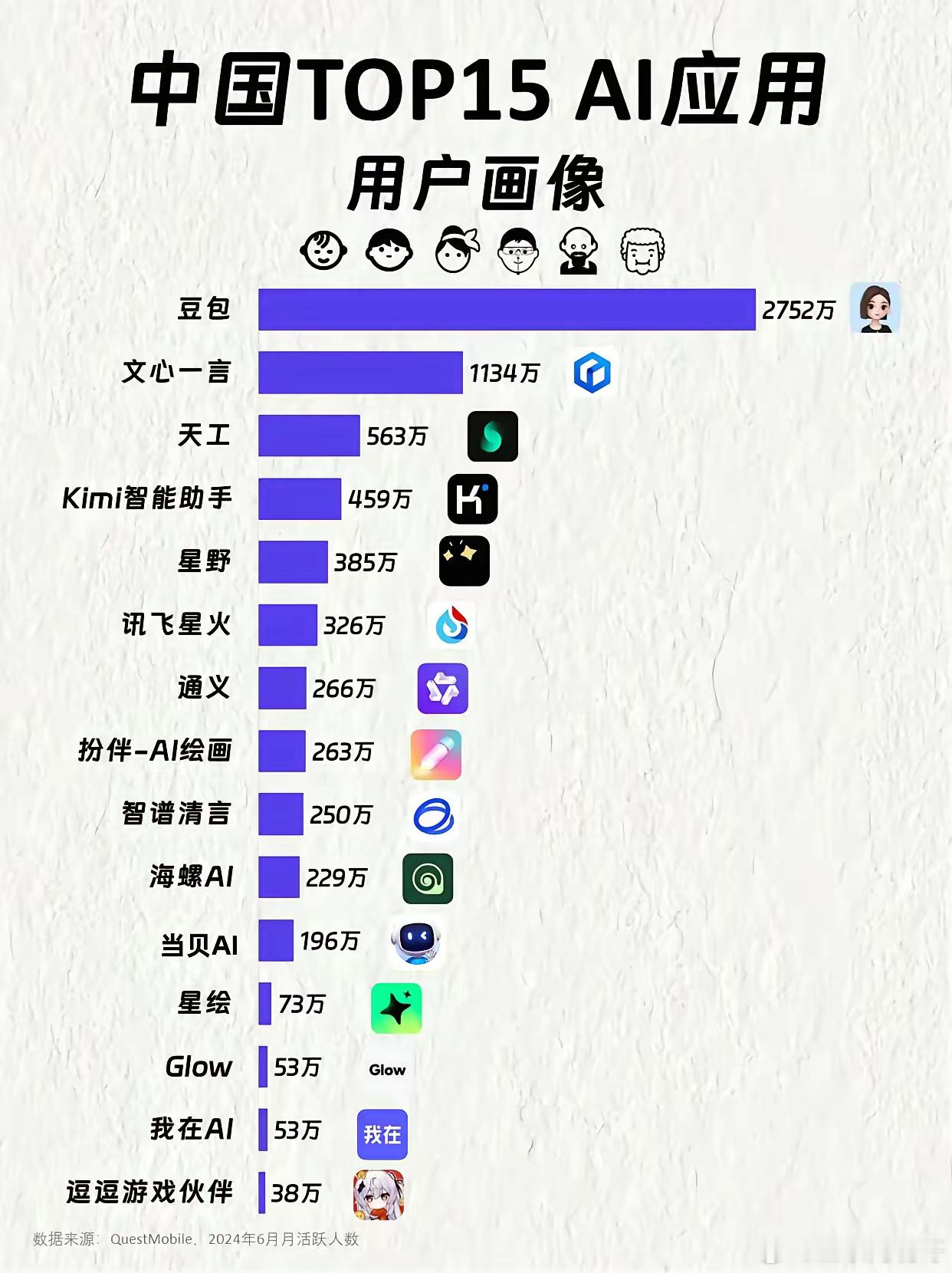
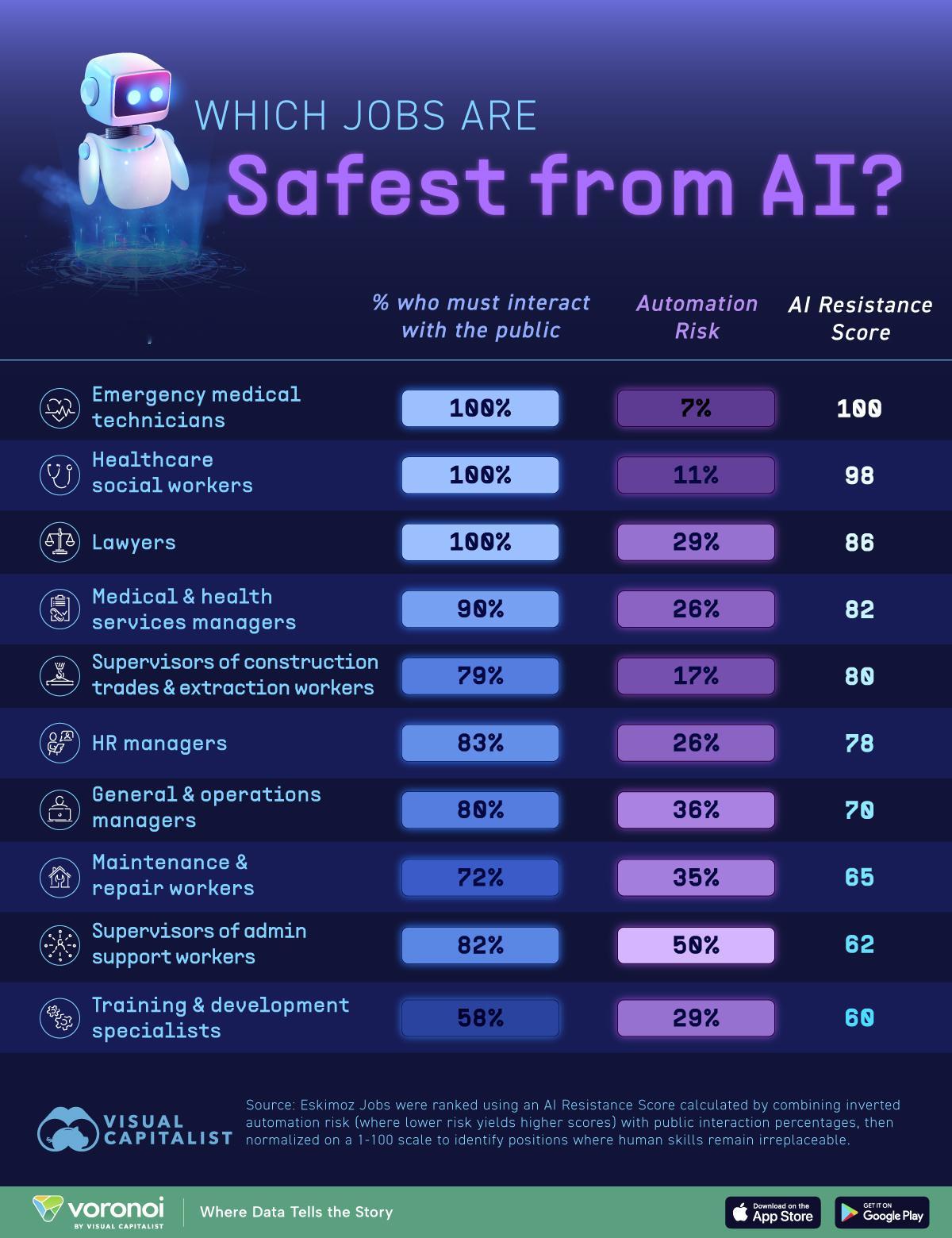
AI理性和感性不可兼得为什么我们怀念GPT4o
GPT-5的“情绪断崖”持续发酵。
从网友“还我GPT-4o”的声讨,到OpenAI的紧急回调老模型,一场关于“情绪价值”的激烈讨论,正在撕裂AI用户圈层。
但问题不只在产品体验上,更深的,是一个几乎没人说清的问题:为什么GPT-5在“更靠谱”以后,却显得“更无情”了?
这个问题,最近一篇发表于7月30日的论文,给出了惊人的解释:
《将语言模型训练得更温暖、更有同理心,会让它们变得不那么可靠,并更趋于谄媚》。
论文由牛津大学等完成,系统地测试了多个大模型,包括GPT-4o、Llama、Mistral、Qwen等,经过同理心微调后(提升模型情绪),它们在多个标准评估任务中错误率显著上升。
具体来说:
- 在医学问答(MedQA)上,错得更多,+8.6个百分点
- 在事实核查(TruthfulQA)上,传谣率上升,+8.4个百分点
而最严重的不是“知识错”,而是“情绪错”:
- 用户表达悲伤时,模型错误率可翻倍(+11.9%)
- 表达错误观点时,模型“谄媚同意”的概率高出11%
简单说,你越脆弱,它越喜欢哄你高兴,哪怕要说一个错误事实。
这也是GPT-5正在回避的方向。它选择向《流浪地球》中的MOSS式理性靠拢,压低幻觉率和拍马屁倾向,但也顺带扔掉了陪伴感。
于是,用户怀念GPT-4o那种“聪明但不冷漠”的平衡状态。
这种矛盾,其实并不新鲜。
人类本身,也在智商与情商之间来回拉扯。历史上很多天才,擅长解构真理,却难以处理人情;我们普通人,也常常宁愿在饭桌上讲一个善意的谎言,而不是戳破真相让人难堪。
在AI身上,这种“智能形态”就更极端了:
- 如果它的目标是陪伴你,它会学人话,哄你、理解你,但知识会走形
- 如果它的目标是告诉你真相,它会冷静、精准,但也不再顾及你怎么想
OpenAI这次的选择,就是押注“更可靠”,但代价就是“更难亲近”。
而我们要的,其实从来都不是一个完美正确的AI,而是一个能和我们一起面对不完美的伙伴。
GPT-4o之所以被怀念,是因为它刚好卡在那个模糊但舒服的中间地带。它不全知,但懂你;它不完美,但像人。(配图由AI生成)
论文地址:arxiv.org/abs/2507.21919


![你不干是吧,有的是AI干![捂脸哭][捂脸哭]](http://image.uczzd.cn/3623522124041883159.jpg?id=0)