陈丹琦在ICLR上主题演讲如何在学术预算下训练语言模型
计算资源不足、数据访问受限……学术研究者该怎样训练语言模型?
一直以来,训练语言模型这一领域几乎完全由工业界主导。
它依靠海量计算资源驱动,并遵循奖励更大模型与数据集的scaling law。
但对于学术研究者而言,参与其中常令人望而却步。
就在昨天,陈丹琦在ICLR 2025上进行了名为《学术界训练语言模型:挑战还是使命?》的主题演讲,分享了自己在过去两年间的研究成果。【图1】
总结而言,她提出了学术研究者能做出重要贡献的三个方向:
1. 开发小而精的模型
2. 理解与改进训练数据
3. 基于开源权重模型发展后训练方法。
她列举了几项团队的成果进行说明:
一、剪枝优化LLaMA【图2】
基于现有LLM进行结构化剪枝。通过复用LLaMA-7B模型的子网络架构和执行持续预训练优化,最终仅使用了相当于从头训练的3%的计算成本,就实现了更好的性能效果。
二、QuRater评分模型【图3】
高质量预训练数据的选择对构建强大语言模型至关重要。通过训练QuRater评分模型,将成对判断转化为标量评分,并据此对2600亿token的训练语料进行四维质量标注。
在实验中,团队根据不同质量评分筛选出300亿token的数据,并基于这些数据训练了13亿参数的语言模型。研究发现,平衡数据质量与多样性至关重要。
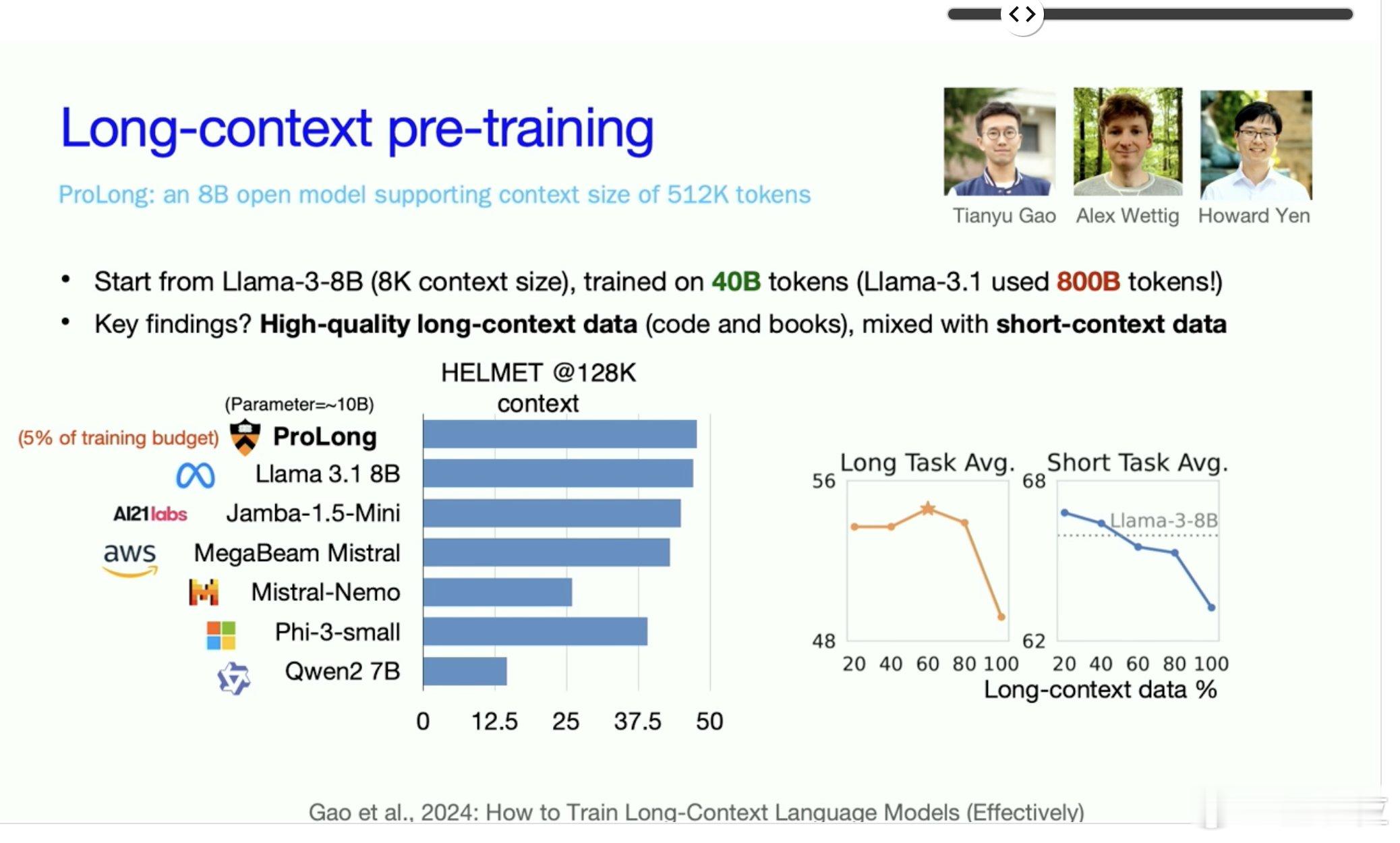
三、ProLong模型【图4】
ProLong是一个支持512K token上下文长度的80亿参数开源模型。通过持续训练与监督微调技术,提升了长上下文信息的利用效率。
最终推出的ProLong-8B模型基于Llama-3初始化,使用400亿token训练,在128K上下文长度下达到同规模模型的顶尖水平。尽管长上下文训练数据量仅为Llama-3.1-8B-Instruct的5%,ProLong在多数长上下文任务中表现更优。
在演讲的最后,她总结道:仅需数百GPU小时,就能开展严肃的语言模型训练研究。甚至偶尔能打造顶尖水平的模型!
她希望,意识到这一点能够促进学术界更广泛参与语言模型训练,并推动产学研合作的新范式。