
mmBERT是一个纯编码器架构的语言模型,在1800多种语言、3万亿tokens的文本上完成了预训练。它的架构设计借鉴了ModernBERT,但又加入了不少创新点,比如逆掩码比率调度和逆温度采样。而且研究团队还把1700多种低资源语言放在了衰减阶段加入训练,这个策略带来了相当不错的效果提升,充分利用了那些数据量本身就不大的语言资源。
模型架构整体架构和ModernBERT保持一致,但换成了Gemma 2的tokenizer来处理多语言输入。base和small两个版本都用了22层网络,中间维度是1152(这点和ModernBERT-base一样),区别在隐藏层维度上:base是768,small则缩减到384。
从参数量来看,base版本的非嵌入参数跟ModernBERT-base持平,都是110M,但因为词表扩大了,总参数量达到307M。small版本总共140M参数,其中非嵌入部分42M。

以往像XLM-R、mT5这些模型里,英文内容占比很低,mT5只有5.7%。但问题是真正高质量的数据(比如过滤过的DCLM)基本都是英文的。所以这次团队提高了英文数据的比例,当然非英语数据仍然占了大头。
非英语部分主要来自FineWeb2,以及它的高质量过滤版本FineWeb2-HQ(覆盖20种语言)。多语言维基百科用的是MegaWika v2,包含60种语言,并且都经过了筛选。英文语料还补充了好几个精选数据集:Dolma里抽取了StarCoder、Stackexchange、Arxiv和PeS2o;Dolmino贡献了数学、筛选过的Stackexchange、Tulu Flan指令数据和书籍;ProLong则提供了代码仓库和教材。
这样一通操作下来,整个数据mix不仅质量更高(得益于DCLM和FineWeb2的过滤),内容类型也更丰富(代码、指令、网页、论文都有),语言和文字覆盖面也更广。
级联退火语言学习(ALL)
Fineweb2数据在训练中的逆温度采样比率变化,τ从0.7降到0.5再到0.3
以前的做法是固定语言集合,用设定好的温度参数采样多语言数据。这次论文作者则换了个思路:训练过程中动态调整温度,同时逐步添加新语言进来,有点像对语言做退火处理。
低资源语言本来预训练数据就少,质量也相对一般(毕竟可筛选的余地不大)。怎么最有效地利用这些语言的数据,同时又不过度重复训练(避免超过5个epoch),还得保证整体数据质量?答案是先从高资源语言起步,训练过程中慢慢加入其他语言。每次加入新语言时重新采样比例,让分布逐渐从偏向高资源转为更均匀。这样既避免了在低资源数据上反复训练,又能让新语言借助已有的语言基础快速学习。
起步阶段用60种语言(外加代码),覆盖了主要的语系和文字。然后扩展到110种,纳入那些数据量还可以的"中等资源"语言(超过2亿tokens)。最后把FineWeb2里的所有语言都加进来,1833种语言、1895个语言-文字组合。温度参数也相应从0.7降到0.5,再降到0.3。最后这步特别关键,利用衰减阶段的学习机制,能让性能快速拉升。
训练流程训练分三个阶段,跟ModernBERT类似,但掩码率调度方案做了改进。不是简单地在最后降低掩码比例,而是每个阶段都在逐步降低。mmBERT small的权重初始化还用了个技巧,从base版本通过跨步采样来初始化。

基础预训练阶段
这个阶段涵盖梯形学习率的warmup和稳定期,训练了2.3T tokens。学习率和batch size都有warmup过程。数据里没有过滤版的FineWeb2和高质量DCLM,只用60种语言(加代码),掩码率从30%开始。
上下文扩展与中期训练
这时候数据质量提升了,切换到各数据集的高质量过滤版本。RoPE参数调整到能处理8192 tokens(theta设为160k),全局层和局部层都适用。语言数量增加到110种(加代码)。这个阶段训练600B tokens,继续稳定期,掩码率降到15%。
衰减阶段
采用逆平方根学习率调度,衰减100B tokens,最终降到峰值的0.02倍。跟ModernBERT和Ettin不同,这里掩码率选的是5%。用了三种不同的数据配置,产出三个变体:Decay-Eng专注英语、Decay-Cont延续110种语言、Decay-All包含全部1833种FineWeb2语言。
模型合并
合并策略是为了整合各衰减混合的优势。base版本从每个混合里挑最好的checkpoint,用TIES-merging减少参数冲突。small模型跨混合合并效果不理想,可能因为权重空间较小导致参数一致性不够,所以改用Decay-All checkpoints的指数加权合并,这种方案表现最好。
评估结果测试覆盖了NLU数据集(GLUE、XTREME)、检索基准(英语和多语言MTEB v2、代码检索CoIR)、以及低资源语言评估集(提格雷语TiQuaD、法罗语FoQA)。
对比的baseline包括XLM-R、mGTE、EuroBERT-210m(base规模)、mDistilBERT、Multilingual MiniLM(small规模)、ModernBERT(英语上限参考)和解码器模型Gemma 3 270M。

GLUE英语基准测试结果

XTREME基准测试结果
自然语言理解表现
mmBERT small在英语GLUE上的成绩相当亮眼,平均84.7分,远超MiniLM的78.3,甚至比之前一些base规模的模型还强。mmBERT base虽然训练数据以非英语为主,英语性能还是逼近了ModernBERT(86.3 vs 87.4)。
多语言XTREME上,mmBERT base平均分72.8,超过XLM-R的70.4。分类任务上XNLI得分77.1(XLM-R是74.6),问答任务TyDiQA的F1达到74.5(XLM-R是70.5),提升都挺明显的。

英语检索能力
MTEB v2英语检索测试中,mmBERT模型展现出不小的优势。small版本超过了mGTE和XLM-R,base版本平均53.9分,比mGTE(52.7)高,跟ModernBERT(53.8)基本持平。

多语言检索表现
多语言MTEB v2上,两个mmBERT模型都比同规模对手高出1.5分左右。比如mmBERT base平均54.1,XLM-R是52.4。

代码检索性能
CoIR基准测试中,mmBERT base平均42.2分,远超XLM-R(33.6)这类大规模多语言模型。不过没跑过EuroBERT-210m(45.3),估计是因为EuroBERT用了更高质量的非公开训练数据。

与EuroBERT的对比
即便在EuroBERT的优势语言上,mmBERT base和small在XNLI和PAWS-X上仍然占优。举个例子,阿拉伯语XNLI上mmBERT base得分74.5 F1,EuroBERT只有66.8 F1。
编码器vs解码器
纯编码器的mmBERT模型明显强于同规模的SOTA解码器模型。Gemma 3 270M在XNLI和GLUE上的表现连mmBERT small都不如,再次说明了编码器架构在这类任务上的优势。
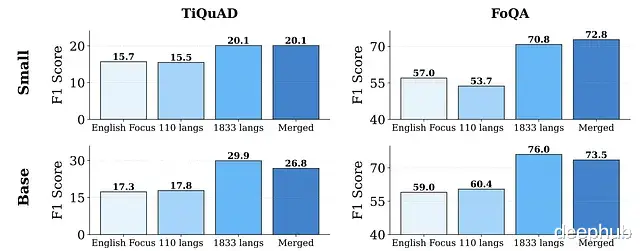
不同衰减阶段模型在提格雷语和法罗语上的表现(这两种语言仅在衰减阶段加入)
退火语言学习的效果
衰减阶段加入更多语言,低资源语言性能提升相当显著。采用1833种语言衰减的mmBERT性能提升很快,base版本在提格雷语上涨了68%,法罗语涨了26%。mmBERT base在FoQA上甚至超过了更大规模的模型,包括Google的Gemini 2.5 Pro和OpenAI的o3。模型合并也帮助保持了性能水平。

运行效率
mmBERT模型比以往的多语言编码器模型快得多、效率也高得多。base版本在可变序列上快了2倍多,长上下文快了约4倍。small版本大概是base的2倍速度,也比其他同规模多语言模型快2倍。
更关键的是,mmBERT支持最长8192 tokens,而MiniLM、XLM-R这些老模型只能处理512 tokens。mmBERT处理8192 tokens的速度跟它们处理512 tokens差不多快。这个效率提升主要归功于Flash Attention 2和unpadding技术。
论文信息mmBERT: A Modern Multilingual Encoder with Annealed Language Learning
https://avoid.overfit.cn/post/a951525907cd4461aff511858297416e
作者:Ritvik Rastogi