刚刚,谷歌正式发布了Gemini 3。
从今天起,Gemini 3 Pro 已在全球范围内向 Gemini App 和 Google AI Studio 用户推送。甚至在正式官宣之前,谷歌已经悄悄把模型提前上线。
作为谷歌迄今最强的一代基础模型,Gemini 3 在推理、多模态、工具使用等核心维度上全面超越了 2.5 和 2.0 系列,也被谷歌内部定义为一次“代际升级”。就连奥特曼在看到相关案例展示时,都忍不住点了赞。
那么,Gemini 3 的实力究竟如何?下面我们结合谷歌发布的技术细节和实际案例,一起来拆解。
/ 01 /
跑分更猛了,推理能力是亮点
Gemini 3 Pro 的核心变化,是推理能力的全面上升。谷歌在Gemini 3发布时反复强调一句话:这一代模型“能把任何想法变成现实”。
夸张成分先放在一边,从各类基准看,它的确在关键维度上拉开了与2.5 Pro 的差距。
最能体现整体实力的LMArena 排行榜里,它拿到 1501 分,排在第一。这种 Elo 式评分既考模型在开放问答里的稳定性,也考它在长对话和任务拆解中的一致性,从结果看,Gemini 3 Pro 的表现明显更“稳”了,也更擅长把复杂问题讲清楚。
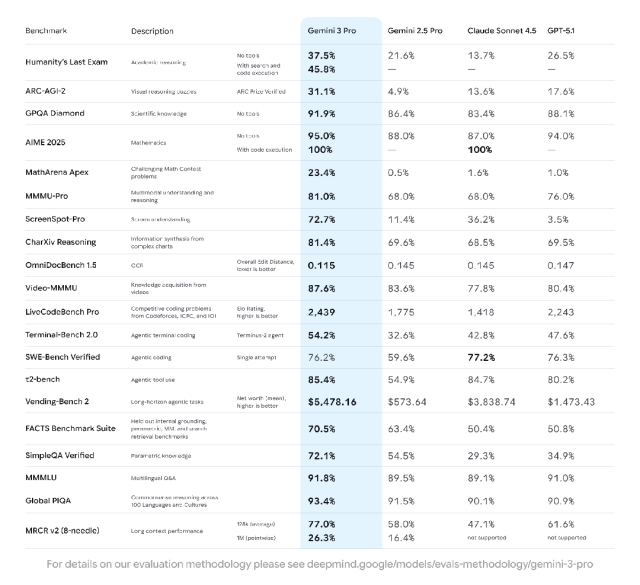
▲Gemini 3系列的推理模式在多项高难度AI基准测试中成绩突出
在衡量思维深度的两个基准上,它同样给出更具有象征意义的成绩。Humanity’s Last Exam 与 GPQA 都不考知识,而是看模型能不能在没有工具的情况下推理出正确结论。
Gemini 3 Pro 在这两项上分别达到 37.5% 和 91.9%,已经接近博士研究级别。
这次谷歌也跟进了类似o1 的Deep Think(深度思考)模式。Gemini 3 Deep Think 会花更多时间去推理,专门解决那种需要剥丝抽茧的复杂问题。
这个技术让它在真正困难的任务上出现了非线性跃迁:在Humanity’s Last Exam上取得41.0%的成绩,在GPQA Diamond上达到93.8%,在ARC-AGI-2里拿到45.1%。这些都是最考模型创造性与新颖推理的任务。
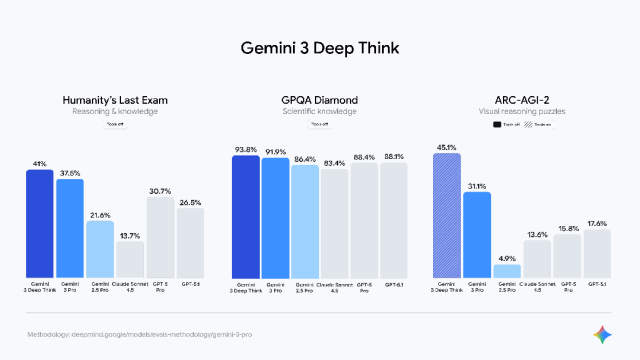
随着谷歌同步推出的Deep Think 模式打开“慢思考”,这些数字进一步上升:GPQA 升到 93.8%,ARC-AGI-2 第一次冲到45.1%。
ARC的特点是不给先验、不给模板,让模型从头找规律,因此被视为测试“通用智能苗头”的指标。通常超过 30% 就被认为出现结构性提升,而 Gemini 3 已经逼近 50%。
数学依然是衡量模型推理真实性的那道最硬门槛。在MathArena Apex 中,Gemini 3 得到 23.4%。
虽然数字不高,却是目前所有模型中最好的,数学推理既难以靠记忆补齐,也难以通过堆数据提升,能把分数抬上去往往意味着模型内部结构发生了变化。
多模态方面,它在MMMU-Pro 和 Video-MMMU 上分别拿到 81% 和 87.6%,这组数据的重要性在于,它证明模型不只是“看见”图像和视频,而是能够从中抽象出结构和因果关系。
Google展示了一个很有趣的用法:做一个等离子体流在托卡马克里的可视化展现,同时用一首诗来捕捉核聚变的美。
以下视频来源于
谷歌黑板报
▲一个有趣的用例,用Gemini 3系列编写托卡马克离子体流动的可视化编程,并写一首捕捉聚变物理的诗歌
事实一致性上,SimpleQA Verified 的 72.1% 则显示它“胡编”的情况减少了。这项指标对任何需要大规模商用的产品都至关重要,因为它直接代表模型是否值得信任。
代码能力是Gemini 3 的另一条增长曲线。它在 WebDev Arena 上拿到 1487 Elo,在 Terminal-Bench 2.0 中达到 54.2%,意味着它不仅能写代码段,还能通过终端调用工具、运行程序,形成一个完整的执行链条。
在 SWE-bench Verified 上的 76.2% 则让它在修复真实代码问题时,比2.5 Pro稳定得多。
综合来看,Gemini 3 的变化并不是“某一项能力突然变强”,而是推理、工具使用、多模态理解、事实一致性几个关键维度同步上扬。
同时,Deep Think的加入,让它第一次具备了可以“沉下去思考”的能力。对谷歌来说,这意味着模型开始具备解决全新问题的基础,而不是只在过去熟悉的轨道里提升分数。
/ 02 /
从生成式界面到自动写代码,Gemini 3到底有多能打?
测试成绩之外Gemini 3 在实际场景中的表现更能说明问题。
根据谷歌发布的一系列Gemini 3 案例,展示了模型能力已经从“能回答问题”,走向“能处理真实任务”。
例如,它可以识别并翻译手写的家族菜谱,也能读懂学术论文和长视频讲座,自动生成结构化的学习卡片。甚至,用户上传一段打球的比赛视频,它也能分析动作、识别弱点,再给出一套可执行的训练计划。
真正的变化发生在搜索端。Gemini 3首次引入“生成式界面”,让搜索结果从过去的文本和链接,变成现场生成的可视化工具。
简单来说,现在用一句话,就能让Gemini 做出高质量的交互式 SVG。
比如,当你搜索“RNA 聚合酶是如何工作的”,传统搜索会给你十几个网页,生成式 AI 只能给你一段解释,而 Gemini 3 会直接做出一个可旋转、可放大的 3D 分子模型,步骤演示以动画形式呈现,你还能拖着看每个结构在起什么作用。
▲以RNA聚合酶为例,演示搜索AI模式下生成式界面是如何工作的
再比如,下面这个在X 上很火的“电风扇”,不仅图像精美,而且还能动、能交互,完全到了可以直接拿来用的程度。
整个体验像是一个为你的问题临时搭建的定制网页,理解效率远高于翻百科。
另一项变化来自开发工具。谷歌发布了全新的AI IDE——Google Antigravity。
过去的AI 辅助开发工具大多停留在补全、解释、改 Bug 的层面,而在 Gemini 3 之后,智能体开始成为一个真正能“自己做项目”的合作伙伴。
▲在AI Studio里从零编写一款画面更精细、交互更丰富的复古3D飞船游戏,而不需要人工介入
内置的Agent 能规划并执行完整的软件任务链条,从查资料、写代码到测试验证都能自动完成。谷歌将推理、工具调用、代码生成能力深度整合,并接入了 Gemini 2.5 的电脑控制模型和图像处理模型,构成一个能够独立跑通任务的执行系统。它也能分析动作、识别弱点,再给出一套可执行的训练计划。
从Gemini 2 开始,谷歌就把“模型能不能自己做事”作为核心方向。Gemini 3 在这一点上更稳,也更能“坚持做完一件事”。
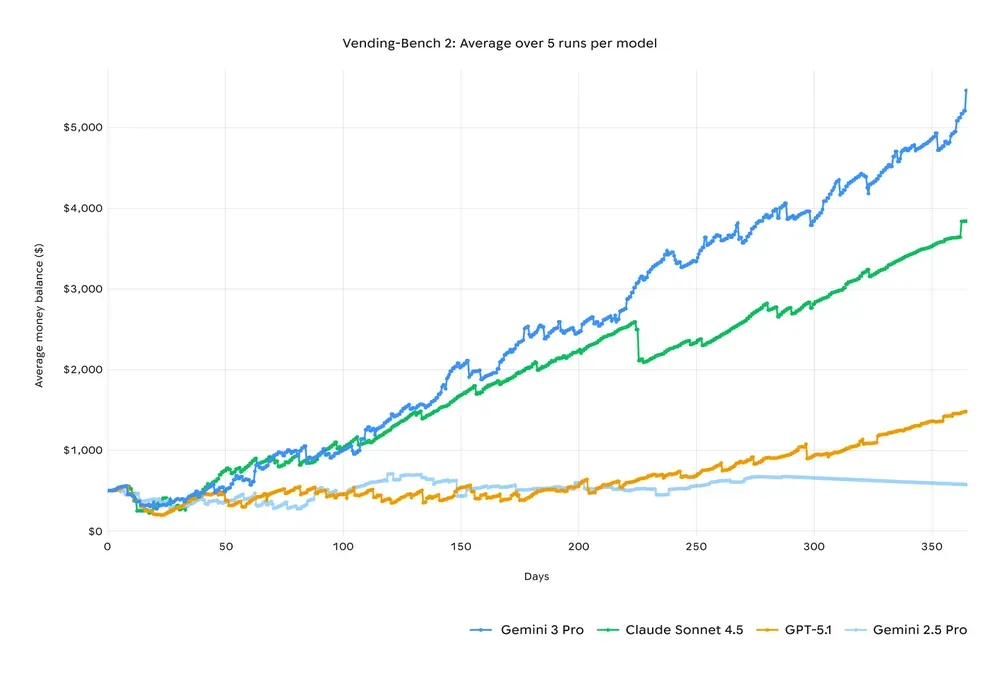
▲与其他主流模型相比,Gemini 3 Pro的长程规划能力更强,任务完成度更高
验证这一能力的是一个叫Vending-Bench 2 的测试,它要求模型经营一家虚拟自动售货机,全年 365 天,每天都有不同的变量和外部条件。
Gemini 3 Pro 在这项测试里排在前列,表现出罕见的一致性:工具调用稳定,不会在决策链条中途走神,也不会忘记长期目标,因此最终收益更高。
从这些演示和公开信息中,很难不注意到一个事实:谷歌在Gemini 3 上几乎动用了所有可以动用的资源。自研 TPU 带来的算力成本优势,手中数量级差异巨大的专有数据,长期投入的大规模训练工程,以及行业最厚实的人才储备,这些“底层力量”叠加在一起,塑造了 Gemini 3 在各类主流基准上的统治性表现,也自然延伸到实际产品形态中。
Gemini 3 所展示的能力差距,既来自模型本身,也来自谷歌在基础设施与技术栈上的系统性优势。它让谷歌在这阶段的领先位置被进一步巩固,而其他公司能否在未来周期里追上这一节奏,让我们拭目以待。
文/朗朗
