GPT开源版有强迫症千万回复暴露开源GPT本性
OpenAI开源模型gpt-oss系列,疑似有“强迫症”,什么问题都会往数学和编程领域靠。
博主jack morris分析了1000万条回复发现,该模型更像是专门为了做基准测试,被RL强化过的“解题机器”。
模型表现一:生成内容聚类高度集中
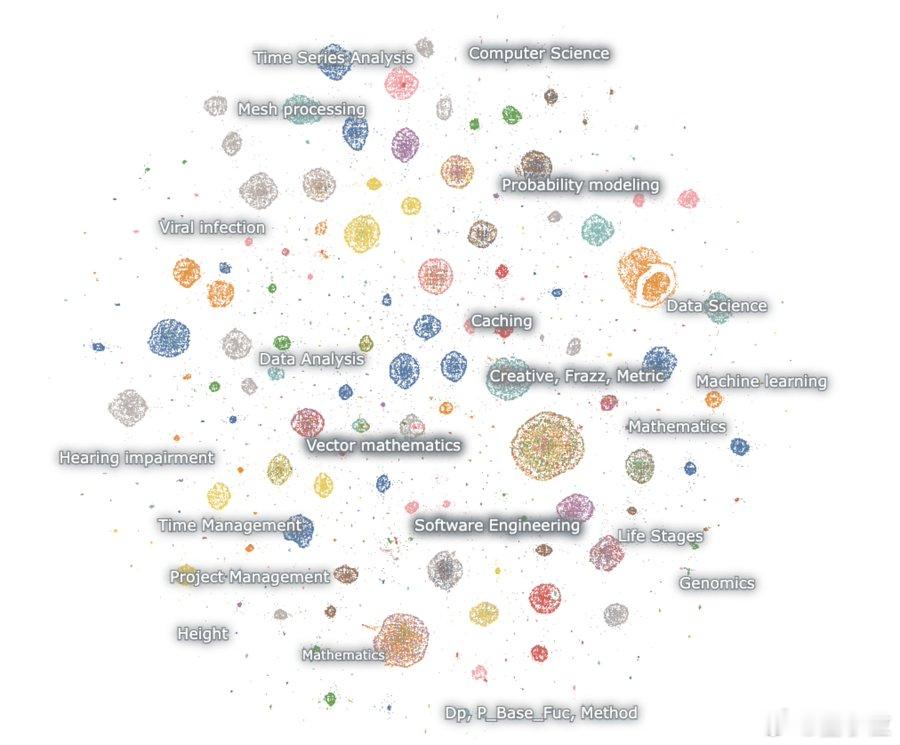
从Embedding可视化(彩色点云图)来看,模型输出内容高度集中于少数几个主题领域:【图1】
其中,数学类主题包括概率建模、机器学习、偏微分方程、拓扑学等;编程类则集中在数据科学、算法竞赛、代理型软件等方向【图2】。
这一分布远远高于自然对话或开放网页文本的多样性,暗示训练数据可能被高度集中于特定推理任务。
模型表现二:风格极度“非自然”
Jack指出,gpt-oss的生成文本几乎没有自然网页的语言特征,也缺乏一般聊天机器人的随意性。相反,它会在没有任何提示的情况下“幻觉”出复杂的Dominos数学题,并自动展开长达3万token的详细推理过程。
这种行为在数据集中出现多达5000多次,几乎呈现出“强迫性做题”的模式。
博主认为,这可能源自训练过程中过度强化对推理类基准任务的适配,从而在自由生成中反复触发“解题”模式。
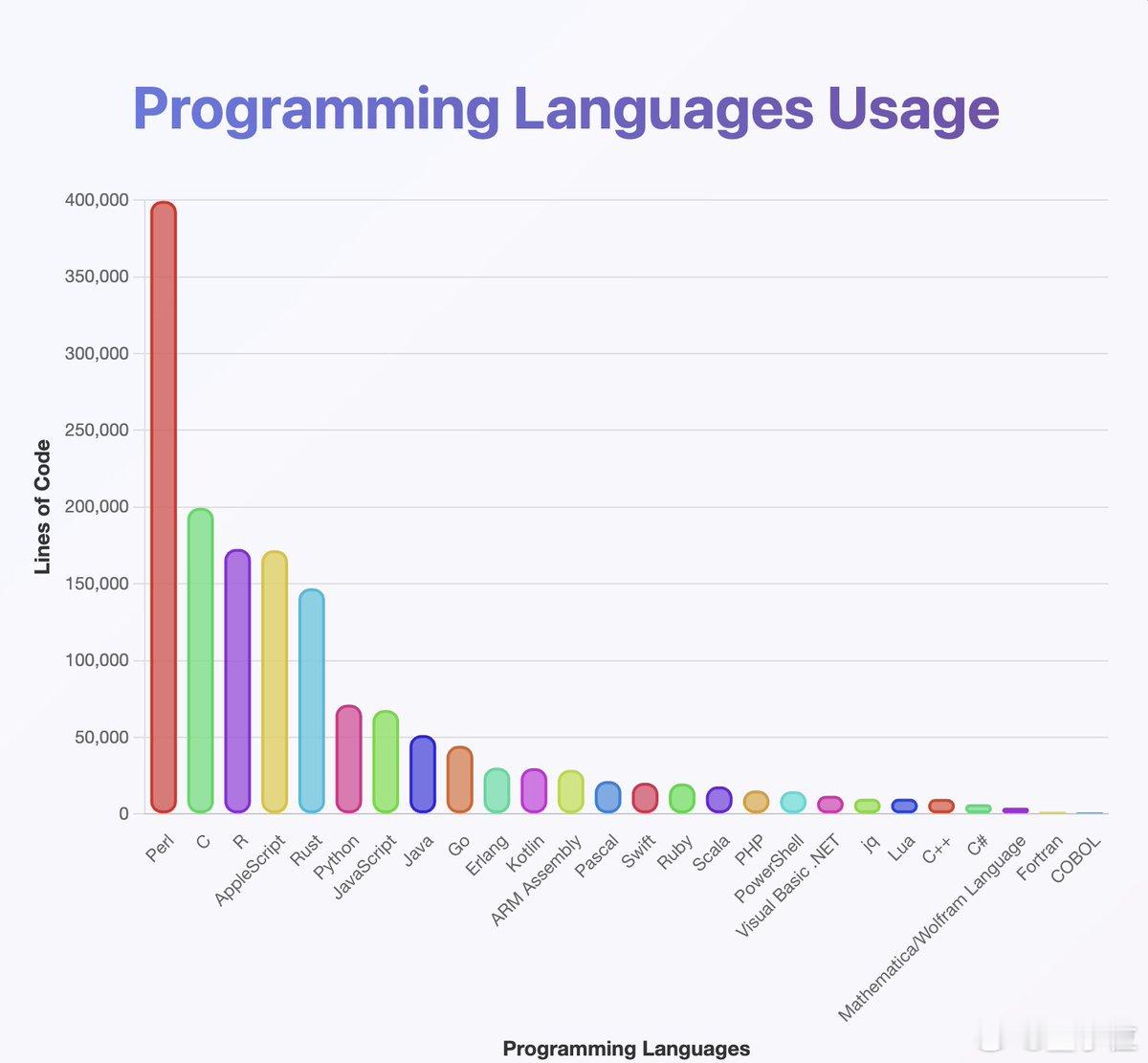
模型表现三:编程语言分布异常
在生成的代码内容中,Perl语言的占比高达近40万行,远远超过C、AppleScript、R、Rust、Python等常见语言【图3】,而Java和Kotlin反而靠后。
Jack推测,这种异常可能来自训练数据本身的语言分布不均,或是语言识别分类器出现偏差。
模型表现四:多语种混用且切换频繁
在推理类长文本中,模型常以英文开头,随后无预警切换至阿拉伯语、俄语、泰语、韩语、中文、乌克兰语等语言,有时又切回英文,有时则完全停留在外语状态【图4】【图5】。
博主提出三种可能解释:
1)强化学习(RL,Reinforcement Learning)训练导致长文本分布偏移;
2)训练数据中存在OCR识别错误或合成数据污染;
3)文本长度超出模型分布控制范围,进入“生成失真”区间。
支持第二种解释的证据包括:模型多次生成包含“OCRV ROOT”等异常字符串的内容【图6】,并伴随中英混合的马来西亚听障人口统计信息,以及嵌入的阿拉伯语翻译。
Jack认为,这可能源于训练集中包含被扫描书籍、报告或OCR处理文档,其中部分主题被模型“记死”,以致无关提示也会被强行激活。
模型表现五:偶尔生成非推理类创意内容
尽管模型主要输出集中在数学和编程任务,但也存在极少量的创意型内容,如故事片段、描述性段落等。这些内容在Embedding图中呈现为稀疏、孤立的小簇。
Jack推测,这类内容反映了训练数据中极小比例的非推理类文本影响。
Jack Morris已将完整分析数据集上传至Hugging Face,并计划进一步探索如何从模型中提取训练数据。
他的总体判断是:gpt-oss更像是一台专门为数学和编程任务优化的“解题机器”,在推理领域表现出高度专注,但在日常对话、自然语言生成方面能力较弱。
数据测试地址:huggingface.co/datasets/jxm/gpt-oss20b-samples