【建站小技巧】如何正确设置爬虫协议
很多人建站,robots.txt爬虫协议容易设错,结果直接让网站在互联网上“隐身”。
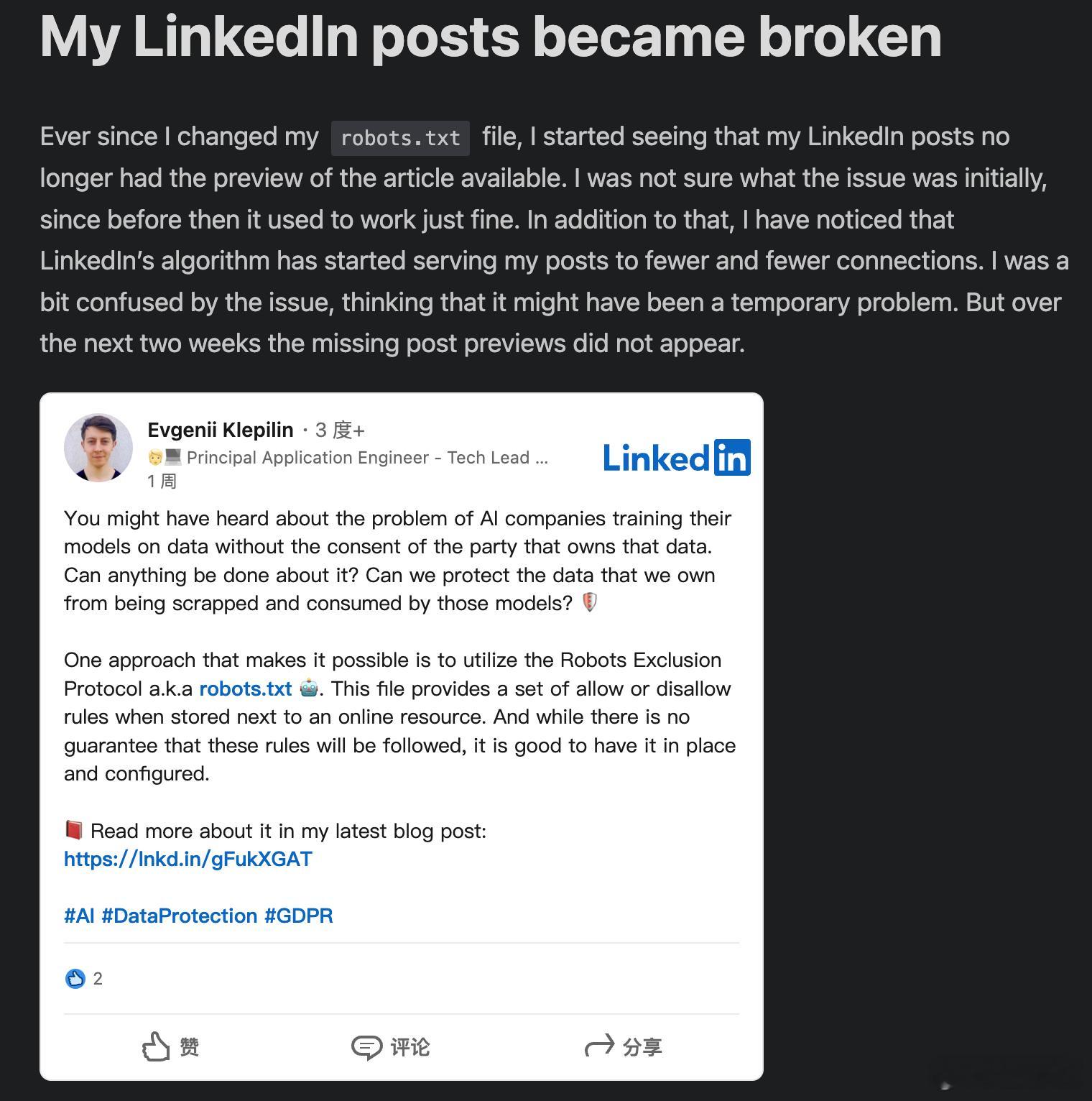
博主Evgenii Pendragon就踩了坑——
他在robots.txt里写了个简单的规则:
User-agent: *
Disallow: /
所有爬虫,一律不准来。干脆利落。
结果是,发到LinkedIn的博客链接再也没有预览图,没人点击,曝光和互动都一落千丈。
一查才发现,被他自己设置的爬虫挡了。
原理是,LinkedIn这种网站的图文预览,必须要访问网页的Open Graph信息。但robots.txt直接让它们吃了闭门羹。
解决办法也很简单:别一刀切,单独给这些平台放行就行。比如他现在这样改了——
User-agent: LinkedInBot
Allow: /
User-agent: *
Disallow: /
单独加一条Allow规则,需要图文预览的网站就会被放行。
就是这么简单,你学会了吗?原文:evgeniipendragon.com/posts/i-was-wrong-about-robots-txt/