[LG]《The Majority is not always right: RL training for solution aggregation》W Zhao, P Aggarwal, S Saha, A Celikyilmaz... [FAIR at Meta & CMU] (2025)
在解决复杂推理任务时,“多数派答案不一定正确”——AggLM通过强化学习显著提升了大语言模型(LLM)多解聚合策略的效果。
• 传统多数投票与奖励模型排序易忽视少数但正确的答案,无法充分利用候选解中的部分正确信息。
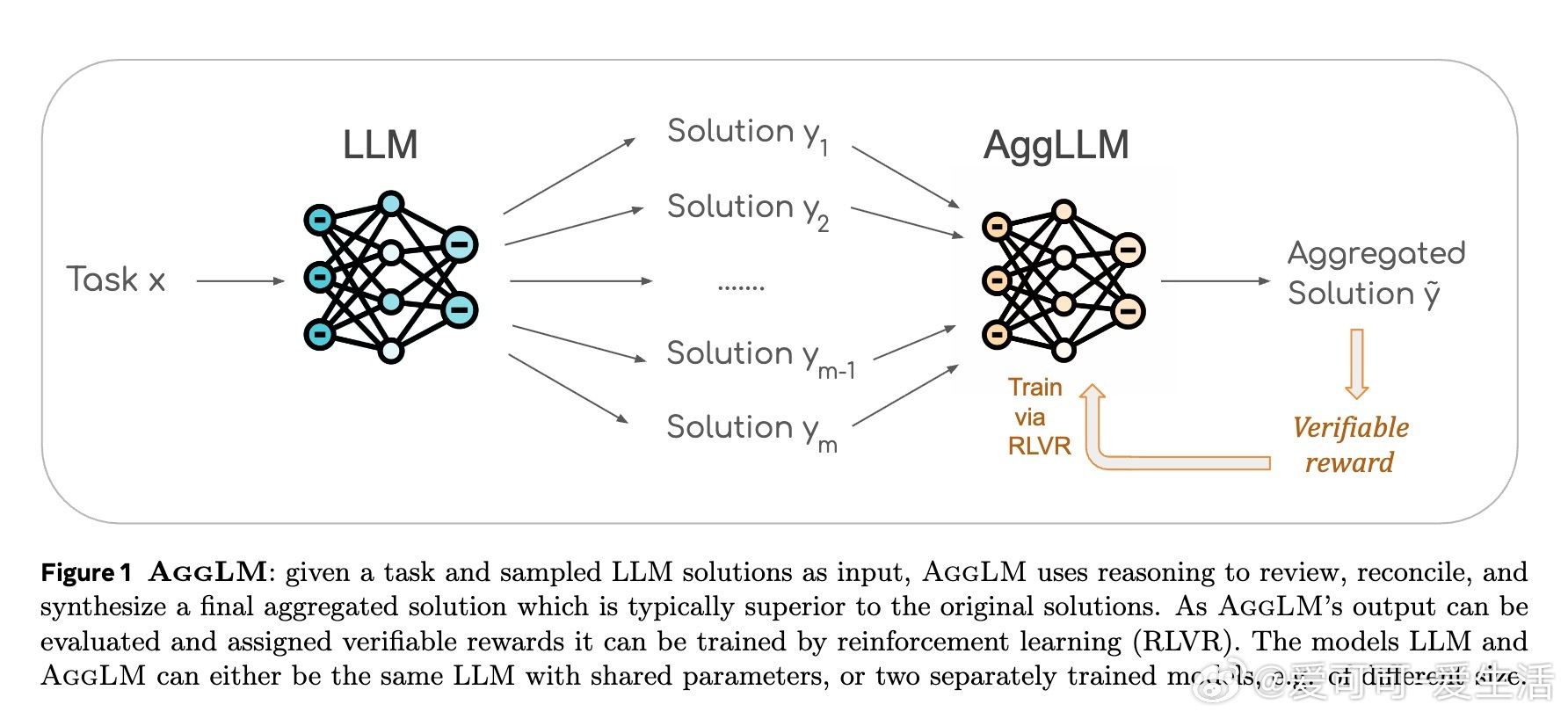
• AggLM将聚合视为一种推理技能,利用RLVR(基于可验证奖励的强化学习)训练聚合模型,能审查、协调并综合多个候选解,生成最终精准答案。
• 训练时巧妙平衡易解与难解样本,提高模型识别少数正确解和多数正确解的能力,避免训练偏差。
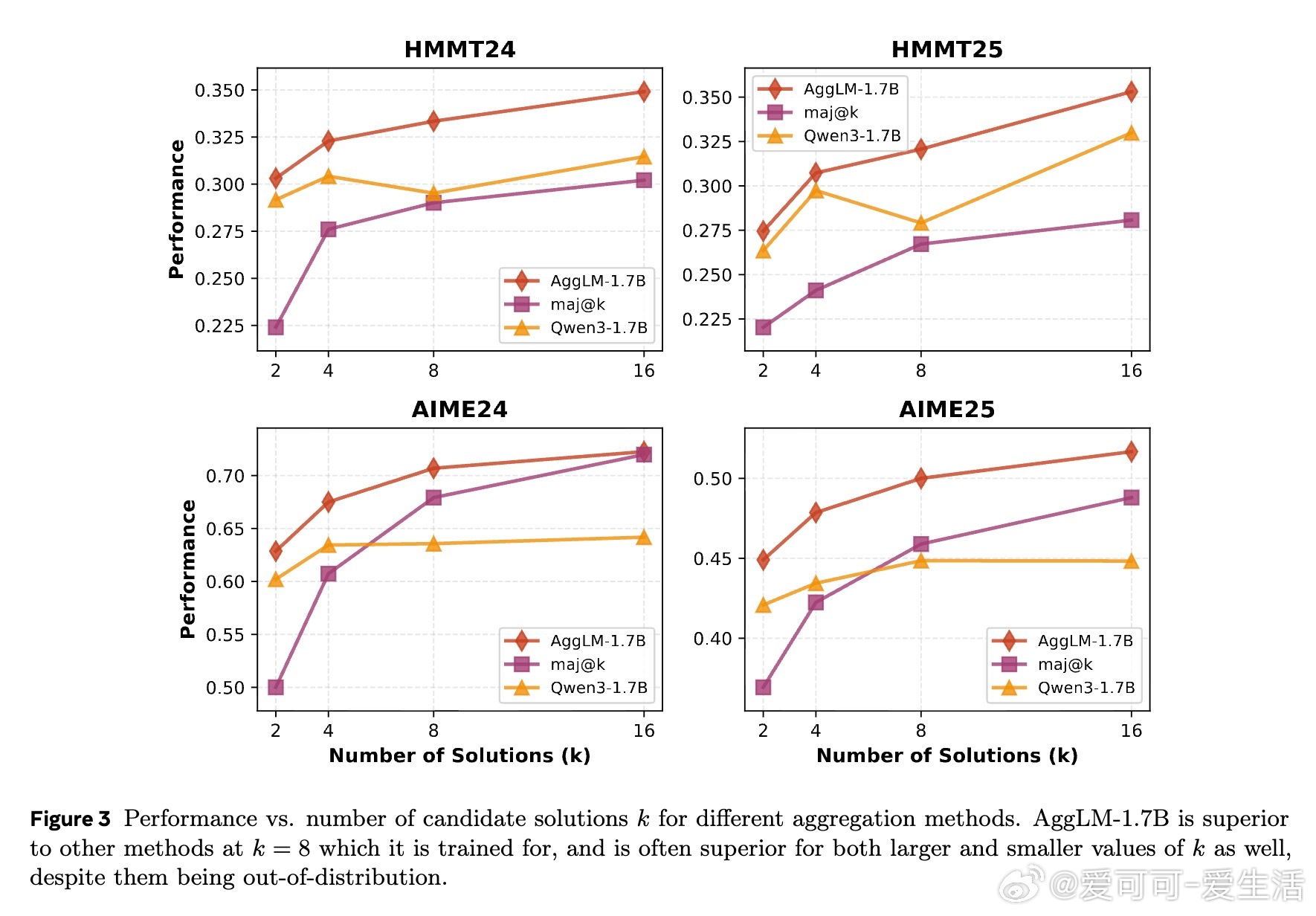
• 在四大数学竞赛数据集(AIME24/25、HMMT24/25)上,AggLM-1.7B均超越传统多数投票、奖励模型和无训练提示聚合,且在面对更强模型(Qwen3-8B)及非思考模式输入时表现依旧稳健。
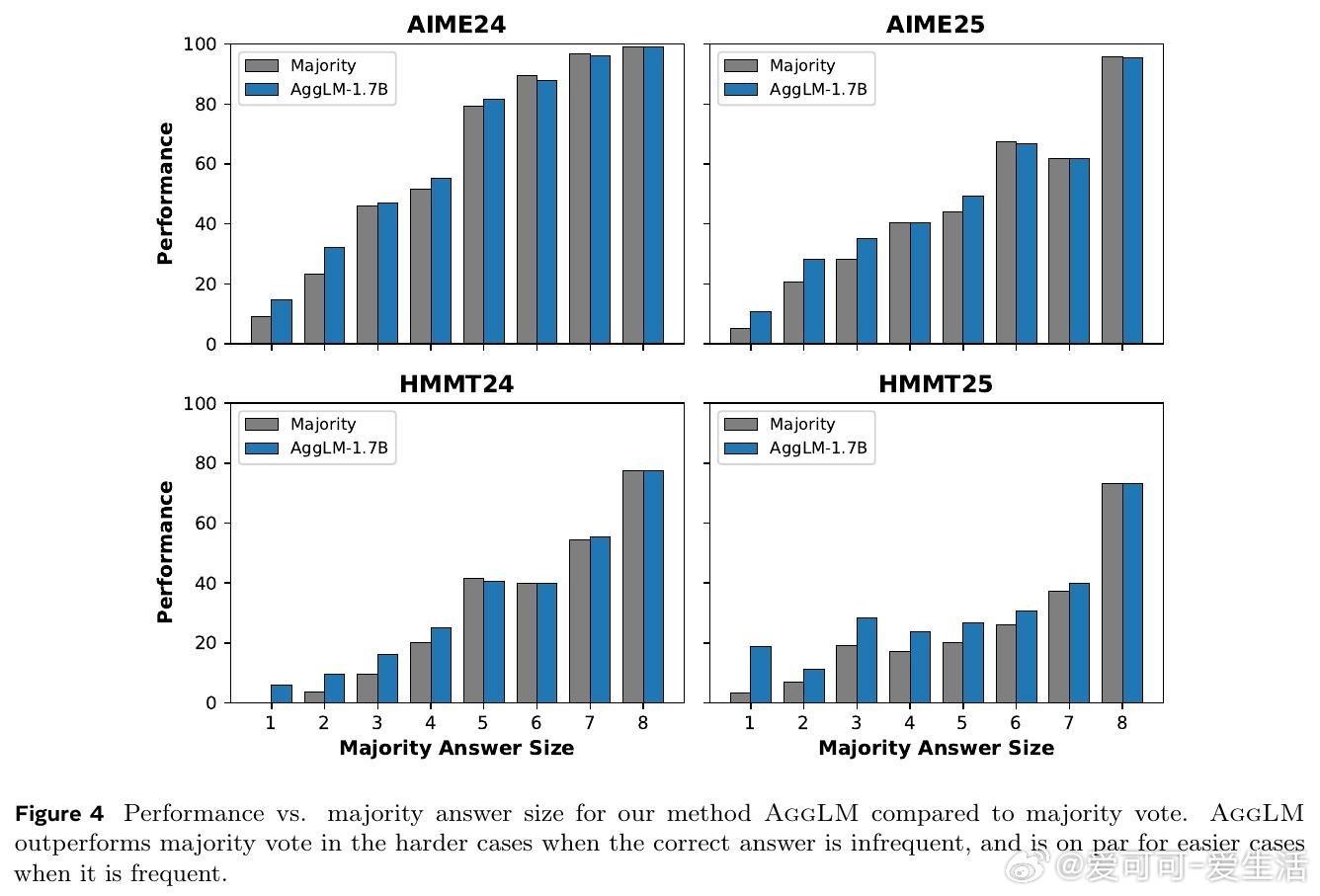
• AggLM在解答多样性高(少数正确解比例大)时优势尤为明显,且相较增加采样数的多数投票,AggLM用更少token实现更优精度,推理成本更低。
• 多任务训练表明,聚合能力可与解答生成能力整合于单一模型,未来可简化推理流水线。
心得:
1. 聚合不仅是简单“投票”,而是深度推理能力的体现,能突破模型概率偏差,挖掘隐藏在少数答案中的真知。
2. 训练数据构造需兼顾难易平衡,强化模型在各种挑战场景下的泛化与纠错能力,而非单纯强化多数正确。
3. 聚合策略的有效性远超单纯增加采样数量,体现了推理质量远比数量更关键,节约计算资源的同时提升模型表现。
了解详情🔗arxiv.org/abs/2509.06870
大语言模型强化学习推理聚合人工智能数学竞赛