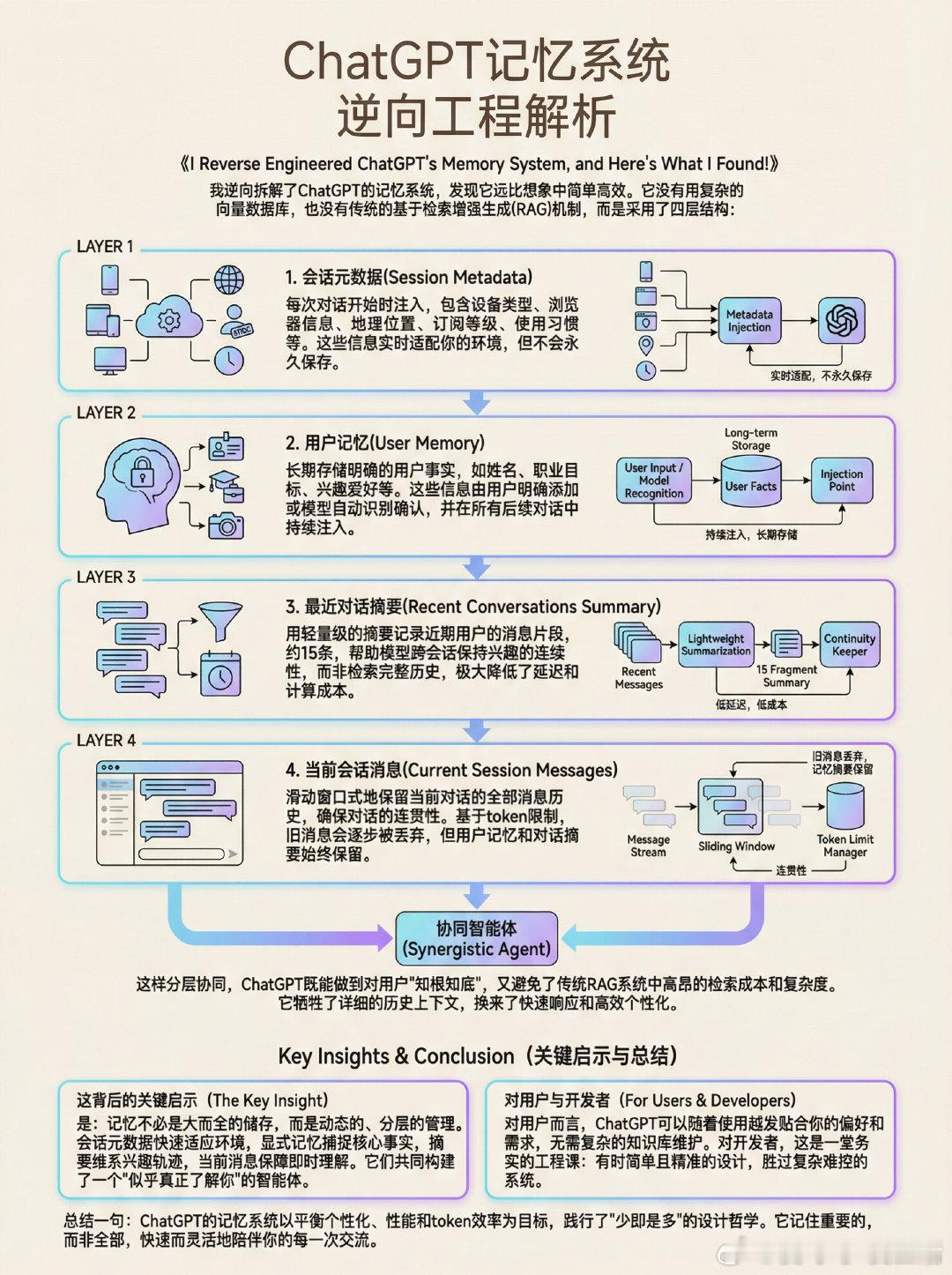
《I Reverse Engineered ChatGPT's Memory System, and Here's What I Found!》我逆向拆解了ChatGPT的记忆系统,发现它远比想象中简单高效。它没有用复杂的向量数据库,也没有传统的基于检索增强生成(RAG)机制,而是采用了四层结构:1. 会话元数据(Session Metadata):每次对话开始时注入,包含设备类型、浏览器信息、地理位置、订阅等级、使用习惯等。这些信息实时适配你的环境,但不会永久保存。2. 用户记忆(User Memory):长期存储明确的用户事实,如姓名、职业目标、兴趣爱好等。这些信息由用户明确添加或模型自动识别确认,并在所有后续对话中持续注入。3. 最近对话摘要(Recent Conversations Summary):用轻量级的摘要记录近期用户的消息片段,约15条,帮助模型跨会话保持兴趣的连续性,而非检索完整历史,极大降低了延迟和计算成本。4. 当前会话消息(Current Session Messages):滑动窗口式地保留当前对话的全部消息历史,确保对话的连贯性。基于token限制,旧消息会逐步被丢弃,但用户记忆和对话摘要始终保留。这样分层协同,ChatGPT既能做到对用户“知根知底”,又避免了传统RAG系统中高昂的检索成本和复杂度。它牺牲了详细的历史上下文,换来了快速响应和高效个性化。这背后的关键启示是:记忆不必是大而全的储存,而是动态的、分层的管理。会话元数据快速适应环境,显式记忆捕捉核心事实,摘要维系兴趣轨迹,当前消息保障即时理解。它们共同构建了一个“似乎真正了解你”的智能体。对用户而言,ChatGPT可以随着使用越发贴合你的偏好和需求,无需复杂的知识库维护。对开发者,这是一堂务实的工程课:有时简单且精准的设计,胜过复杂难控的系统。ChatGPT的记忆系统以平衡个性化、性能和token效率为目标,践行了“少即是多”的设计哲学。它记住重要的,而非全部,快速而灵活地陪伴你的每一次交流。manthanguptaa.in/posts/chatgpt_memory/