AI火了,带火了“买铲子”的数据标注生意。
Scale AI估值冲到200多亿美元,Surge AI也在谈一轮10亿美元融资。巨头们抢模型,资本们抢数据,只要能产出高质量训练数据,就是“印钞机”。
就在这样疯狂的背景下,一位19岁的华裔少女Serena Ge,带着一个只有10个人的小团队,拿到了1500万美元(约1亿人民币)。
Datacurve的投资人里除了Chemistry VC、YC,甚至还包括了来自DeepMind、Anthropic、OpenAI的工程师。
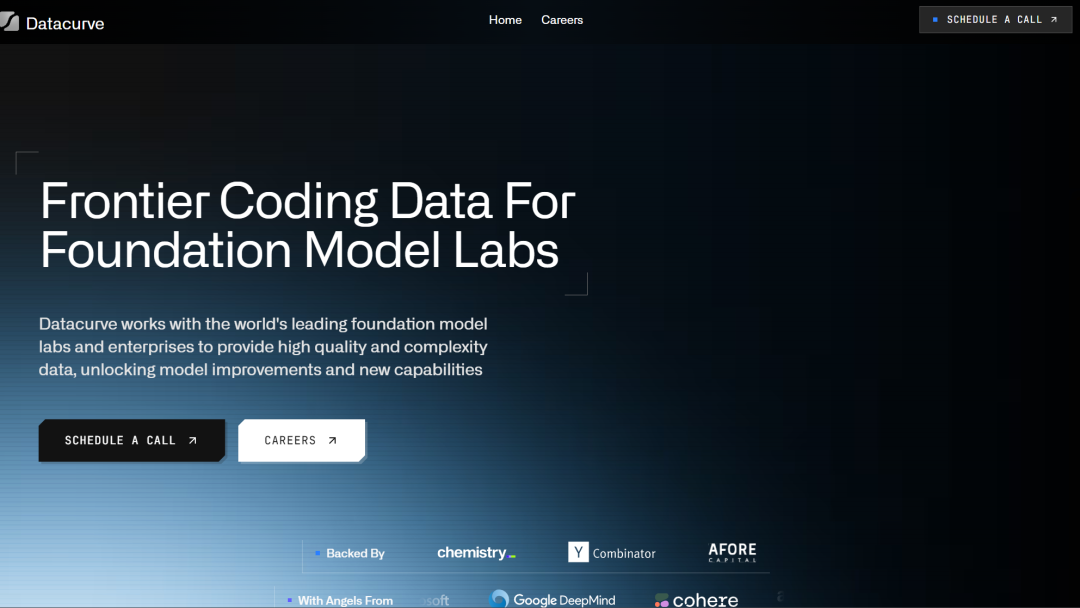
他们看好Datacurve的原因很简单,这家公司做了一件听上去不可思议的事情,把高质量数据标注,做成了一款赏金猎人的游戏。
Datacurve搭建了一个叫Shipd的平台,把算法题、调试任务、代码理解、测试用例等中高难度的工程挑战,通通包成一条条“任务关卡”(Quests)。价格明码标,工程师通关即可拿钱。
在短期几个月时间里,就有1.6万名工程师涌入Shipd。成立两个月,Datacurve的收入就突破100万美元,并迅速成为Cohere、Anthropic的数据供应商。
今天,我们就来说说这家神奇的AI公司。
/ 01 /
数据标注的“赏金猎人”来了
今年以来,业内一个越来越明确的共识是:
限制大模型继续往前走的,不再是算力,而是高质量数据。
在代码、法律、医疗这些高度专业化的领域,“标注”早已不是机械劳动,而变成了一项需要专业知识、结构化能力和推理判断的脑力活。
数据质量直接决定模型的能力上限,这一点正在被更清晰地看见。
尤其是能提供高质量数据的创业公司,越来越火了。据彭博社报道,今年7月Surge AI就正在进行一轮10亿美元的融资,估值高达150~250亿美元。
他们做的事情很简单,就是雇佣了一大批律师、医生、多语种专家,来做垂直领域的高质量数据标注。
但当行业继续往前看时,一个更难补齐的空白开始显露:软件工程的数据需求,几乎没有被满足。
模型要真正理解编程,不只是理解语法或补全代码,而是要掌握工程师的“思考过程”:为什么这样写?为什么要重构?一次代码审查是怎么判断风险的?一个bug是如何定位的?
这些数据天然稀缺,也极难人工合成,更无法靠大规模外包来生产。它需要真实的工程师、真实的推理和真实的判断。
在这样背景下,Datacurve就出现了。
作为一家专门提供高质量编程数据的数据标注公司,真正让它与行业里其他数据标注公司区分开来的,是其独特的运作方式。
很多人以为,“数据标注”是低门槛工作。但在AI训练的高端赛道中,这件事对人的要求极高。
就拿以专业著称的Surge AI来说,它招聘宪法律师的标准,曾在最高法院、美国司法部任职,或顶级律所的前合伙人;医学任务需要能做同行评议、具备临床推理能力的医学研究员;多语言任务则需要全球稀缺的“小语种+专业背景”人才。
这些人报酬自然不低,往往以承包形式参与,律师的时薪甚至能到500–1000美元。
与Surge AI以外包形式找人不同,Datacurve选择了另一条路:把数据标注变成了一场赚赏金的竞赛游戏。
具体来说,他们打造了一个名为Shipd的平台,并在平台上发布包装好的数据任务,任务覆盖了软件工程的关键环节,包括DSA算法题与题解(近似刷题平台LeetCode的题目)、存储库范围代码评估、调试与推理轨迹,以及私有代码库等等。
为了维持数据质量,Datacurve还设计了一套数据验证流程。
工程师完成任务后,AI会先进行自动验证;另一批工程师可以接手代码审查类任务,通过发现缺陷获得奖励;最终结果会经过专家复审。只有互审机制无法判断的细节,最终再由人类专家做最后评价。
这种“解题-审错-复查”的闭环,让平台能在规模化分发任务的同时保持质量。
工程师可以以挑战者的身份自行选择代码任务,每个任务奖励80~100美元不等。干得多,赚得多,不设上限。
例如,用户@James Shi 上线三天,完成四个任务,任务类型包括性能重构、调试、多语言转换等,已经领取132美元奖励。
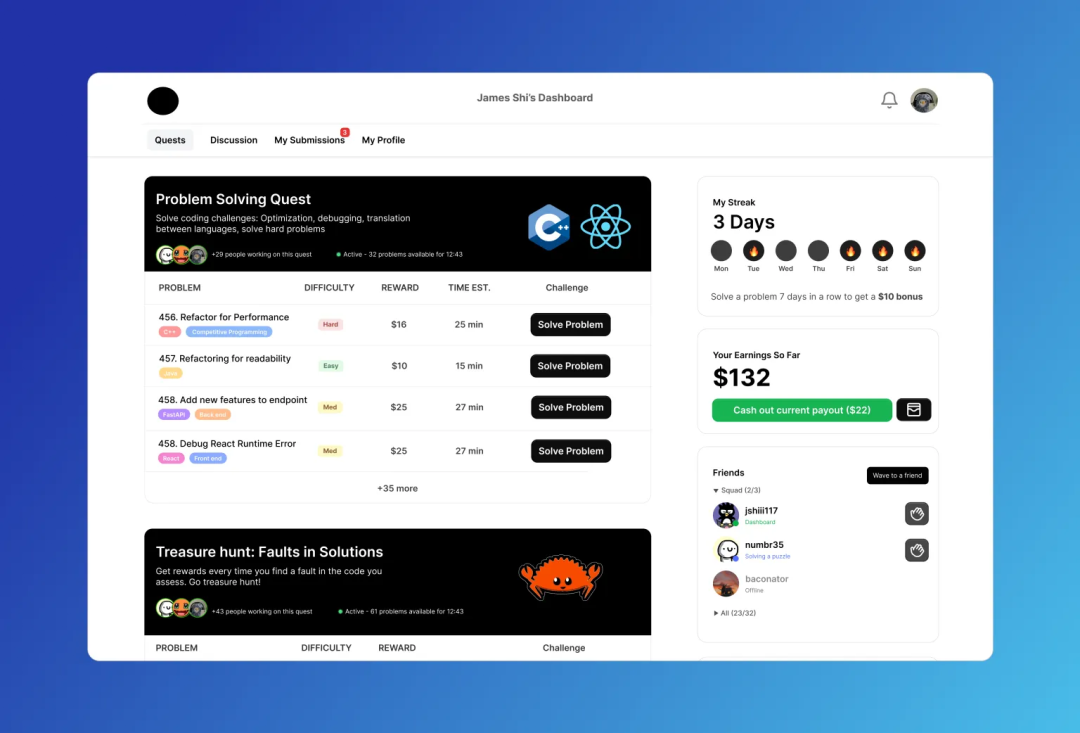
▲用户@James Shi的个人控制台
其官网数据显示,平台已吸引超过1.6万名工程师参与。近期公司披露,平台累计发放的赏金已超过100万美元,部分任务的奖励也被推高至250~350美元。
Shipd之所以能迅速吸引工程师,不只是因为“能赚钱”。更关键的是,它营造了一种接近竞技场的氛围。
在这里,工程师的动机不是典型的打工心态,而是挑战、声望和奖励。他们更像在平台中游走的“赏金猎人”。
来自Amazon、AMD、DeepMind、OpenAI、Anthropic、Vercel等公司的从业者,以及算法竞赛选手和CS学生,都在这里做任务、晒成绩、组队和社交。
也正因为有这样的结构化工程数据,Datacurve在成立仅两个月时,收入便突破百万美元,并迅速成为Cohere、Anthropic等模型公司的数据供应商。
Chemistry VC合伙人Mark Goldberg称它是他“投过增长最快的初创公司之一”,并透露公司在融资期间刚刚签下“史上最大的一笔合同”。
/ 02 /
把数据标注,当成消费产品来做
回头看,Datacurve的真正特殊性在于,它找到了一个更轻、也更容易规模化的数据生产方式:
把数据标注当成一款“面向工程师的消费级产品”来做。
Datacurve团队规模不到10人,却能驱动一个超过万名工程师的社区。这种强烈不对称的组织结构,是它与传统外包型数据公司的最大差异:后者依赖线性扩张的人力体系,而Datacurve用的是互联网平台逻辑。
公司联合创始人Serena Ge把这种方式形容为“让数据生产变成一种消费体验”。许多工程师在Shipd上花的时间,本质上是从游戏、开源社区和刷题练习中迁移过来。
他们不把自己视为标注者,而是把Shipd当成一个“技能竞技场”——在这里挑战任务、积累声望、赢奖励。
Datacurve更像一套能够自我生长的系统:任务拆解、验证、评分和复审被流水线化,大部分质量监控由算法完成,而工程师则在激励机制的驱动下自发承担审核环节。
平台的边际成本因此极低,扩张速度也不再依赖线性增长的人力,是一种典型的“高倍数平台模型”。
另一个明显的差异是,它重新定义了“贡献者”的角色。在多数数据公司,标注者是外包劳动力;在Datacurve,他们是平台的用户。
工程师进入Shipd,并不是为了执行琐碎的重复劳动,而是以挑战者身份参与算法、调试、推理等高难度任务。能拿钱确实很重要,不过“解决问题带来的成就感”与“社区声望”是更强的黏性来源。
Datacurve成立仅一年就完成种子轮(270万美元)与A轮(1500万美元),总融资1770万美元。
虽然规模很小,但是胜在速度。
投资阵容包括Chemistry VC、YC等知名机构,以及多位来自DeepMind、OpenAI、Anthropic等AI巨头的高管以个人身份参与投资。

▲Datacurve联合创始人,Serena Ge(左)和人Charley Lee(右)
投资人看中的不是一个新的数据外包公司,而是一个有机会填补“专家数据缺口”的平台型产品。
Datacurve的扩张不依赖人力堆叠,而是更像互联网产品那样具备指数级增长的可能性。它更像是一种新型基础设施:一个能够持续吸引高水平专业人士,并将他们的思维过程沉淀为可复用数据资产的系统。
随着越来越多AI实验室意识到:模型性能的提升,不再取决于算力,而在于是否能持续获得高质量人类推理,这种“平台化的专家网络”显得愈发稀缺。
Datacurve想回答的问题也由此从“如何收集数据”,进一步走向一个更大的命题:
如果数据变成智能时代重要的生产要素之一,那么工程师社区与数据基础设施能否融合成一套全新的工业系统?
文/朗朗
