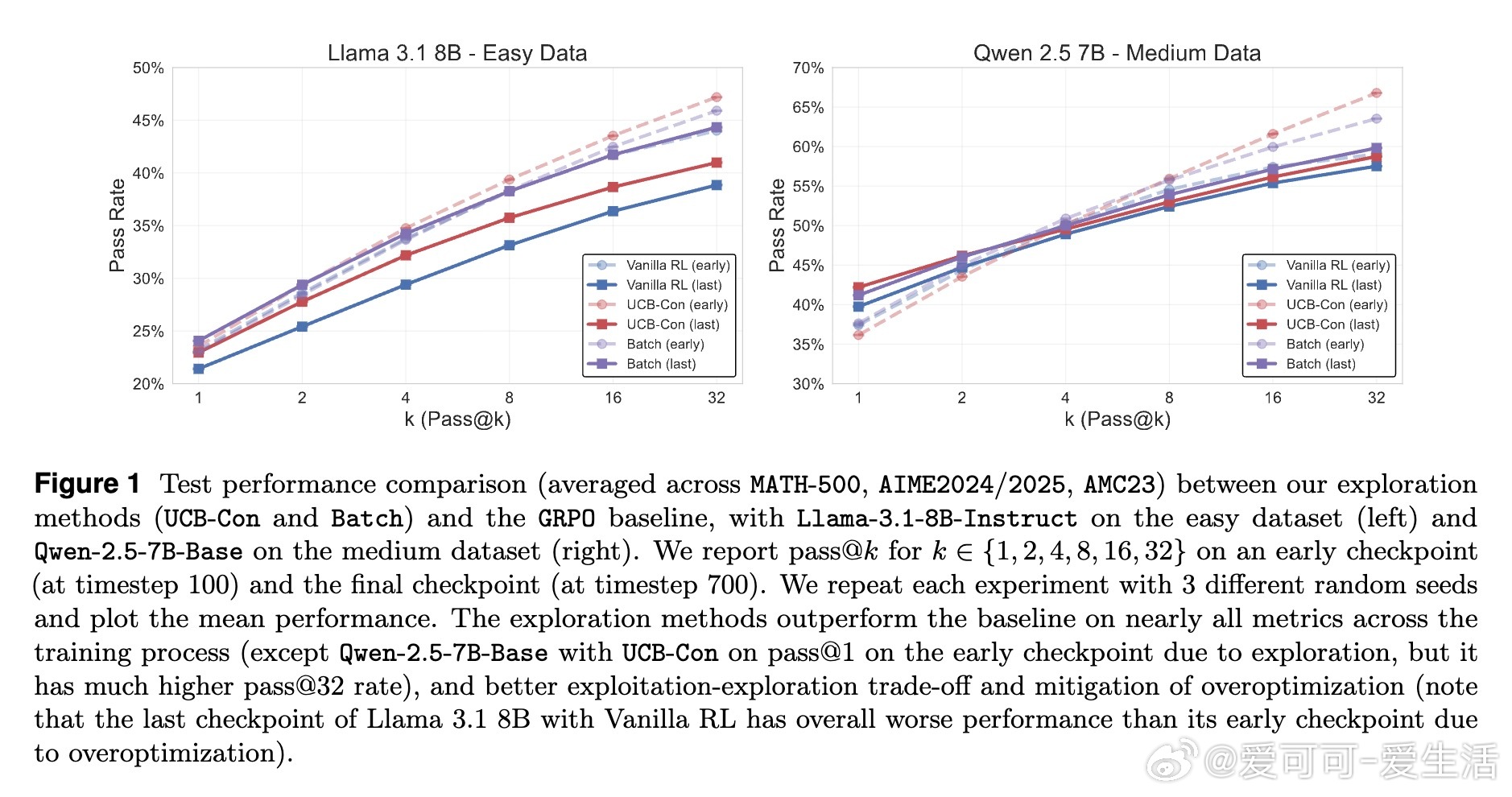
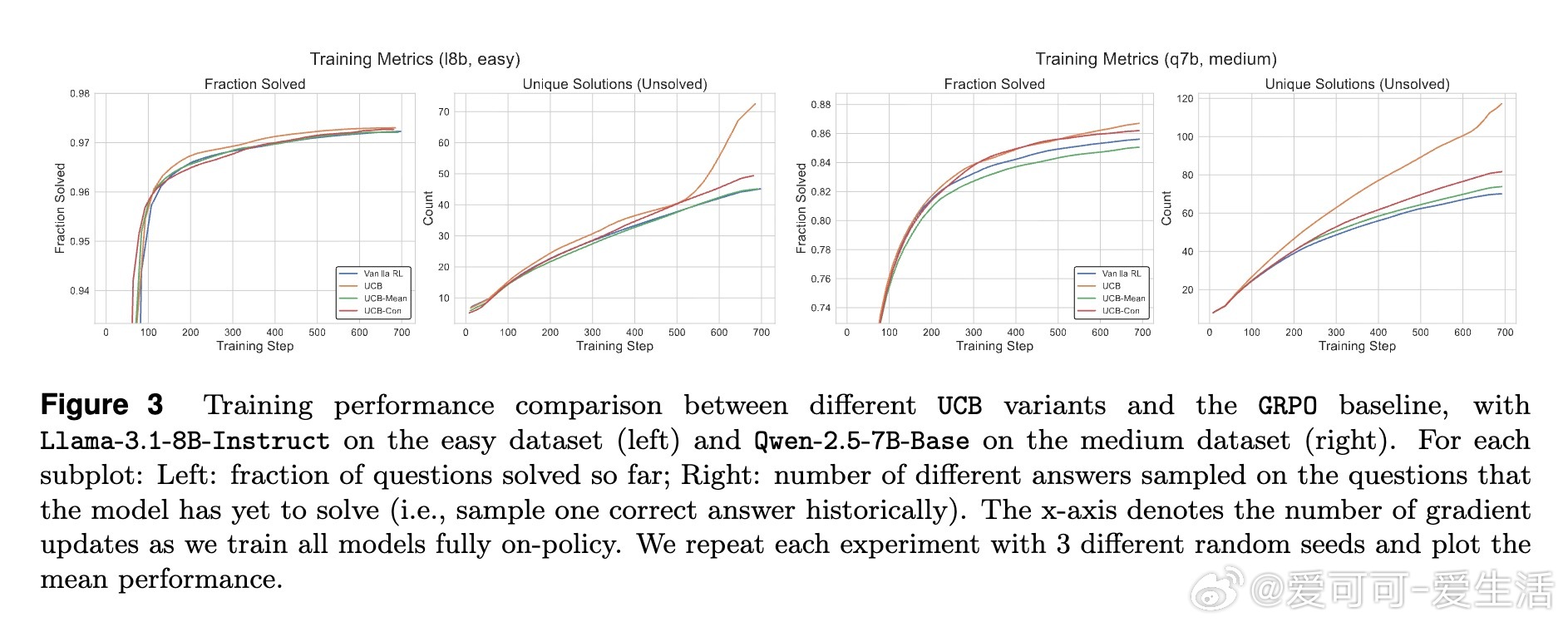
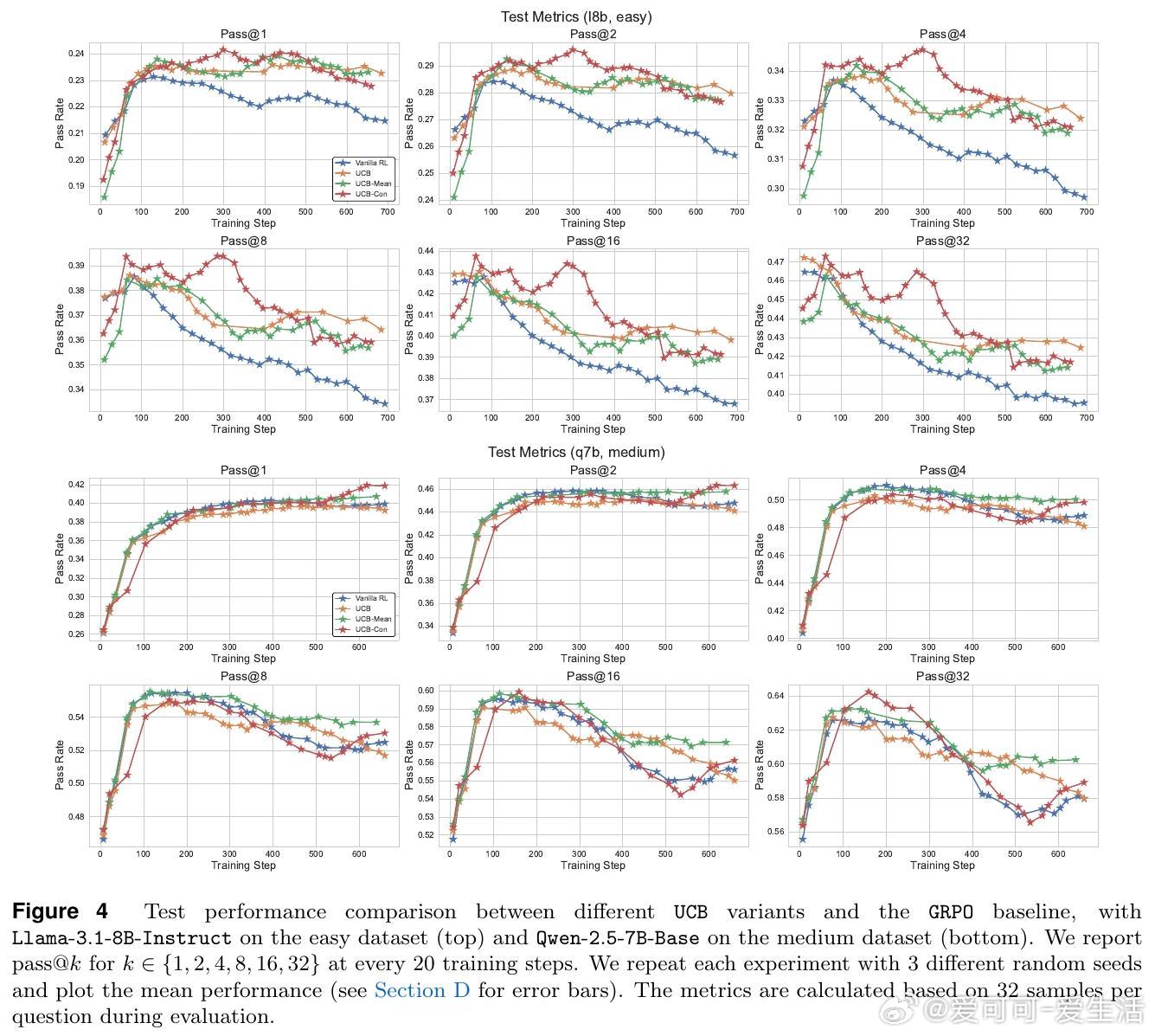
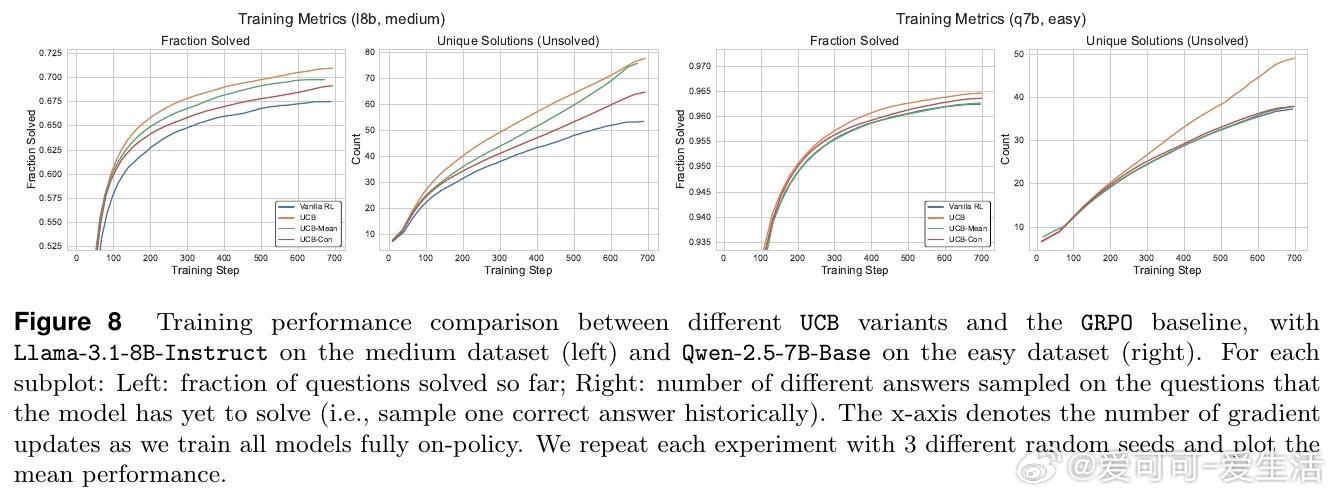
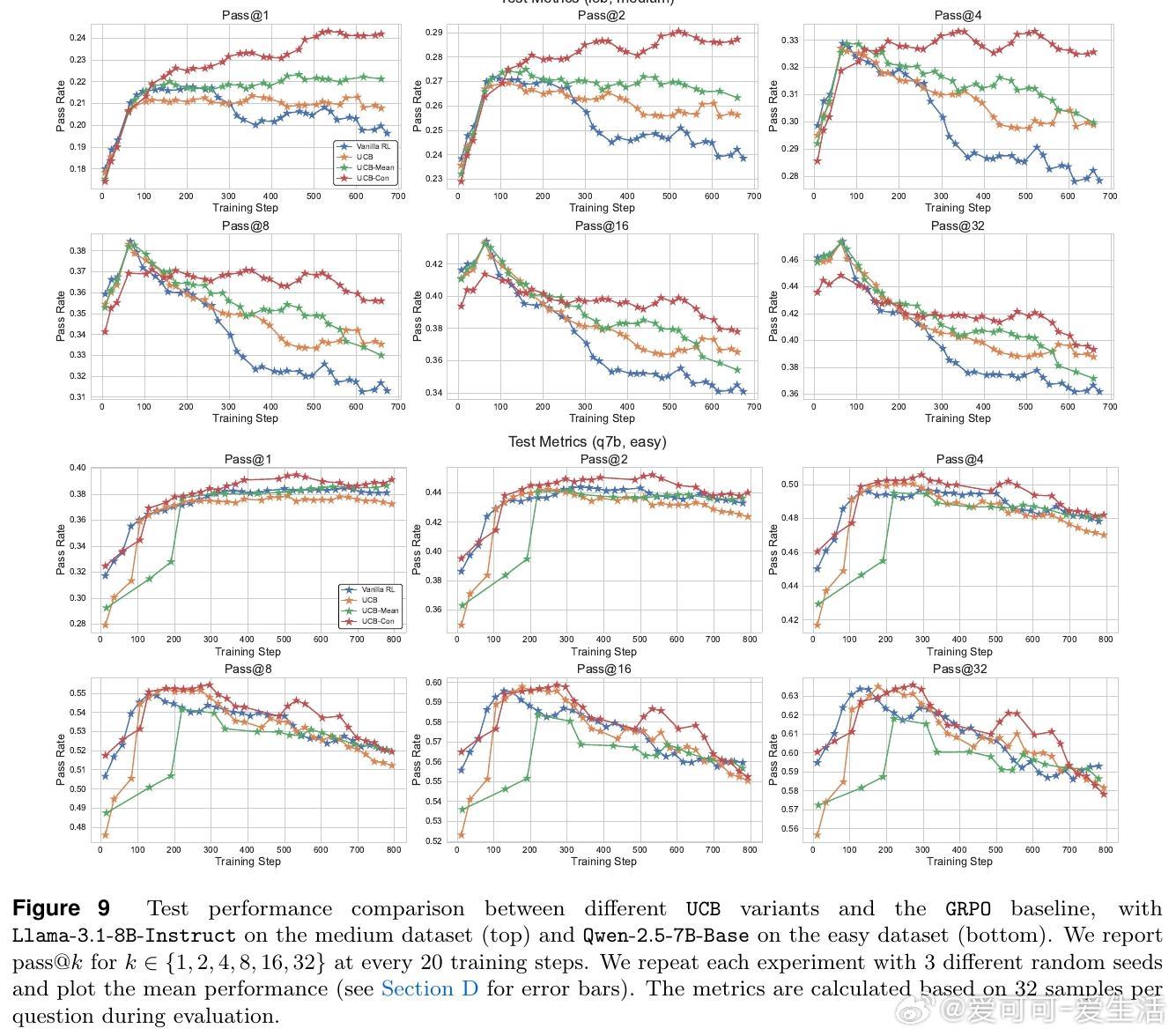
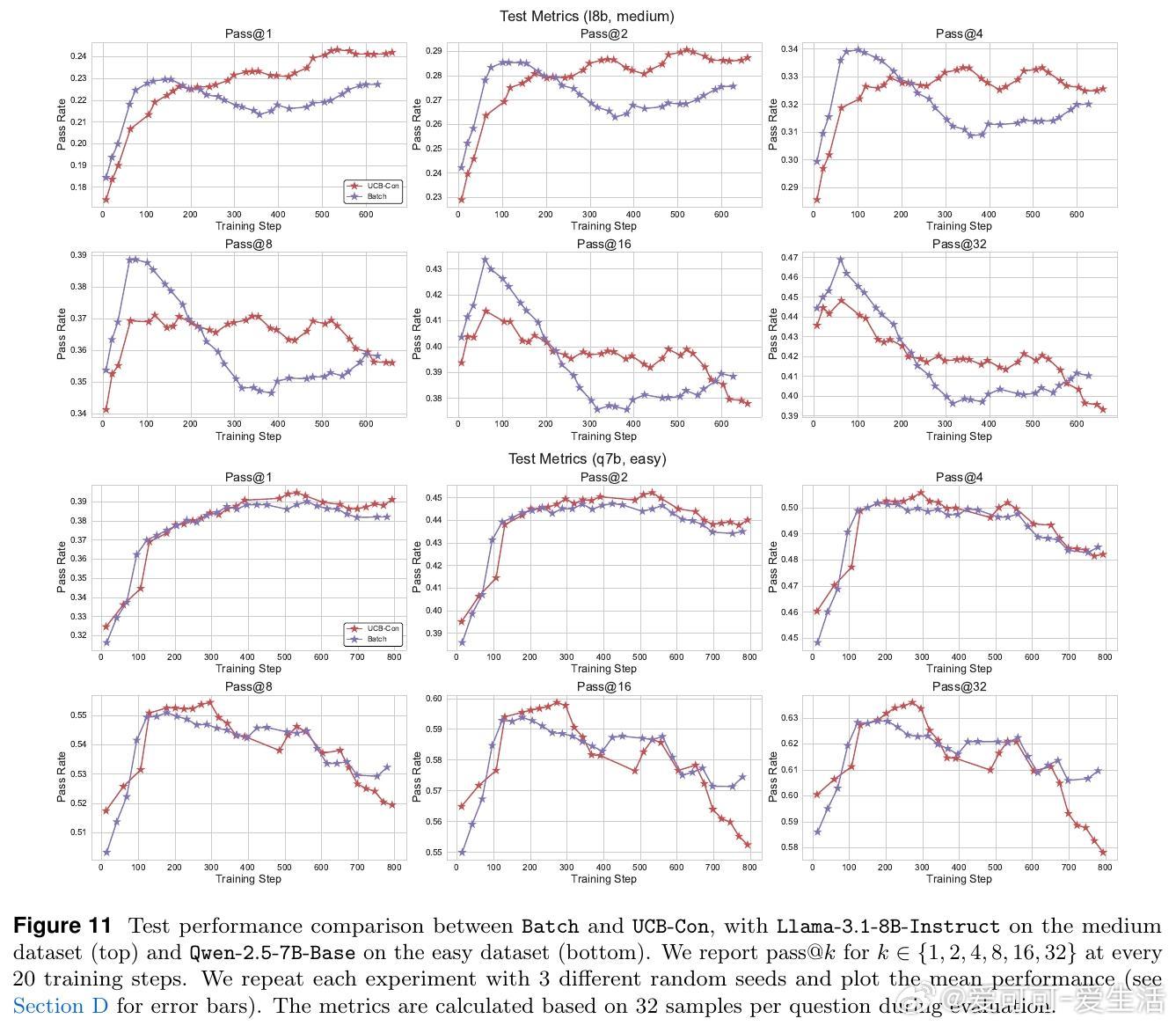
• 提出两大探索策略:历史探索(UCB-Mean与UCB-Con)通过正负奖励平衡促进训练多样性与测试泛化;批次探索(Batch)惩罚同批次重复答案,专注提升测试时多样性与准确率的权衡。
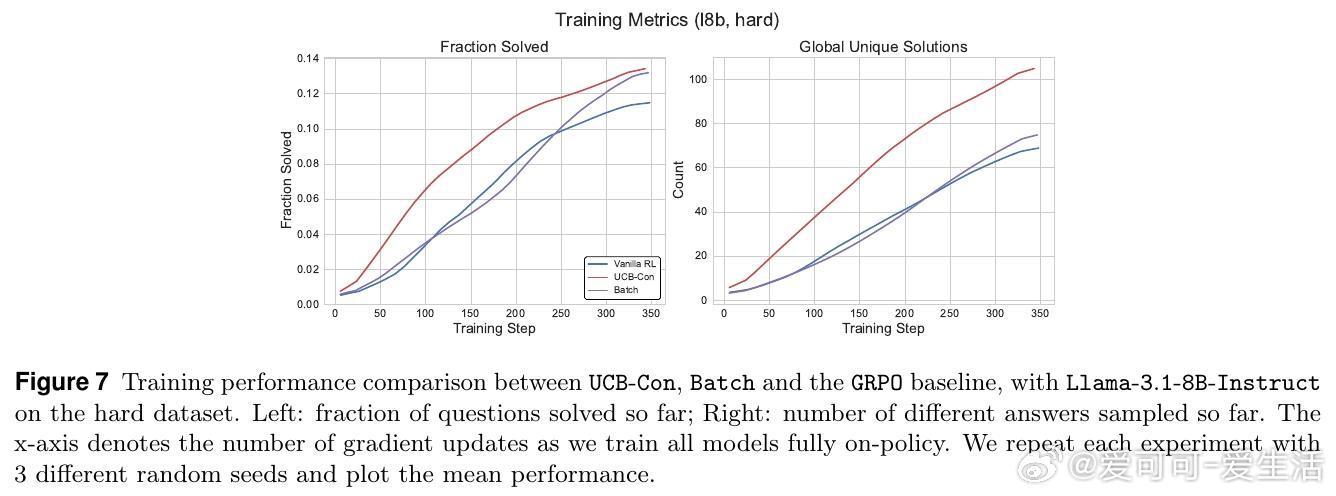
• 实验证明,这两类方法在Llama与Qwen模型及多难度数学推理数据集上均显著优于传统RL策略,尤其缓解了过拟合和多样性坍缩问题。
• 理论上,构建了基于结果的Bandit模型,证明在合理泛化假设下,UCB风格的结果探索可实现与答案数量相关的次线性遗憾界,具备坚实的理论基础。
心得:
1. 多样性非仅测试指标,训练过程中的多样性保持同样关键,忽视这点易导致模型陷入局部最优。
2. 利用“答案空间有限”这一特征突破了传统RL探索在高维输出空间中的难题,实现了探索奖励的有效简化。
3. 历史探索与批次探索互为补充,前者扩展训练覆盖,后者优化测试表现,二者结合为实现高效且多样的推理能力提供了实用路径。
🔗 arxiv.org/abs/2509.06941
大语言模型强化学习模型多样性推理能力探索策略机器学习理论