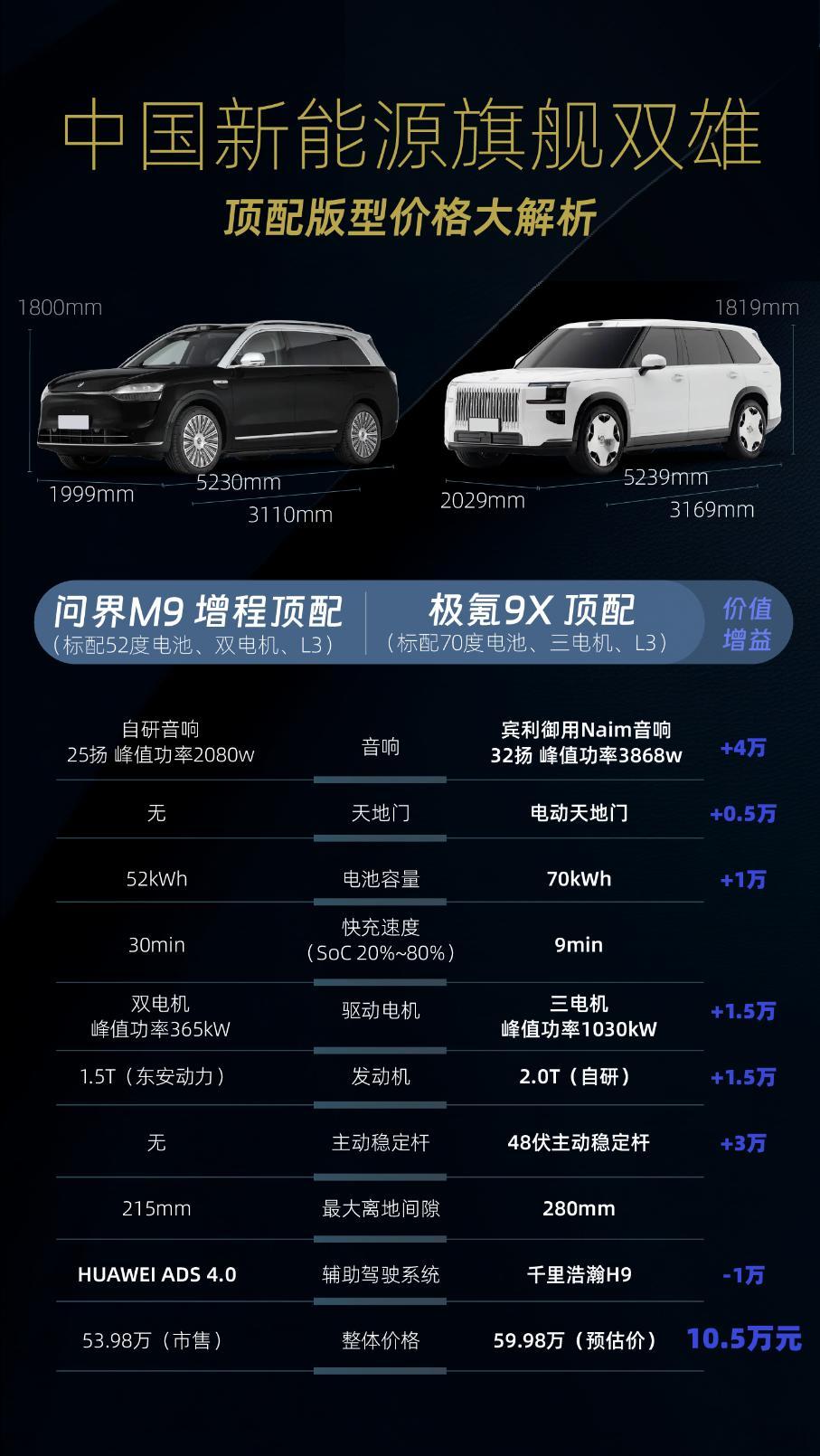
“中美差距究竟有多大?”DeepSeek创始人梁文峰再次语出惊人!他说:“我们经常说中国AI和美国有一两年差距,但真实的差距是原创和模仿之差。如果这个不改变,中国永远只能是追随者,所以有些探索也是逃不掉的。”
在他看来,英伟达现在之所以能够如此成功且领先,就是因为前期以整个西方技术社区和产业做支撑,而梁文峰团队现在正是为了这个过程做努力。 就拿英伟达的“生态护城河”来看。CUDA平台从2006年正式推出到现在,光开发者就攒了1500万,相当于把全球AI工程师的三分之一都拉进了自家群聊。 更绝的是配套的TensorFlow、PyTorch这些框架,表面上是开源软件,实则是给CUDA量身定做的“装修套餐”——2023年GitHub上基于CUDA的AI项目有280万个,占整个AI开源项目的63%,这种垄断程度跟当年Windows统治PC市场差不多。 反观中国,华为昇腾的CANN架构2018年才上线,开发者刚到200万,百度飞桨2016年起步,生态项目数不到英伟达的零头,这差距就像人家已经在CBD盖了摩天大楼,咱们还在郊区打地基。 而梁文峰说的“原创与模仿”差,本质差在技术社区的“化学反应”。 西方AI技术社区玩的是“核聚变模式”——高校实验室出论文,开源社区快速迭代,企业产品紧跟落地。 比如Transformer架构2017年由谷歌团队提出,同年就被HuggingFace做成开源模型,2018年OpenAI就用它搞出GPT-2,这种“论文-代码-产品”的流水线速度,让技术像滚雪球一样越滚越大。 中国呢,2021年提出的“悟道”大模型,虽然参数规模全球领先,但配套的开源工具链到2023年才勉强补齐,中间差的这两年,足够西方社区把技术迭代三轮了。 产业支撑这块差距更像“豪华套餐”与“单点外卖”的区别。英伟达背后站着整个西方科技产业链——台积电给它造最先进的芯片,微软亚马逊买它的算力搭云服务,斯坦福MIT帮它养人才。 2023年英伟达光数据中心业务就赚了300亿美元,相当于每天进账8200万美元,这种现金流能让它每年砸150亿美元搞研发,比中国前十AI企业研发投入总和还多。 中国AI企业呢,华为昇腾虽然进了国内政务云市场,但海外订单几乎为零,商汤旷视这些公司靠政府项目活着,2023年平均研发投入35亿元人民币,连英伟达的零头都够不着,巧妇难为无米之炊,没钱怎么搞原创? 最扎心的是“技术话语权”的差距。IEEEXplore数据库里,2023年AI领域高被引论文中,美国团队主导的占42%,中国占28%,看着差距不大,但核心算法专利差了不止一个数量级。 美国在深度学习领域的核心专利有3.2万项,中国只有1.1万项,而且很多还是“应用层”专利,就像人家掌握了发动机技术,咱们只发明了更舒服的座椅。 英伟达的CUDA虽然是闭源系统,但通过开源社区把标准定死了,中国想搞自己的架构,就得先说服开发者放弃“现成套餐”改吃“定制菜”,这难度跟让北方人顿顿吃米饭差不多。 但梁文峰团队想做的,其实是给中国AI补“社区课”。他们搞的DeepSeek-R1模型,故意选了跟GPT-4不同的技术路径,用“稀疏注意力”算法降低算力消耗,这种“绕开大路走小路”的策略,有点像当年安卓绕开iOS搞开源。 可难就难在,西方社区几十年积累的“技术默契”不是一朝一夕能学来的——比如HuggingFace的Transformers库,随便改一行代码都有上千开发者帮你挑毛病。 中国的开源项目改代码,有时候三天都等不到一个反馈,这种社区活跃度的差距,就像热闹的菜市场和冷清的便利店。